Strong Cloud AI Server Demand Propels NVIDIA's FY2Q24 Data Center Business to Surpass 76% for the First Time
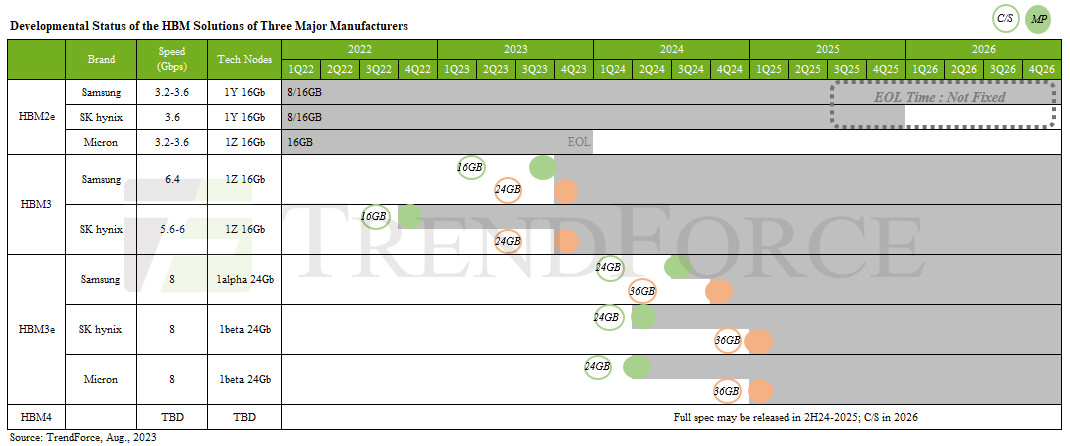
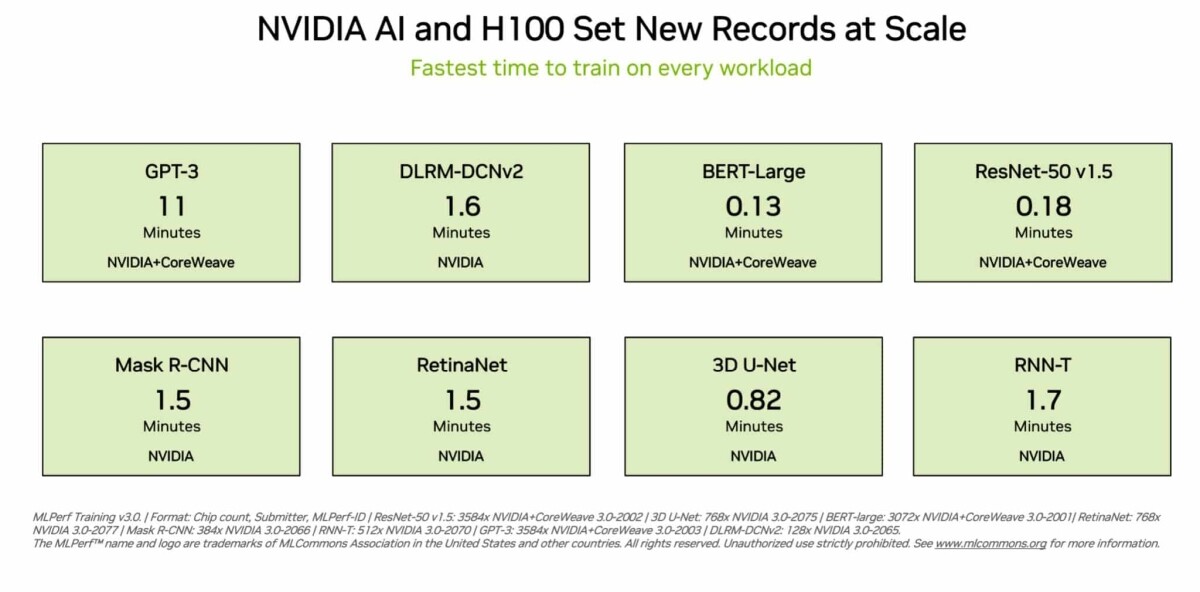
NVIDIA's latest financial report for FY2Q24 reveals that its data center business reached US$10.32 billion—a QoQ growth of 141% and YoY increase of 171%. The company remains optimistic about its future growth. TrendForce believes that the primary driver behind NVIDIA's robust revenue growth stems from its data center's AI server-related solutions. Key products include AI-accelerated GPUs and AI server HGX reference architecture, which serve as the foundational AI infrastructure for large data centers.
TrendForce further anticipates that NVIDIA will integrate its software and hardware resources. Utilizing a refined approach, NVIDIA will align its high-end, mid-tier, and entry-level GPU AI accelerator chips with various ODMs and OEMs, establishing a collaborative system certification model. Beyond accelerating the deployment of CSP cloud AI server infrastructures, NVIDIA is also partnering with entities like VMware on solutions including the Private AI Foundation. This strategy extends NVIDIA's reach into the edge enterprise AI server market, underpinning steady growth in its data center business for the next two years.
TrendForce further anticipates that NVIDIA will integrate its software and hardware resources. Utilizing a refined approach, NVIDIA will align its high-end, mid-tier, and entry-level GPU AI accelerator chips with various ODMs and OEMs, establishing a collaborative system certification model. Beyond accelerating the deployment of CSP cloud AI server infrastructures, NVIDIA is also partnering with entities like VMware on solutions including the Private AI Foundation. This strategy extends NVIDIA's reach into the edge enterprise AI server market, underpinning steady growth in its data center business for the next two years.