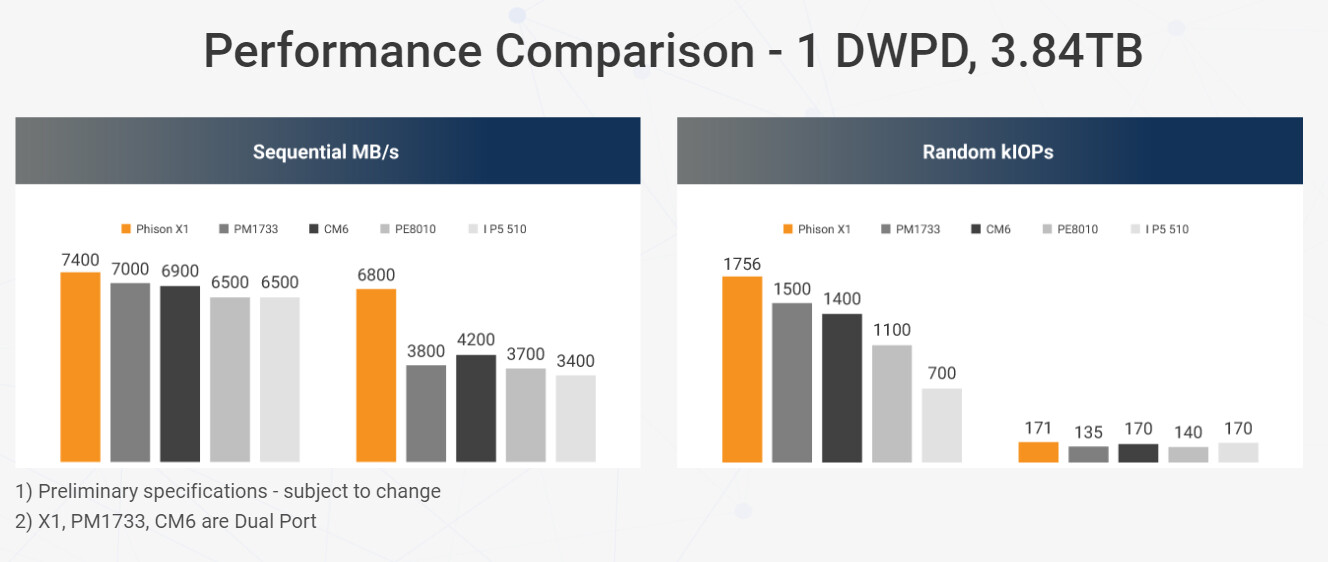
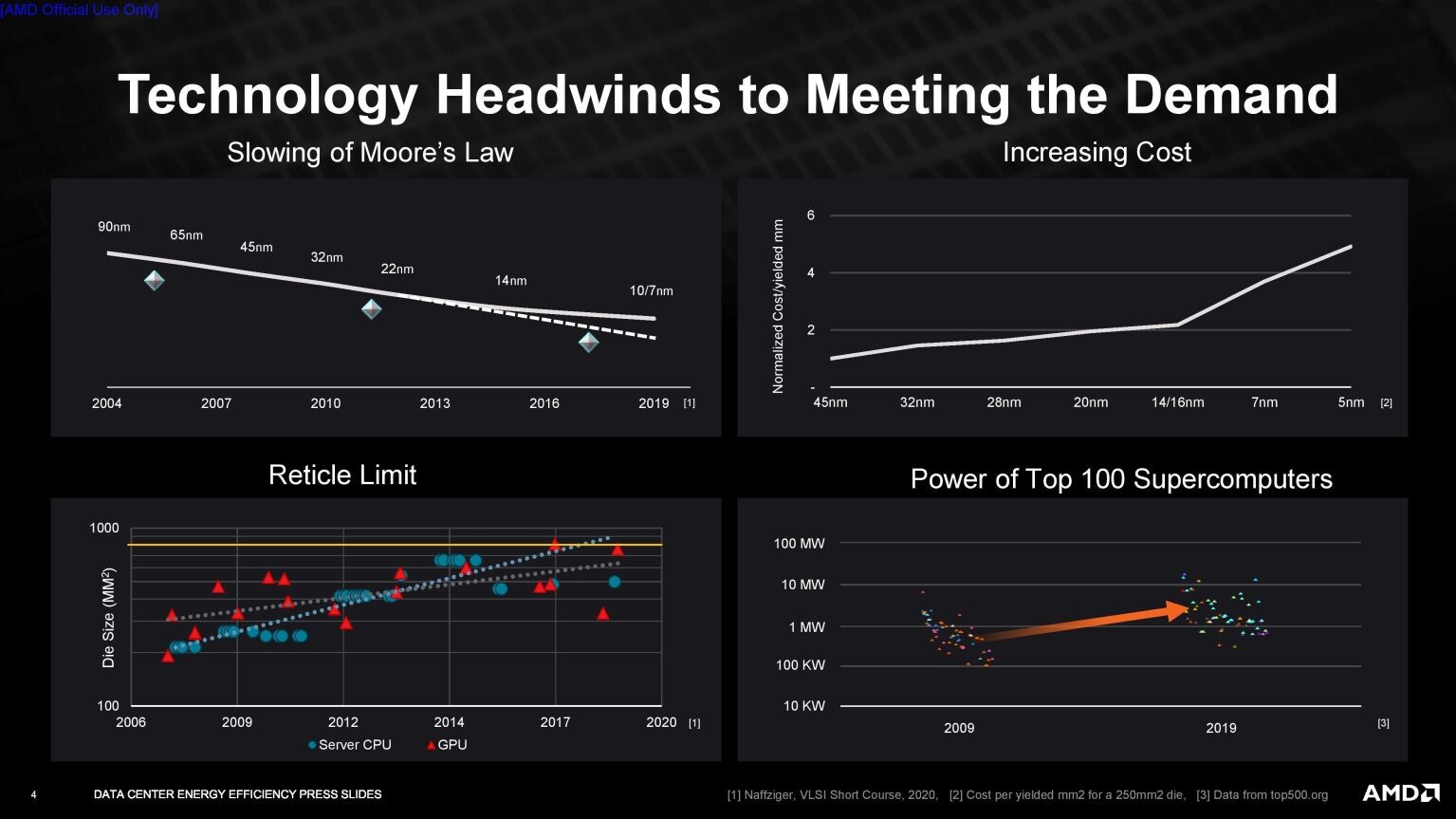
UK Government Seeks to Invest £900 Million in Supercomputer, Native Research into Advanced AI Deemed Essential
The UK Treasury has set aside a budget of £900 million to invest in the development of a supercomputer that would be powerful enough to chew through more than one billion billion simple calculations a second. A new exascale computer would fit the bill, for utilization by newly established advanced AI research bodies. It is speculated that one key goal is to establish a "BritGPT" system. The British government has been keeping tabs on recent breakthroughs in large language models, the most notable example being OpenAI's ChatGPT. Ambitions to match such efforts were revealed in a statement, with the emphasis: "to advance UK sovereign capability in foundation models, including large language models."
The current roster of United Kingdom-based supercomputers looks to be unfit for the task of training complex AI models. In light of being outpaced by drives in other countries to ramp up supercomputer budgets, the UK Government outlined its own future investments: "Because AI needs computing horsepower, I today commit around £900 million of funding, for an exascale supercomputer," said the chancellor, Jeremy Hunt. The government has declared that quantum technologies will receive an investment of £2.5 billion over the next decade. Proponents of the technology have declared that it will supercharge machine learning.


The current roster of United Kingdom-based supercomputers looks to be unfit for the task of training complex AI models. In light of being outpaced by drives in other countries to ramp up supercomputer budgets, the UK Government outlined its own future investments: "Because AI needs computing horsepower, I today commit around £900 million of funding, for an exascale supercomputer," said the chancellor, Jeremy Hunt. The government has declared that quantum technologies will receive an investment of £2.5 billion over the next decade. Proponents of the technology have declared that it will supercharge machine learning.