Friday, March 21st 2025

AMD Introduces GAIA - an Open-Source Project That Runs Local LLMs on Ryzen AI NPUs
AMD has launched a new open-source project called, GAIA (pronounced /ˈɡaɪ.ə/), an awesome application that leverages the power of Ryzen AI Neural Processing Unit (NPU) to run private and local large language models (LLMs). In this blog, we'll dive into the features and benefits of GAIA, while introducing how you can take advantage of GAIA's open-source project to adopt into your own applications.
Introduction to GAIA
GAIA is a generative AI application designed to run local, private LLMs on Windows PCs and is optimized for AMD Ryzen AI hardware (AMD Ryzen AI 300 Series Processors). This integration allows for faster, more efficient processing - i.e. lower power- while keeping your data local and secure. On Ryzen AI PCs, GAIA interacts with the NPU and iGPU to run models seamlessly by using the open-source Lemonade (LLM-Aid) SDK from ONNX TurnkeyML for LLM inference. GAIA supports a variety of local LLMs optimized to run on Ryzen AI PCs. Popular models like Llama and Phi derivatives can be tailored for different use cases, such as Q&A, summarization, and complex reasoning tasks.
 Getting Started with GAIA
Getting Started with GAIA
To get started with GAIA in under 10 minutes. Follow the instructions to download and install GAIA on your Ryzen AI PC. Once installed, you can launch GAIA and begin exploring its various agents and capabilities. There are 2 versions of GAIA:
One of the standout features of GAIA is its agent Retrieval-Augmented Generation (RAG) pipeline. This pipeline combines an LLM with a knowledge base, enabling the agent to retrieve relevant information, reason, plan, and use external tools within an interactive chat environment. This results in more accurate and contextually aware responses.
The current GAIA agents enable the following capabilities:
How does GAIA Work?
The left side of Figure 2: GAIA Overview Diagram illustrates the functionality of Lemonade SDK from TurnkeyML. Lemonade SDK provides tools for LLM-specific tasks such as prompting, accuracy measurement, and serving across multiple runtimes (e.g., Hugging Face, ONNX Runtime GenAI API) and hardware (CPU, iGPU, and NPU).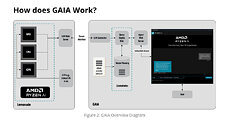
Lemonade exposes an LLM web service that communicates with the GAIA application (on the right) via an OpenAI compatible REST API. GAIA consists of three key components:
Benefits of Running LLMs Locally
Running LLMs locally on the NPU offers several benefits:
Running GAIA on the NPU results in improved performance for AI-specific tasks, as it is designed for inference workloads. Beginning with Ryzen AI Software Release 1.3, there is hybrid support for deploying quantized LLMs that utilize both the NPU and the iGPU. By using both components, each can be applied to the tasks and operations they are optimized for.
Applications and Industries
This setup could benefit industries that require high performance and privacy, such as healthcare, finance, and enterprise applications where data privacy is critical. It can also be applied in fields like content creation and customer service automation, where generative AI models are becoming essential. Lastly, it helps industries without Wi-Fi to send data to the cloud and receive responses, as all the processing is done locally.
Conclusion
In conclusion, GAIA, an open-source AMD application, uses the power of the Ryzen AI NPU to deliver efficient, private, and high-performance LLMs. By running LLMs locally, GAIA ensures enhanced privacy, reduced latency, and optimized performance, making it ideal for industries that prioritize data security and rapid response times.
Ready to try GAIA yourself? Our video provides a brief overview and installation demo of GAIA.
Check out and contribute to the GAIA repo at github.com/amd/gaia. For feedback or questions, please reach out to us at GAIA@amd.com.
Source:
AMD Developer Blog
Introduction to GAIA
GAIA is a generative AI application designed to run local, private LLMs on Windows PCs and is optimized for AMD Ryzen AI hardware (AMD Ryzen AI 300 Series Processors). This integration allows for faster, more efficient processing - i.e. lower power- while keeping your data local and secure. On Ryzen AI PCs, GAIA interacts with the NPU and iGPU to run models seamlessly by using the open-source Lemonade (LLM-Aid) SDK from ONNX TurnkeyML for LLM inference. GAIA supports a variety of local LLMs optimized to run on Ryzen AI PCs. Popular models like Llama and Phi derivatives can be tailored for different use cases, such as Q&A, summarization, and complex reasoning tasks.

To get started with GAIA in under 10 minutes. Follow the instructions to download and install GAIA on your Ryzen AI PC. Once installed, you can launch GAIA and begin exploring its various agents and capabilities. There are 2 versions of GAIA:
- 1) GAIA Installer - this will run on any Windows PC; however, performance may be slower.
- 2) GAIA Hybrid Installer - this package is optimized to run on Ryzen AI PCs and uses the NPU and iGPU for better performance.
One of the standout features of GAIA is its agent Retrieval-Augmented Generation (RAG) pipeline. This pipeline combines an LLM with a knowledge base, enabling the agent to retrieve relevant information, reason, plan, and use external tools within an interactive chat environment. This results in more accurate and contextually aware responses.
The current GAIA agents enable the following capabilities:
- Simple Prompt Completion: No agent for direct model interaction for testing and evaluation.
- Chaty: an LLM chatbot with history that engages in conversation with the user.
- Clip: an Agentic RAG for YouTube search and Q&A agent.
- Joker: a simple joke generator using RAG to bring humor to the user.
How does GAIA Work?
The left side of Figure 2: GAIA Overview Diagram illustrates the functionality of Lemonade SDK from TurnkeyML. Lemonade SDK provides tools for LLM-specific tasks such as prompting, accuracy measurement, and serving across multiple runtimes (e.g., Hugging Face, ONNX Runtime GenAI API) and hardware (CPU, iGPU, and NPU).

- 1) LLM Connector - Bridges the NPU service's Web API with the LlamaIndex-based RAG pipeline.
- 2) LlamaIndex RAG Pipeline - Includes a query engine and vector memory, which processes and stores relevant external information.
- 3) Agent Web Server - Connects to the GAIA UI via WebSocket, enabling user interaction.
- 1) The query is sent to GAIA, where it is transformed into an embedding vector.
- 2) The vectorized query is used to retrieve relevant context from the indexed data.
- 3) The retrieved context is passed to the web service, where it is embedded into the LLM's prompt.
- 4) The LLM generates a response, which is streamed back through the GAIA web service and displayed in the UI.
Benefits of Running LLMs Locally
Running LLMs locally on the NPU offers several benefits:
- Enhanced privacy, as no data needs to leave your machine. This eliminates the need to send sensitive information to the cloud, greatly enhancing data privacy and security while still delivering high-performance AI capabilities.
- Reduced latency, since there's no need to communicate with the cloud.
- Optimized performance with the NPU, leading to faster response times and lower power consumption.
Running GAIA on the NPU results in improved performance for AI-specific tasks, as it is designed for inference workloads. Beginning with Ryzen AI Software Release 1.3, there is hybrid support for deploying quantized LLMs that utilize both the NPU and the iGPU. By using both components, each can be applied to the tasks and operations they are optimized for.
Applications and Industries
This setup could benefit industries that require high performance and privacy, such as healthcare, finance, and enterprise applications where data privacy is critical. It can also be applied in fields like content creation and customer service automation, where generative AI models are becoming essential. Lastly, it helps industries without Wi-Fi to send data to the cloud and receive responses, as all the processing is done locally.
Conclusion
In conclusion, GAIA, an open-source AMD application, uses the power of the Ryzen AI NPU to deliver efficient, private, and high-performance LLMs. By running LLMs locally, GAIA ensures enhanced privacy, reduced latency, and optimized performance, making it ideal for industries that prioritize data security and rapid response times.
Ready to try GAIA yourself? Our video provides a brief overview and installation demo of GAIA.
Check out and contribute to the GAIA repo at github.com/amd/gaia. For feedback or questions, please reach out to us at GAIA@amd.com.
30 Comments on AMD Introduces GAIA - an Open-Source Project That Runs Local LLMs on Ryzen AI NPUs
github.com/amd/gaia
game.intel.com/us/stories/introducing-ai-playground/
www.igorslab.de/en/intel-presents-its-new-ai-playground-off-to-the-world-of-ki/
hothardware.com/news/intel-ai-playground-released
www.tomshardware.com/tech-industry/artificial-intelligence/intel-creates-ai-playground-app-for-local-ai-computing-lunar-lake-support-added-in-the-latest-version
github.com/intel/AI-PlaygroundIsn’t that wrong? As far as I’m aware, the GPU plainly has enough raw power to beat the NPU, even in inference. (I cannot find numbers for that.)
(I find it hard to find info on this, even though I’d say I’ve given it a good search. Maybe I’m too unexperienced, maybe Google is being dumb; also not on top of my game and heading to sleep soon.)Oh, that’s a very charitable reading of yours. Usually performance is about the item at hand (and more often than not, isolated benchmarks), had they meant whole-system performance, they should have said so.
If you were inferring that a modern GPU is better, then generally thats true just by memory bandwidth limitation alone.
The point is the NPU part of the newer APUs can now be used instead of just being a CoPilot+ selling point. 50 TOPS is nothing compared to a RTX 4060 (242 TOPS by itself), but at least we have access to it now.
www.amd.com/content/dam/amd/en/documents/radeon-tech-docs/instruction-set-architectures/rdna35_instruction_set_architecture.pdf
Still, given how those WMMA instructions use the regular vector units on RDNA3.5 and older, I believe the NPU has a higher rate when processing those, but I couldn't find the proper numbers after a quick google.Most of the AI stack out there is written in python, I don't see why this would be any different.