Tuesday, March 30th 2021

Arm Announces ARMv9 Architecture With a Focus on AI & Security
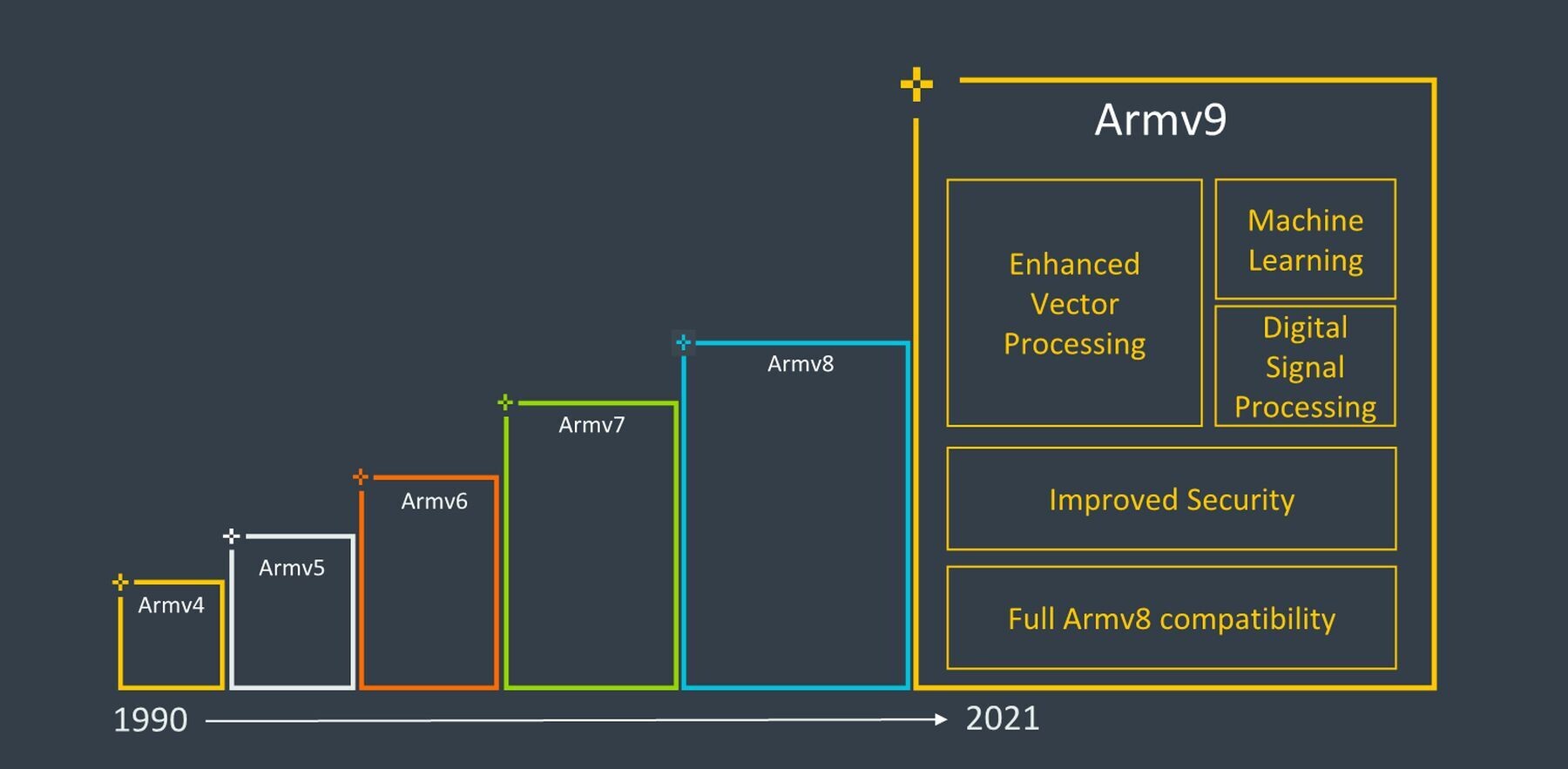
Today, Arm introduced the Armv9 architecture in response to the global demand for ubiquitous specialized processing with increasingly capable security and artificial intelligence (AI). Armv9 is the first new Arm architecture in a decade, building on the success of Armv8 which today drives the best performance-per-watt everywhere computing happens.
To address the greatest technology challenge today - securing the world's data - the Armv9 roadmap introduces the Arm Confidential Compute Architecture (CCA). Confidential computing shields portions of code and data from access or modification while in-use, even from privileged software, by performing computation in a hardware-based secure environment.
 AI everywhere demands specialized, scalable solutions
AI everywhere demands specialized, scalable solutions
The ubiquity and range of AI workloads demands more diverse and specialized solutions. For example, it is estimated there will be more than eight billion AI-enabled voice-assisted devices in use by the mid-2020s, and 90 percent or more of on-device applications will contain AI elements along with AI-based interfaces like vision or voice.
To address this need, Arm partnered with Fujitsu to create the Scalable Vector Extension (SVE) technology, which is at the heart of Fugaku, the world's fastest supercomputer. Building on that work, Arm has developed SVE2 for Armv9 to enable enhanced machine learning (ML) and digital signal processing (DSP) capabilities across a wider range of applications.
SVE2 enhances the processing ability of 5G systems, virtual and augmented reality, and ML workloads running locally on CPUs, such as image processing and smart home applications. Over the next few years, Arm will further extend the AI capabilities of its technology with substantial enhancements in matrix multiplication within the CPU, in addition to ongoing AI innovations in its Mali GPUs and Ethos NPUs.
Maximizing performance through system design
Over the past five years, Arm designs have increased CPU performance annually at a rate that outpaces the industry. Arm will continue this momentum into the Armv9 generation with expected CPU performance increases of more than 30% over the next two generations of mobile and infrastructure CPUs.
However, as the industry moves from general-purpose computing towards ubiquitous specialized processing, annual double-digit CPU performance gains are not enough. Along with enhancing specialized processing, Arm's Total Compute design methodology will accelerate overall compute performance through focused system-level hardware and software optimizations and increases in use-case performance.
By applying Total Compute design principles across its entire IP portfolio of automotive, client, infrastructure and IoT solutions, Armv9 system-level technologies will span the entire IP solution, as well as improving individual IP. Additionally, Arm is developing several technologies to increase frequency, bandwidth, and cache size, and reduce memory latency to maximize the performance of Armv9-based CPUs.
Source:
Arm
To address the greatest technology challenge today - securing the world's data - the Armv9 roadmap introduces the Arm Confidential Compute Architecture (CCA). Confidential computing shields portions of code and data from access or modification while in-use, even from privileged software, by performing computation in a hardware-based secure environment.

The ubiquity and range of AI workloads demands more diverse and specialized solutions. For example, it is estimated there will be more than eight billion AI-enabled voice-assisted devices in use by the mid-2020s, and 90 percent or more of on-device applications will contain AI elements along with AI-based interfaces like vision or voice.
To address this need, Arm partnered with Fujitsu to create the Scalable Vector Extension (SVE) technology, which is at the heart of Fugaku, the world's fastest supercomputer. Building on that work, Arm has developed SVE2 for Armv9 to enable enhanced machine learning (ML) and digital signal processing (DSP) capabilities across a wider range of applications.
SVE2 enhances the processing ability of 5G systems, virtual and augmented reality, and ML workloads running locally on CPUs, such as image processing and smart home applications. Over the next few years, Arm will further extend the AI capabilities of its technology with substantial enhancements in matrix multiplication within the CPU, in addition to ongoing AI innovations in its Mali GPUs and Ethos NPUs.
Maximizing performance through system design
Over the past five years, Arm designs have increased CPU performance annually at a rate that outpaces the industry. Arm will continue this momentum into the Armv9 generation with expected CPU performance increases of more than 30% over the next two generations of mobile and infrastructure CPUs.
However, as the industry moves from general-purpose computing towards ubiquitous specialized processing, annual double-digit CPU performance gains are not enough. Along with enhancing specialized processing, Arm's Total Compute design methodology will accelerate overall compute performance through focused system-level hardware and software optimizations and increases in use-case performance.
By applying Total Compute design principles across its entire IP portfolio of automotive, client, infrastructure and IoT solutions, Armv9 system-level technologies will span the entire IP solution, as well as improving individual IP. Additionally, Arm is developing several technologies to increase frequency, bandwidth, and cache size, and reduce memory latency to maximize the performance of Armv9-based CPUs.
10 Comments on Arm Announces ARMv9 Architecture With a Focus on AI & Security
As stated in the press release, ARM is focusing even more on specialized processing, while x86 is focusing on general-purpose performance.
In general-purpose performance, any CPU will ultimately scale towards cache misses. Thanks to more advanced instructions, x86 will have fewer of these, and hence scale better with loads with branching logic. The only way to beat x86 on this would be to introduce similar advanced instructions, which would make ARM more CISC, or invent a new "paradigm". But that's not the focus of ARM, it's a basic energy efficient design intended for customization, and ARM devices which "outperforms" x86 does this thanks to specialized instructions and software.
One interesting related subject is that AMD were claiming that ARM were the future back in ~2012-2013, and were planning to launch their ARMv8 K12 design in 2017, and Zen was intended as the "stop-gap" before going all-in on ARM. Now K12 is nowhere to be seen and is already obsolete, and AMD plans to make at least five iterations of Zen. So it seems like the realities settled in about the performance of ARM.
*kringe*
source: www.gurufocus.com/news/1385018/is-nvidias-pending-arm-holdings-acquisition-a-good-deal
seekingalpha.com/article/4398948-nvidia-arm-deal-will-likely-be-shot-down