Wednesday, August 24th 2022
BIREN BR100 Detailed: China's AI-HPC Processor Storms into the HPC GPU Big Leagues
If InnoSilicon's Fenghua gaming GPU hit the scene last November seemingly out of nowhere, then another Chinese GPU developer is making waves at HotChips 22, this time in the enterprise space. The BR100 by BIREN is a large AI-HPC GPU-based processor that's China's answer to the Hopper, Ponte Vecchio, and CDNA2, and ensure China's growth as an AI/HPC leader is unaffected in the event of a tech embargo for whatever reason.
The BR100 is an MCM of two planar-silicon dies built on the 7 nm DUV node, with a striking 77 billion transistor-count between them, and 550 W TDP (typical). The chip features 64 GB of on-package HBM2E memory. System bus interfaces include PCI-Express 5.0 x16 with CXL, and eight lanes of a proprietary interconnect called B-Link, which total 2.3 TB/s of bandwidth. The processor supports nearly all popular compute formats except double-precision floating-point, or FP64. Among the supported ones are single-precision or FP32, TF32+, FP16, BF16, INT16, and INT8. BIREN claims up to 256 TFLOP/s FP32, up to 512 TFLOP/s TF32+, up to 1 PFLOP/s BF16, and 2,048 TOPS INT8. This would put it at 2.4 to 2.8 times faster than NVIDIA's "Ampere" A100.


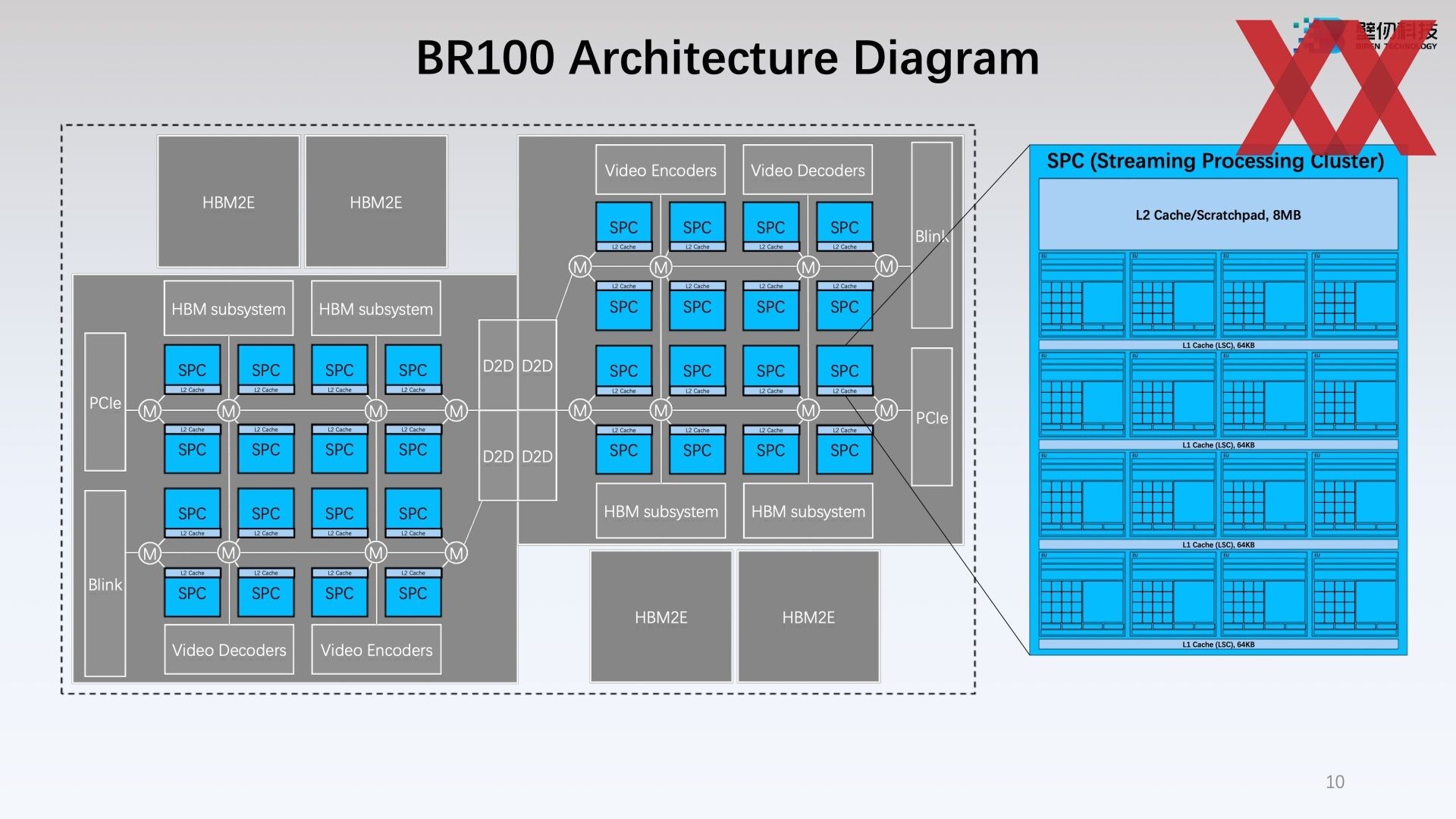
 The component hierarchy of the BR100 consists of a network of highly specialized computing elements called SPC or Streaming Processing Cluster. Each SPC contains 16 EUs (execution units), the indivisible number-crunching machinery of the GPU. Each EU contains 16 V-cores, or SIMD units for FP32 and other math formats; and a Tensor core. There are various levels of caches within the EU and SPC. The GPU lacks any raster graphics hardware, and cannot light up a monitor. However, it contains media-acceleration engines, so encoding and decoding of certain modern video formats can benefit from hardware-acceleration.
The component hierarchy of the BR100 consists of a network of highly specialized computing elements called SPC or Streaming Processing Cluster. Each SPC contains 16 EUs (execution units), the indivisible number-crunching machinery of the GPU. Each EU contains 16 V-cores, or SIMD units for FP32 and other math formats; and a Tensor core. There are various levels of caches within the EU and SPC. The GPU lacks any raster graphics hardware, and cannot light up a monitor. However, it contains media-acceleration engines, so encoding and decoding of certain modern video formats can benefit from hardware-acceleration.
BIREN hopes that the BR100 will power AI and HPC servers, as well as media among the country's popular cloud compute service providers.
Source:
HWLuxx.de
The BR100 is an MCM of two planar-silicon dies built on the 7 nm DUV node, with a striking 77 billion transistor-count between them, and 550 W TDP (typical). The chip features 64 GB of on-package HBM2E memory. System bus interfaces include PCI-Express 5.0 x16 with CXL, and eight lanes of a proprietary interconnect called B-Link, which total 2.3 TB/s of bandwidth. The processor supports nearly all popular compute formats except double-precision floating-point, or FP64. Among the supported ones are single-precision or FP32, TF32+, FP16, BF16, INT16, and INT8. BIREN claims up to 256 TFLOP/s FP32, up to 512 TFLOP/s TF32+, up to 1 PFLOP/s BF16, and 2,048 TOPS INT8. This would put it at 2.4 to 2.8 times faster than NVIDIA's "Ampere" A100.



BIREN hopes that the BR100 will power AI and HPC servers, as well as media among the country's popular cloud compute service providers.
6 Comments on BIREN BR100 Detailed: China's AI-HPC Processor Storms into the HPC GPU Big Leagues
"1074mm2, the 77 billion-transistor, dual-die Biren BR100 (pictured in the header) will be manufactured on TSMC’s 7nm process and capable of 256 FP32 teraflops."
www.hpcwire.com/2022/08/22/chinese-startup-biren-details-br100-gpu/