European HPC Processor "Rhea1" Tapes Out, Launch Delayed to 2026
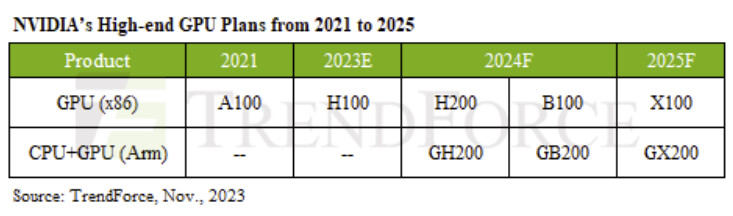
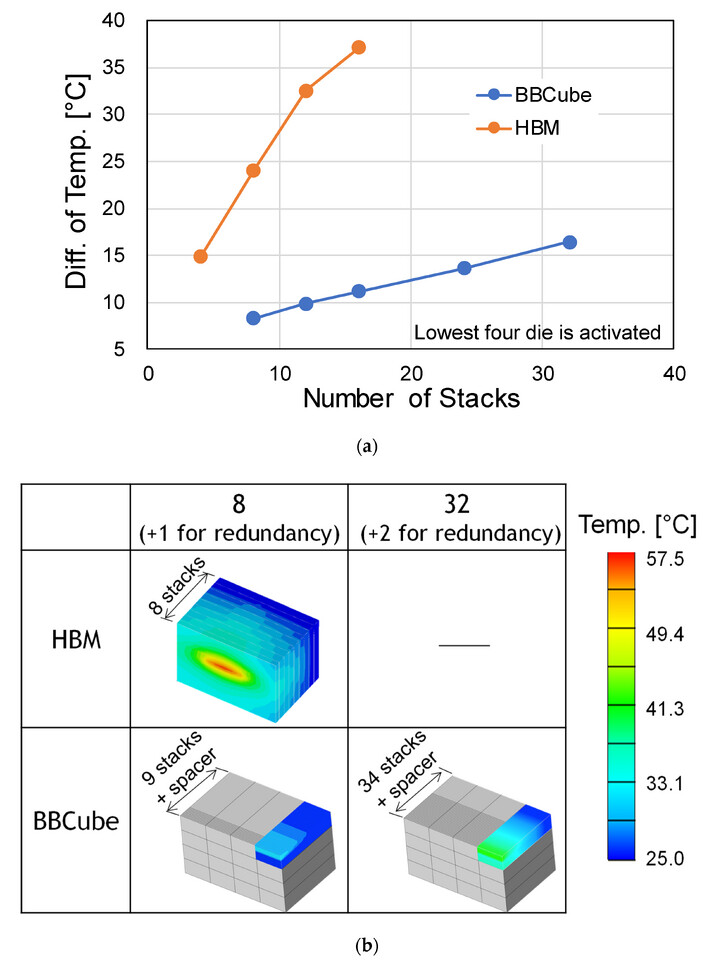
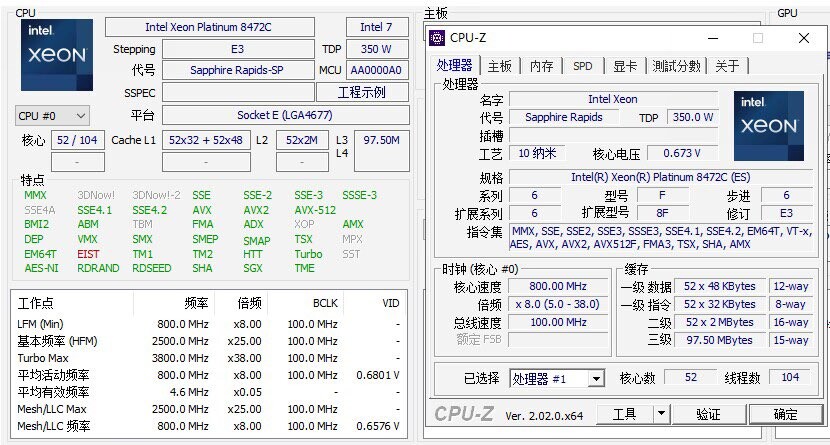
European Processor Initiative (EPI) is nearing completion of its first goal. SiPearl, the leading developer behind the Rhea1 processor, has finally reached the tapeout stage after a string of delays, but it will not be ready for delivery until 2026 at the earliest. When the project launched in 2020, SiPearl planned to begin production in 2023; however, the 61 billion-transistor chip only entered tapeout this summer. The design, built on TSMC's N6 process, features 80 Arm Neoverse V1 cores alongside 64 GB of HBM2E memory and a DDR5 interface. While these specifications once looked cutting‑edge, the industry has already moved on, and Rhea1's raw performance may seem dated by the time samples are available. SiPearl initially explored a RISC‑V architecture back in 2019 but abandoned it after early feedback and comments highlighted the instruction set's immaturity for exascale computing.
Development was further interrupted by shifting core‑count debates, with teams alternately considering 72 cores, then 64, before finally settling on 80 cores by 2022. Those back‑and‑forth decisions, combined with evolving performance expectations, helped push the timeline back by years. Despite missing its original schedule, Rhea1 remains vital to European ambitions for high‑performance computing sovereignty and serves as the intended CPU for the Jupiter supercomputer. Thanks to Jupiter's modular design, the system was not left idle; its GPU booster module, running NVIDIA Grace Hopper accelerators, is already operational and approximately 80 percent complete. With the CPU clusters slated for mid-2026 deployment, full system readiness is expected by the end of 2026. To support this effort, SiPearl has recently secured €130 million in new financing from the French government, industry partners, and Taiwan's Cathay Venture. As Rhea1 finishes its goal, work on Rhea2 is already underway, and we can expect more updates about Rhea2 in a year or two.
Development was further interrupted by shifting core‑count debates, with teams alternately considering 72 cores, then 64, before finally settling on 80 cores by 2022. Those back‑and‑forth decisions, combined with evolving performance expectations, helped push the timeline back by years. Despite missing its original schedule, Rhea1 remains vital to European ambitions for high‑performance computing sovereignty and serves as the intended CPU for the Jupiter supercomputer. Thanks to Jupiter's modular design, the system was not left idle; its GPU booster module, running NVIDIA Grace Hopper accelerators, is already operational and approximately 80 percent complete. With the CPU clusters slated for mid-2026 deployment, full system readiness is expected by the end of 2026. To support this effort, SiPearl has recently secured €130 million in new financing from the French government, industry partners, and Taiwan's Cathay Venture. As Rhea1 finishes its goal, work on Rhea2 is already underway, and we can expect more updates about Rhea2 in a year or two.