Vulkan API Unifies Image Layouts, Waving Goodbye to Sync Issues
In the Vulkan API, image layouts have been granularly controlled by developers, meaning that whenever you use an image in a new way, such as targeting it for transfer, feeding it into a shader, or presenting it on screen, you must explicitly transition it between different layouts. Even one barrier with the wrong layout, access mask, pipeline stage, or ownership transfer can cause race conditions, visual corruption, or GPU hangs. Managing numerous layouts and barriers only adds boilerplate and increases the risk of subtle platform-specific bugs, making it more challenging to port games to multiple platforms. Today, this is no longer the case. The Khronos Group, developers behind the Vulkan API, unveiled the VK_KHR_unified_image_layouts extension, which simplifies synchronization by promoting VK_IMAGE_LAYOUT_GENERAL as the default state for nearly all image operations.
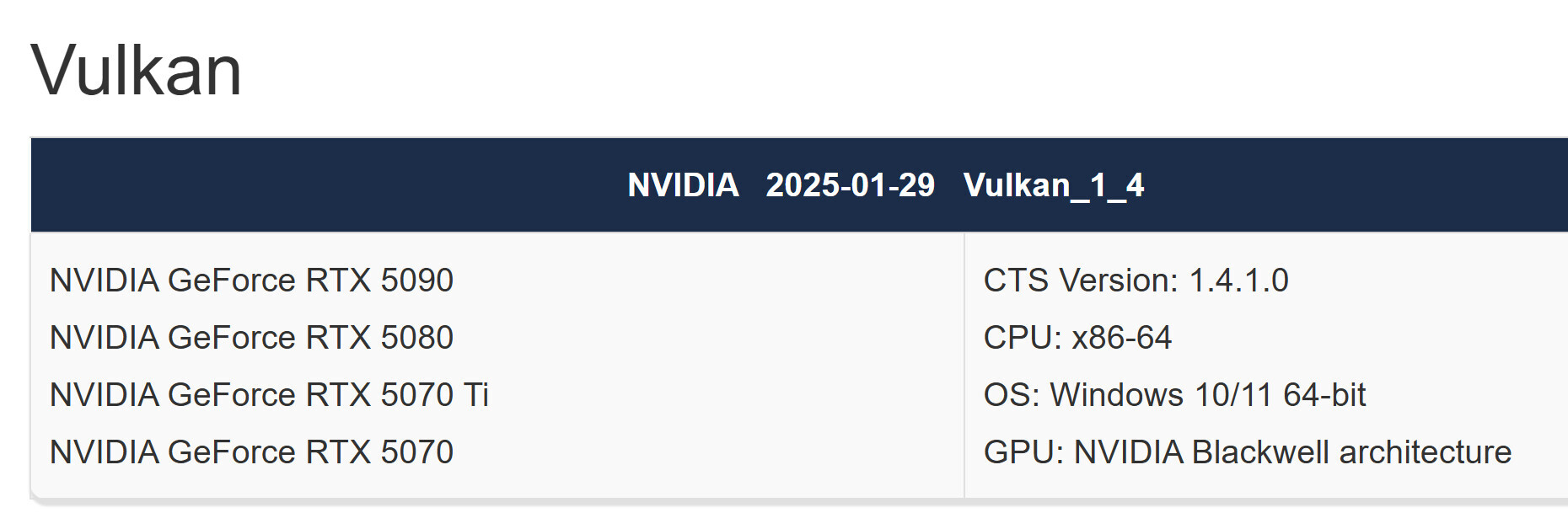
When Vulkan 1.0 launched over a decade ago, its explicit synchronization model required engineers to specify distinct layouts. This included TRANSFER_DST_OPTIMAL, SHADER_READ_ONLY_OPTIMAL, and COLOR_ATTACHMENT_OPTIMAL for each access pattern. This granularity once maximized performance on early GPU hardware but introduced a steep learning curve and frequent bugs. With modern GPUs capable of handling many transitions internally, developers no longer need to juggle multiple layout states. Under the new model, only two scenarios still demand special treatment: initializing new images with VK_IMAGE_LAYOUT_UNDEFINED and sharing or presenting images to external queues or display systems. Now, the new extension collapses the remaining layout types into one versatile state, reduces boilerplate code, lowers the risk of synchronization errors, and minimizes unnecessary pipeline stalls, allowing the GPU to operate more efficiently. Driver support for VK_KHR_unified_image_layouts is already available in the latest GPU releases, with validation-layer integration set for the July 2025 Vulkan SDK.

When Vulkan 1.0 launched over a decade ago, its explicit synchronization model required engineers to specify distinct layouts. This included TRANSFER_DST_OPTIMAL, SHADER_READ_ONLY_OPTIMAL, and COLOR_ATTACHMENT_OPTIMAL for each access pattern. This granularity once maximized performance on early GPU hardware but introduced a steep learning curve and frequent bugs. With modern GPUs capable of handling many transitions internally, developers no longer need to juggle multiple layout states. Under the new model, only two scenarios still demand special treatment: initializing new images with VK_IMAGE_LAYOUT_UNDEFINED and sharing or presenting images to external queues or display systems. Now, the new extension collapses the remaining layout types into one versatile state, reduces boilerplate code, lowers the risk of synchronization errors, and minimizes unnecessary pipeline stalls, allowing the GPU to operate more efficiently. Driver support for VK_KHR_unified_image_layouts is already available in the latest GPU releases, with validation-layer integration set for the July 2025 Vulkan SDK.