Thursday, August 10th 2023
Atlas Fallen Optimization Fail: Gain 50% Additional Performance by Turning off the E-cores
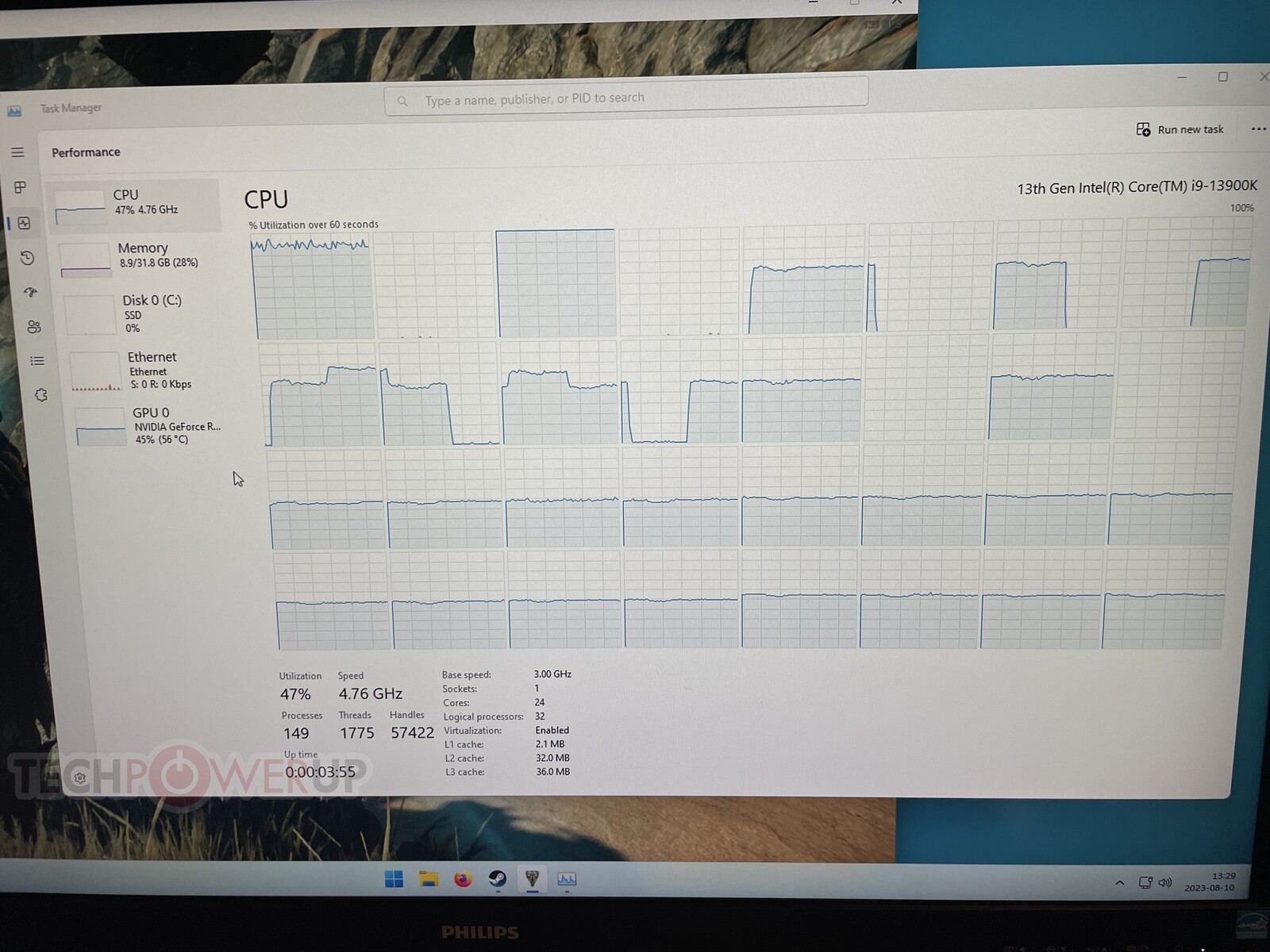
Action RPG "Atlas Fallen" joins a long line of RPGs this Summer for you to grind into—Baldur's Gate 3, Diablo 4, and Starfield. We've been testing the game for our GPU performance article, and found something interesting—the game isn't optimized for Intel Hybrid processors, such as the Core i9-13900K "Raptor Lake" in our bench. The game scales across all CPU cores—which is normally a good thing—until we realize that not only does it saturate all of the 8 P-cores, but also the 16 E-cores. It ends up with under 80 FPS in busy gameplay at 1080p with a GeForce RTX 4090. Performance is "restored" only when the E-cores are disabled.
Normally, when a game saturates all of the E-cores, we don't interpret it as the game being "aware" of E-cores, but rather "unaware" of them. An ideal Hybrid-aware game should saturate the P-cores for its main workload, and use the E-cores for errands such as processing the audio stack (DSPs from the game), network stack (the game's unique multiplayer network component), physics, in-flight decompression of assets from the disk, etc., which show up in Task Manager as intermittent, irregular load. "Atlas Fallen" appears to be using the E-cores for its main worker threads, and this is found imposing a performance penalty as we found out by disabling the E-cores. This performance penalty is because the E-cores run slower than P-cores, at lower clock speeds, have much lower IPC, and are cache-starved. Frame data being processed by the P-cores end up having to wait for those from the E-cores, which causes the overall framerate to come down.



 In the Task Manager screenshot above, the game is running in the foreground, we set Task Manager to be "always on top," so Thread Director won't interfere with the game. It prefers to allocate the P-cores to foreground tasks, which doesn't happen here, because the developers chose to specifically put work on the E-Cores.
In the Task Manager screenshot above, the game is running in the foreground, we set Task Manager to be "always on top," so Thread Director won't interfere with the game. It prefers to allocate the P-cores to foreground tasks, which doesn't happen here, because the developers chose to specifically put work on the E-Cores.
For comparison we took four screenshots, with E-Cores enabled and disabled (through BIOS). We picked a "typical average" scene instead of a worst case, which is why the FPS are a bit higher. As you can see, with E-Cores enabled are pretty low (136 / 152 FPS), whereas turning off the E-Cores instantly increases performance right up to the engine's internal FPS cap (187 / 197 FPS).
With the E-cores disabled, the game is confined to what is essentially an 8-core/16-thread processor with just P-cores, which boost well above the 5.00 GHz mark, and have the full 36 MB slab of L3 cache to themselves. The framerate now shoots up to 200 FPS, which is a hard framerate limit set by the developer. Our RTX 4090 should be capable of higher framerates, and developers Deck13 Interactive should consider raising it, given that monitor refresh-rates are on the rise, and it's fairly easy to find a 240 Hz or 360 Hz monitor in the high-end segment. The game is based on the Fledge engine, and supports both DirectX 12 and Vulkan APIs. We used GeForce 536.99 WHQL in our testing. Be sure to check out our full performance review of Atlas Fallen later today.
Normally, when a game saturates all of the E-cores, we don't interpret it as the game being "aware" of E-cores, but rather "unaware" of them. An ideal Hybrid-aware game should saturate the P-cores for its main workload, and use the E-cores for errands such as processing the audio stack (DSPs from the game), network stack (the game's unique multiplayer network component), physics, in-flight decompression of assets from the disk, etc., which show up in Task Manager as intermittent, irregular load. "Atlas Fallen" appears to be using the E-cores for its main worker threads, and this is found imposing a performance penalty as we found out by disabling the E-cores. This performance penalty is because the E-cores run slower than P-cores, at lower clock speeds, have much lower IPC, and are cache-starved. Frame data being processed by the P-cores end up having to wait for those from the E-cores, which causes the overall framerate to come down.
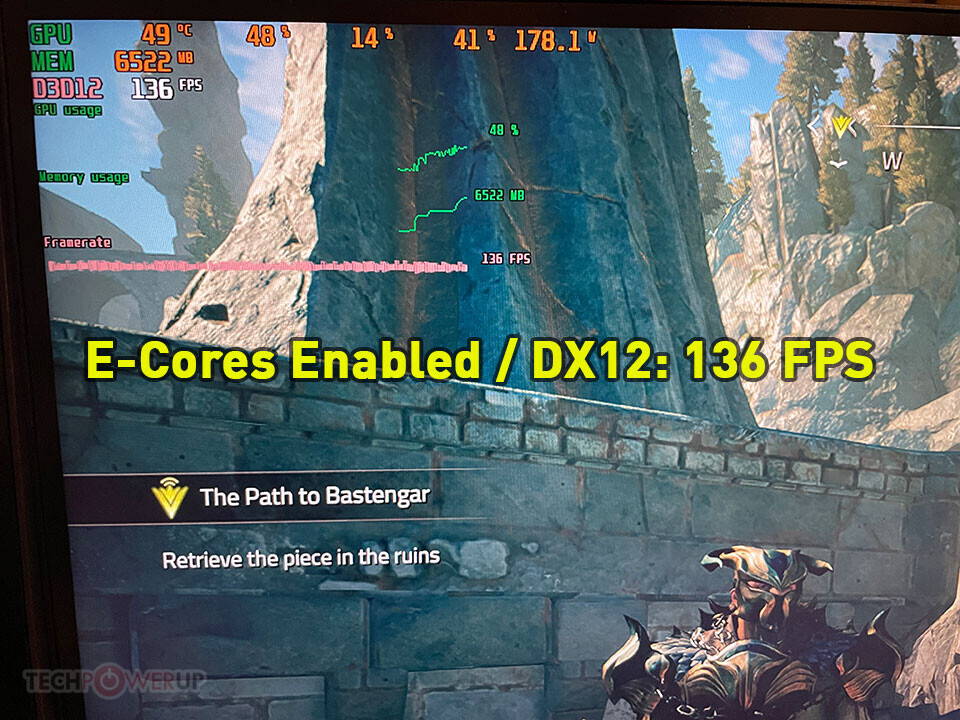


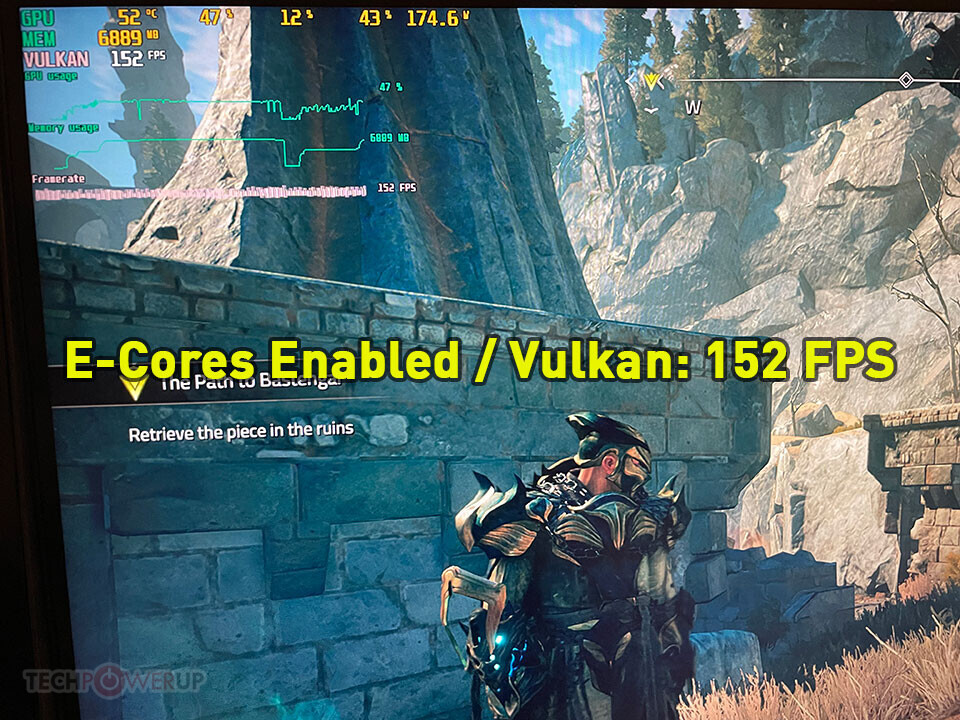
For comparison we took four screenshots, with E-Cores enabled and disabled (through BIOS). We picked a "typical average" scene instead of a worst case, which is why the FPS are a bit higher. As you can see, with E-Cores enabled are pretty low (136 / 152 FPS), whereas turning off the E-Cores instantly increases performance right up to the engine's internal FPS cap (187 / 197 FPS).
With the E-cores disabled, the game is confined to what is essentially an 8-core/16-thread processor with just P-cores, which boost well above the 5.00 GHz mark, and have the full 36 MB slab of L3 cache to themselves. The framerate now shoots up to 200 FPS, which is a hard framerate limit set by the developer. Our RTX 4090 should be capable of higher framerates, and developers Deck13 Interactive should consider raising it, given that monitor refresh-rates are on the rise, and it's fairly easy to find a 240 Hz or 360 Hz monitor in the high-end segment. The game is based on the Fledge engine, and supports both DirectX 12 and Vulkan APIs. We used GeForce 536.99 WHQL in our testing. Be sure to check out our full performance review of Atlas Fallen later today.
120 Comments on Atlas Fallen Optimization Fail: Gain 50% Additional Performance by Turning off the E-cores
So for parallel programming, you only spawn new threads when you have large-ish chunks of work for each thread, otherwise you'll risk taking longer than just using one thread.
Apple's ARM processors are efficient, but probably more because of TSMC's N5 node than because of ARM or E-cores.
Pretty sure Microsoft started doing that and it's pretty much standard now.
Now imagine what would happen if there were far fewer chunks, specifically exactly as many chunks as there are threads. Each P-core would rapidly finish its single chunk then sit waiting while the E-cores finish theirs.
This is very likely the problem with this game, the developers naively assumed each thread was equally capable and thus divided the work exactly equally between them. Thus, while they gain some performance from the parallelization, they lose much more performance by not utilizing the (far more performant) P-cores to their fullest.
Zen 4
This table is from part 1 of the Chips and Cheese overview of Zen 4. Notice that Golden Cove, despite the handicaps of higher clock speed and an inferior process, has a ROB size that is much closer to Apple's M2 than Zen 4.
www.techpowerup.com/312237/amd-strix-point-companys-first-hybrid-processor-4p-8e-es-surfaces
:)
Image is edited from the one in the Anandtech article linked above. Notice that the A15's Blizzard E cores are 5 times faster than the A55 in the gcc subtest but consume only 58% more power, making them 3.25x more efficient in terms of performance per Watt. Even the A14's E cores, which consume almost the same power as the A55 in this subtest are 3.75 times faster.
Pity.
That's exactly why certain companies like to use it to show how awesome their product is, because it basically scales infinitely and doesn't rely on the memory subsystem or anything else.
Gaming is pretty much the opposite. To calculate a single frame you need geometry, rendering, physics, sound, AI, world properties and many more, and they are all synchronized (usually), and have to wait on each other, for every single frame. Put the slowest of these workloads on the E-Cores, everything else has to wait. This will not show up in Task Manager on the waiting cores, because the game is doing a busy wait, to reduce latency, at the cost of not freeing up the CPU core to do something else.
I switched to the Ryzen 7800X3D and couldn't be happier.
I heard of some Deneuvo issues but didn't experience them myself. I was honestly expecting problems, but didn't have anything.
I was thinking of going 7950x3d (i need the cores for VM data schlepping) but it honestly didn't feel worth and 7800x3d is awesome but would be a downgrade for work but a small upgrade for gaming at 4k :/
I do have the itch build another personal AMD rig at some point.Apple problem is the software. It's too expensive for cloud stuff, and not enterprise friendly enough for corporate stuff, and doesn't really do any gaming. Even if they have amazing hardware (which they've had for years) - there's only so many hipsters at starbucks who code frontend / do marketing and gfx work and I think they already all use apple.
If they opened up to run games and were better for enterprise (better AD/MDM/MDS integration, and better compatibility with microsoft apps) they would crush it on the consumer side.