Sunday, May 25th 2008

New NVIDIA GeForce GTX280 Three Times Faster than HD 3870 in Folding@Home
Just a couple days ago, we informed you that NVIDIA had joined the Folding@Home team. However, at the time, benchmarks for this new client were unavailable. I am now happy to inform you that (internal) benchmarks are available for your viewing pleasure. The rather large green bar was achieved using the new NVIDIA GPU core, the GTX280. As far as exact numbers go, this sucker can fold at 500 mol/day, which is much higher than the Radeon HD 3870 numbers (170 mol/day), five times higher than PS3 numbers (100 mol/day), and astronomically higher than the average computer numbers (4 mol/day). Whether or not this translates into actual gaming performance is yet to be seen, however, it's pretty hard to imagine how something so powerful wouldn't bring back some respectable FPS in games like Crysis.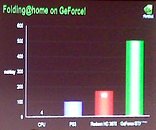
Source:
Nordic Hardware

83 Comments on New NVIDIA GeForce GTX280 Three Times Faster than HD 3870 in Folding@Home
there's differences in WUs as they're intended for specific hardware. A GPU can't run the SMP client, and it would buckle under the work load even if you could; just like a single-core CPU can't efficiently handle SMP workloads, either.
Perhaps nVidia's GPUs will end up with their own specific folding client - which, I figure they probably would seeing as how different their GPU architecture is over ATIs - one that is more optimized for their GPUs?
Not saying that's a bad thing, having seperate GPU clients - but, perhaps nVidia's GPU can only work with simple molecules, which is where they get such an astronomical mol/day figure from . . . it makes sense, IMO.
I guess, really, the only way to see for sure, is when their new GPUs are on the market, and people start folding with them. It'd be interesting to keep an eye on the ppd earned as compared to ATI's cards - if nVidia's are earning fewer ppd as compared to a 3870, then we would know that it's working with less complex WUs.
TBH, I think it's great nVidia have finally decided to work with F@H and get their new GPUs ready to help out with the project. Really, the F@H project has the potential to affect everyone sooner or later, in some shape or form.
I just personally feel this is lacking any sense of tact, though - I really don't think nVidia should be making their new GPUs F@H capability a marketing point to help sell their new hardware; if they've twisted or misrepresented the facts, even more shameful, IMO. There's no point for such points that they are trying to make, when the hardware isn't even here yet to prove what it's truly capable of; and all of us know how the nVidia fanbois will run rampant over these images trying to claim how 1337 the new hardware will be.
IIRC, I can't recall ATI, nor any other hardware manufacturer making radical claims when they joined up - hell, ATI was rather quiet about it.
ATi is great, but nVidia got it right. Some people are just haters.
so yeah, a card thats proably 30% faster
"mols" in that chart isn't a quantity of a single molecule, they meant number of molecules folded / time, where time is constant.
The job F@H does is take a protein molecule and simulate its folding in accordance to the raw data F@H servers provide. After simulation of a protein folding, the parameters of the folded molecule (which differ from that of the original) are sent back to the server. This simulation requires computational power.
I don't think the NVidia graph is exaggerated considering they built the core (F@H core) using NVidia CUDA, and CUDA apps get the most computational power out of both geometry and shader domains of a CUDA-supportive GPU, in this case the fastest NVidia ever made, the GTX 280. There still isn't an IDE that lets you get the most out of ATI's Stream Computing though ATI is working on one.
Leave the proteins for shakes & stakes & give me some framerates :roll:
I think I need to lie dowm after that one :rolleyes:
How many points each unit is worth depends on how long it would take a P4 2.8GHz(Socket 478 Northwood) with SSE2 disabled to complete. Then they plug the number of days it takes that processor to complete the work unit into the formula 110*(Number of Days) and that is your points per WU for CPUs. Now in the case of the SMP client, the same method is used, but then a 50% bonus is given to each WU's score just because it is an SMP WU. Does that mean the work is any more complex? No. Does that mean the multi-core CPUs are doing more work per WU than a single core CPU? No. But they still get more points per WU and hence more PPD than a single core doing the same work.
Now, in terms of GPU folding. The new GPU2 client that runs on the new HD2000 and HD3000 are done the same way. They benchmark each WU on a 3850 and then multiply the number of days it take for the WU to complete by 1000. Why 1000? It is just a number they picked. If they pick a lower number to muptiply by when doing the nVidia calculations or begin the benchmarking process with a weaker GPU, then the PPD vs. ATi cards won't be a good guage on performance.
why dont they fold us a way to get rid of fossil fuels.
Would be nicer to see how the 3870 competes against the G92.
i could cut down alot of things i say to 1-3 sentances, but only a few people would get what i was saying.