Dell and NVIDIA Introduce Project Helix, a Secure On-Premises Generative AI
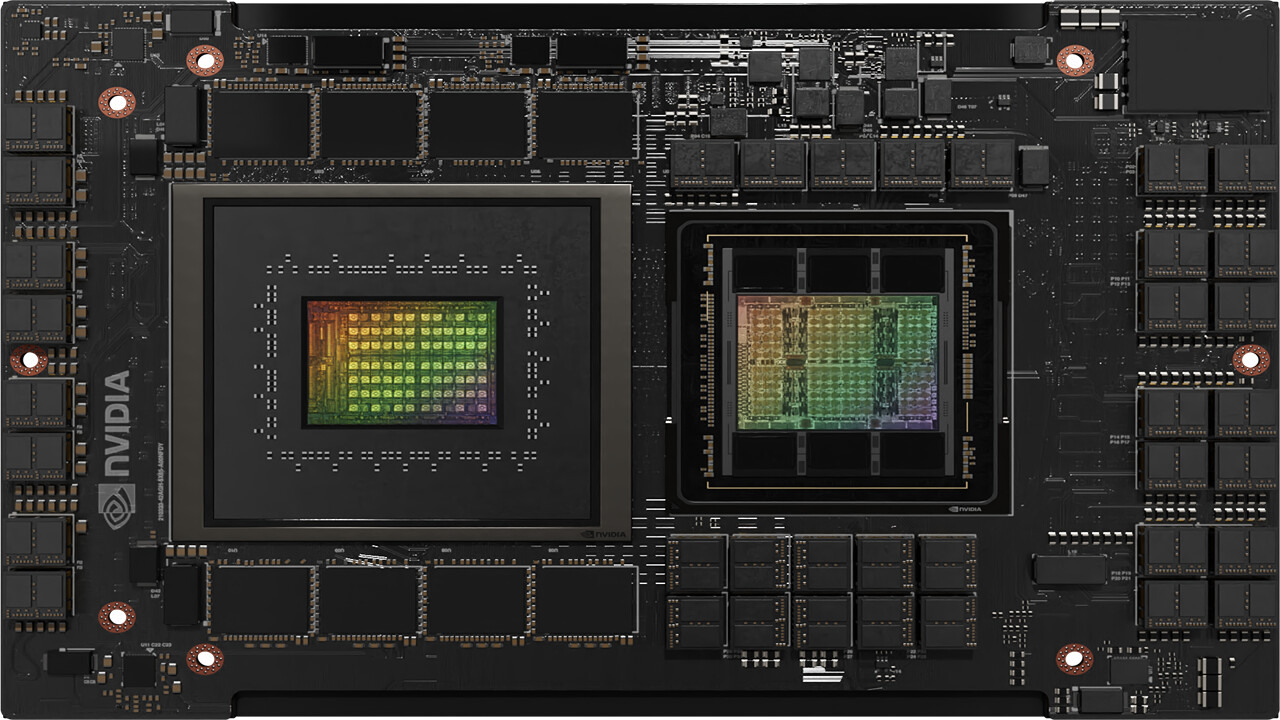
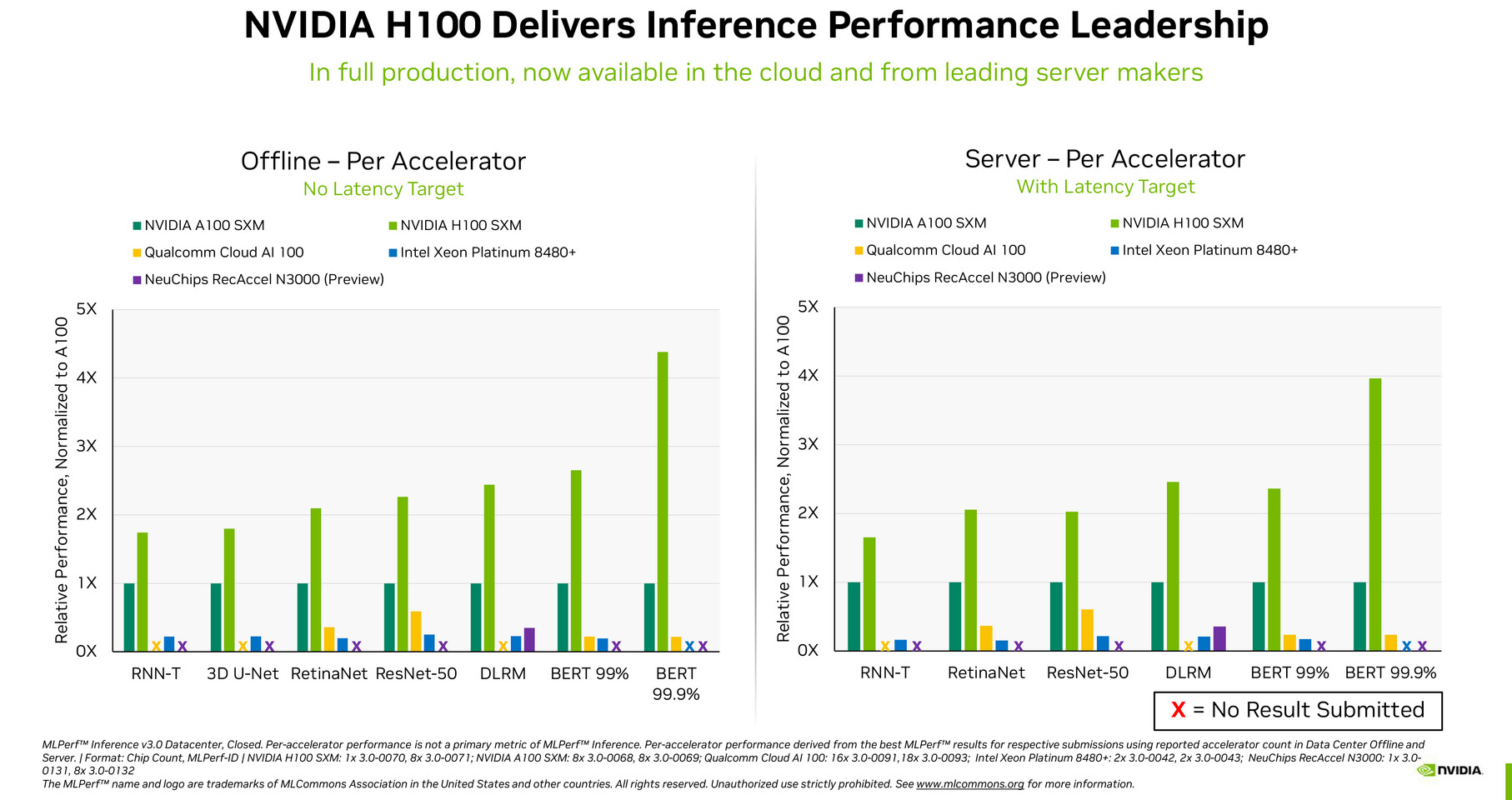
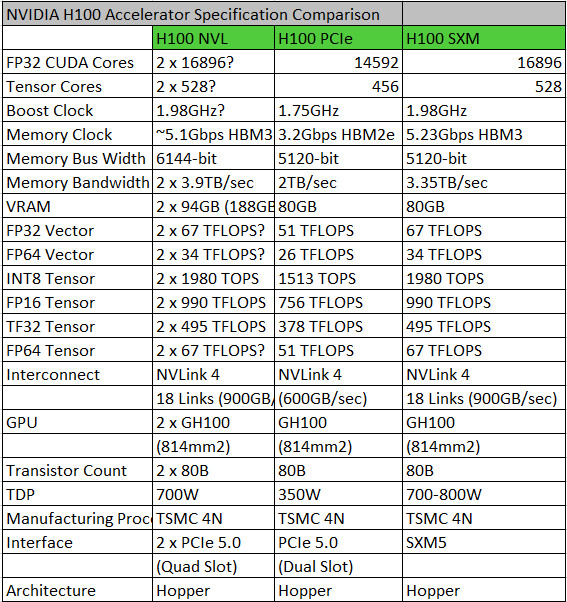
Dell Technologies and NVIDIA announce a joint initiative to make it easier for businesses to build and use generative AI models on-premises to quickly and securely deliver better customer service, market intelligence, enterprise search and a range of other capabilities. Project Helix will deliver a series of full-stack solutions with technical expertise and pre-built tools based on Dell and NVIDIA infrastructure and software. It includes a complete blueprint to help enterprises use their proprietary data and more easily deploy generative AI responsibly and accurately.
"Project Helix gives enterprises purpose-built AI models to more quickly and securely gain value from the immense amounts of data underused today," said Jeff Clarke, vice chairman and co-chief operating officer, Dell Technologies. "With highly scalable and efficient infrastructure, enterprises can create a new wave of generative AI solutions that can reinvent their industries."
"We are at a historic moment, when incredible advances in generative AI are intersecting with enterprise demand to do more with less," said Jensen Huang, founder and CEO, NVIDIA. "With Dell Technologies, we've designed extremely scalable, highly efficient infrastructure that enables enterprises to transform their business by securely using their own data to build and operate generative AI applications."
"Project Helix gives enterprises purpose-built AI models to more quickly and securely gain value from the immense amounts of data underused today," said Jeff Clarke, vice chairman and co-chief operating officer, Dell Technologies. "With highly scalable and efficient infrastructure, enterprises can create a new wave of generative AI solutions that can reinvent their industries."
"We are at a historic moment, when incredible advances in generative AI are intersecting with enterprise demand to do more with less," said Jensen Huang, founder and CEO, NVIDIA. "With Dell Technologies, we've designed extremely scalable, highly efficient infrastructure that enables enterprises to transform their business by securely using their own data to build and operate generative AI applications."