Mar 28th, 2025 08:10 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Post your CrystalDiskMark speeds (616)
- Will you buy a RTX 5090? (455)
- Technical Issues - TPU Main Site & Forum (2025) (81)
- Should you physically remove secondary NVMe drives when performing a clean Windows install? (40)
- AMD RX 9070 XT & RX 9070 non-XT thread (OC, undervolt, benchmarks, ...) (64)
- Future-proofing my OLED (33)
- RTX 3050 with GA107 GPU incomplete information and sensor issue. (0)
- Post your Monster Hunter Wilds benchmark scores (151)
- Compatibility With Alphacool Core RX 9070 XT Taichi GPU WaterBlock ?? (0)
- Recommended PhysX card for 5xxx series? [Is vRAM relevant?] (226)
Popular Reviews
- Sapphire Radeon RX 9070 XT Pulse Review
- Samsung 9100 Pro 2 TB Review - The Best Gen 5 SSD
- Assassin's Creed Shadows Performance Benchmark Review - 30 GPUs Compared
- Pulsar Feinmann F01 Review
- ASRock Phantom Gaming B860I Lightning Wi-Fi Review
- be quiet! Pure Rock Pro 3 Black Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- ASRock Radeon RX 9070 XT Taichi OC Review - Excellent Cooling
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- ASUS ProArt X870E-Creator Wi-Fi Review
Controversial News Posts
- AMD RDNA 4 and Radeon RX 9070 Series Unveiled: $549 & $599 (260)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (142)
- Microsoft Introduces Copilot for Gaming (123)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (118)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (96)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)
News Posts matching #LLM
Return to Keyword Browsing
IBM Announces Availability of Open-Source Mistral AI Model on watsonx
IBM announced the availability of the popular open-source Mixtral-8x7B large language model (LLM), developed by Mistral AI, on its watsonx AI and data platform, as it continues to expand capabilities to help clients innovate with IBM's own foundation models and those from a range of open-source providers. IBM offers an optimized version of Mixtral-8x7B that, in internal testing, was able to increase throughput—or the amount of data that can be processed in a given time period—by 50 percent when compared to the regular model. This could potentially cut latency by 35-75 percent, depending on batch size—speeding time to insights. This is achieved through a process called quantization, which reduces model size and memory requirements for LLMs and, in turn, can speed up processing to help lower costs and energy consumption.
The addition of Mixtral-8x7B expands IBM's open, multi-model strategy to meet clients where they are and give them choice and flexibility to scale enterprise AI solutions across their businesses. Through decades-long AI research and development, open collaboration with Meta and Hugging Face, and partnerships with model leaders, IBM is expanding its watsonx.ai model catalog and bringing in new capabilities, languages, and modalities. IBM's enterprise-ready foundation model choices and its watsonx AI and data platform can empower clients to use generative AI to gain new insights and efficiencies, and create new business models based on principles of trust. IBM enables clients to select the right model for the right use cases and price-performance goals for targeted business domains like finance.
The addition of Mixtral-8x7B expands IBM's open, multi-model strategy to meet clients where they are and give them choice and flexibility to scale enterprise AI solutions across their businesses. Through decades-long AI research and development, open collaboration with Meta and Hugging Face, and partnerships with model leaders, IBM is expanding its watsonx.ai model catalog and bringing in new capabilities, languages, and modalities. IBM's enterprise-ready foundation model choices and its watsonx AI and data platform can empower clients to use generative AI to gain new insights and efficiencies, and create new business models based on principles of trust. IBM enables clients to select the right model for the right use cases and price-performance goals for targeted business domains like finance.


ServiceNow, Hugging Face & NVIDIA Release StarCoder2 - a New Open-Access LLM Family
ServiceNow, Hugging Face, and NVIDIA today announced the release of StarCoder2, a family of open-access large language models for code generation that sets new standards for performance, transparency, and cost-effectiveness. StarCoder2 was developed in partnership with the BigCode Community, managed by ServiceNow, the leading digital workflow company making the world work better for everyone, and Hugging Face, the most-used open-source platform, where the machine learning community collaborates on models, datasets, and applications. Trained on 619 programming languages, StarCoder2 can be further trained and embedded in enterprise applications to perform specialized tasks such as application source code generation, workflow generation, text summarization, and more. Developers can use its code completion, advanced code summarization, code snippets retrieval, and other capabilities to accelerate innovation and improve productivity.
StarCoder2 offers three model sizes: a 3-billion-parameter model trained by ServiceNow; a 7-billion-parameter model trained by Hugging Face; and a 15-billion-parameter model built by NVIDIA with NVIDIA NeMo and trained on NVIDIA accelerated infrastructure. The smaller variants provide powerful performance while saving on compute costs, as fewer parameters require less computing during inference. In fact, the new 3-billion-parameter model matches the performance of the original StarCoder 15-billion-parameter model. "StarCoder2 stands as a testament to the combined power of open scientific collaboration and responsible AI practices with an ethical data supply chain," emphasized Harm de Vries, lead of ServiceNow's StarCoder2 development team and co-lead of BigCode. "The state-of-the-art open-access model improves on prior generative AI performance to increase developer productivity and provides developers equal access to the benefits of code generation AI, which in turn enables organizations of any size to more easily meet their full business potential."


StarCoder2 offers three model sizes: a 3-billion-parameter model trained by ServiceNow; a 7-billion-parameter model trained by Hugging Face; and a 15-billion-parameter model built by NVIDIA with NVIDIA NeMo and trained on NVIDIA accelerated infrastructure. The smaller variants provide powerful performance while saving on compute costs, as fewer parameters require less computing during inference. In fact, the new 3-billion-parameter model matches the performance of the original StarCoder 15-billion-parameter model. "StarCoder2 stands as a testament to the combined power of open scientific collaboration and responsible AI practices with an ethical data supply chain," emphasized Harm de Vries, lead of ServiceNow's StarCoder2 development team and co-lead of BigCode. "The state-of-the-art open-access model improves on prior generative AI performance to increase developer productivity and provides developers equal access to the benefits of code generation AI, which in turn enables organizations of any size to more easily meet their full business potential."


Supermicro Accelerates Performance of 5G and Telco Cloud Workloads with New and Expanded Portfolio of Infrastructure Solutions
Supermicro, Inc. (NASDAQ: SMCI), a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, delivers an expanded portfolio of purpose-built infrastructure solutions to accelerate performance and increase efficiency in 5G and telecom workloads. With one of the industry's most diverse offerings, Supermicro enables customers to expand public and private 5G infrastructures with improved performance per watt and support for new and innovative AI applications. As a long-term advocate of open networking platforms and a member of the O-RAN Alliance, Supermicro's portfolio incorporates systems featuring 5th Gen Intel Xeon processors, AMD EPYC 8004 Series processors, and the NVIDIA Grace Hopper Superchip.
"Supermicro is expanding our broad portfolio of sustainable and state-of-the-art servers to address the demanding requirements of 5G and telco markets and Edge AI," said Charles Liang, president and CEO of Supermicro. "Our products are not just about technology, they are about delivering tangible customer benefits. We quickly bring data center AI capabilities to the network's edge using our Building Block architecture. Our products enable operators to offer new capabilities to their customers with improved performance and lower energy consumption. Our edge servers contain up to 2 TB of high-speed DDR5 memory, 6 PCIe slots, and a range of networking options. These systems are designed for increased power efficiency and performance-per-watt, enabling operators to create high-performance, customized solutions for their unique requirements. This reassures our customers that they are investing in reliable and efficient solutions."
"Supermicro is expanding our broad portfolio of sustainable and state-of-the-art servers to address the demanding requirements of 5G and telco markets and Edge AI," said Charles Liang, president and CEO of Supermicro. "Our products are not just about technology, they are about delivering tangible customer benefits. We quickly bring data center AI capabilities to the network's edge using our Building Block architecture. Our products enable operators to offer new capabilities to their customers with improved performance and lower energy consumption. Our edge servers contain up to 2 TB of high-speed DDR5 memory, 6 PCIe slots, and a range of networking options. These systems are designed for increased power efficiency and performance-per-watt, enabling operators to create high-performance, customized solutions for their unique requirements. This reassures our customers that they are investing in reliable and efficient solutions."


Intel Optimizes PyTorch for Llama 2 on Arc A770, Higher Precision FP16
Intel just announced optimizations for PyTorch (IPEX) to take advantage of the AI acceleration features of its Arc "Alchemist" GPUs.PyTorch is a popular machine learning library that is often associated with NVIDIA GPUs, but it is actually platform-agnostic. It can be run on a variety of hardware, including CPUs and GPUs. However, performance may not be optimal without specific optimizations. Intel offers such optimizations through the Intel Extension for PyTorch (IPEX), which extends PyTorch with optimizations specifically designed for Intel's compute hardware.
Intel released a blog post detailing how to run Meta AI's Llama 2 large language model on its Arc "Alchemist" A770 graphics card. The model requires 14 GB of GPU RAM, so a 16 GB version of the A770 is recommended. This development could be seen as a direct response to NVIDIA's Chat with RTX tool, which allows GeForce users with >8 GB RTX 30-series "Ampere" and RTX 40-series "Ada" GPUs to run PyTorch-LLM models on their graphics cards. NVIDIA achieves lower VRAM usage by distributing INT4-quantized versions of the models, while Intel uses a higher-precision FP16 version. In theory, this should not have a significant impact on the results. This blog post by Intel provides instructions on how to set up Llama 2 inference with PyTorch (IPEX) on the A770.
Intel released a blog post detailing how to run Meta AI's Llama 2 large language model on its Arc "Alchemist" A770 graphics card. The model requires 14 GB of GPU RAM, so a 16 GB version of the A770 is recommended. This development could be seen as a direct response to NVIDIA's Chat with RTX tool, which allows GeForce users with >8 GB RTX 30-series "Ampere" and RTX 40-series "Ada" GPUs to run PyTorch-LLM models on their graphics cards. NVIDIA achieves lower VRAM usage by distributing INT4-quantized versions of the models, while Intel uses a higher-precision FP16 version. In theory, this should not have a significant impact on the results. This blog post by Intel provides instructions on how to set up Llama 2 inference with PyTorch (IPEX) on the A770.

Google's Gemma Optimized to Run on NVIDIA GPUs, Gemma Coming to Chat with RTX
NVIDIA, in collaboration with Google, today launched optimizations across all NVIDIA AI platforms for Gemma—Google's state-of-the-art new lightweight 2 billion- and 7 billion-parameter open language models that can be run anywhere, reducing costs and speeding innovative work for domain-specific use cases.
Teams from the companies worked closely together to accelerate the performance of Gemma—built from the same research and technology used to create the Gemini models—with NVIDIA TensorRT-LLM, an open-source library for optimizing large language model inference, when running on NVIDIA GPUs in the data center, in the cloud and on PCs with NVIDIA RTX GPUs. This allows developers to target the installed base of over 100 million NVIDIA RTX GPUs available in high-performance AI PCs globally.
Teams from the companies worked closely together to accelerate the performance of Gemma—built from the same research and technology used to create the Gemini models—with NVIDIA TensorRT-LLM, an open-source library for optimizing large language model inference, when running on NVIDIA GPUs in the data center, in the cloud and on PCs with NVIDIA RTX GPUs. This allows developers to target the installed base of over 100 million NVIDIA RTX GPUs available in high-performance AI PCs globally.

Groq LPU AI Inference Chip is Rivaling Major Players like NVIDIA, AMD, and Intel
AI workloads are split into two different categories: training and inference. While training requires large computing and memory capacity, access speeds are not a significant contributor; inference is another story. With inference, the AI model must run extremely fast to serve the end-user with as many tokens (words) as possible, hence giving the user answers to their prompts faster. An AI chip startup, Groq, which was in stealth mode for a long time, has been making major moves in providing ultra-fast inference speeds using its Language Processing Unit (LPU) designed for large language models (LLMs) like GPT, Llama, and Mistral LLMs. The Groq LPU is a single-core unit based on the Tensor-Streaming Processor (TSP) architecture which achieves 750 TOPS at INT8 and 188 TeraFLOPS at FP16, with 320x320 fused dot product matrix multiplication, in addition to 5,120 Vector ALUs.
Having massive concurrency with 80 TB/s of bandwidth, the Groq LPU has 230 MB capacity of local SRAM. All of this is working together to provide Groq with a fantastic performance, making waves over the past few days on the internet. Serving the Mixtral 8x7B model at 480 tokens per second, the Groq LPU is providing one of the leading inference numbers in the industry. In models like Llama 2 70B with 4096 token context length, Groq can serve 300 tokens/s, while in smaller Llama 2 7B with 2048 tokens of context, Groq LPU can output 750 tokens/s. According to the LLMPerf Leaderboard, the Groq LPU is beating the GPU-based cloud providers at inferencing LLMs Llama in configurations of anywhere from 7 to 70 billion parameters. In token throughput (output) and time to first token (latency), Groq is leading the pack, achieving the highest throughput and second lowest latency.


Having massive concurrency with 80 TB/s of bandwidth, the Groq LPU has 230 MB capacity of local SRAM. All of this is working together to provide Groq with a fantastic performance, making waves over the past few days on the internet. Serving the Mixtral 8x7B model at 480 tokens per second, the Groq LPU is providing one of the leading inference numbers in the industry. In models like Llama 2 70B with 4096 token context length, Groq can serve 300 tokens/s, while in smaller Llama 2 7B with 2048 tokens of context, Groq LPU can output 750 tokens/s. According to the LLMPerf Leaderboard, the Groq LPU is beating the GPU-based cloud providers at inferencing LLMs Llama in configurations of anywhere from 7 to 70 billion parameters. In token throughput (output) and time to first token (latency), Groq is leading the pack, achieving the highest throughput and second lowest latency.



Sony CEO Wants PlayStation Ecosystem to Expand into PC, AI & Cloud Territories
Kenichiro Yoshida—Sony Group Corporation Chairman, President And CEO—appeared as a guest on Norges Bank Investment Management's Good Company videocast late last year. News outlets have sluggishly picked up on some interesting tidbits from the November 2023 interview—the Sony boss has discussed his gaming division's ambitions in the recent past, but (host) Nicolai Tangen managed to pry out a clearer picture of PlayStation's ambitions for the future. Yoshida-san has an all-encompassing vision for the brand: "In short, it will be ubiquitous wherever there is computing users will be able to play their favorite games seamlessly, gamers will be able to find a place to play in different spaces, while PlayStation will remain our core product, we will expand our gaming experiences to PC, Mobile and Cloud." Gamers on the PC platform have to wait roughly two to three years for PlayStation exclusive titles to breakaway from home consoles origins—it is encouraging to hear that a greater number of conversions could be in the pipeline (with shorter lead times...hopefully).
The discussion moved onto game subscription services—a hotbed talking point as of late—Yoshida seemed to be happy with his company's normal mode of operation: "Well, we do subscription business model. At the same time, people usually play one game at the time, so an all-you-can-eat type of many games may not be so valuable compared with video streaming services. We have kind of balanced a hybrid service on PlayStation Network: subscription as well as paid content." Microsoft is a market leader with its Xbox and PC Game Pass services, now bolstered with a takeover of Activision Blizzard—the Sony CEO remained calm regarding his firm's main rival: "Healthy competition is necessary for the Games Industry to grow and at Sony we believe it is important to provide gamers with different options to play so we will continue our efforts to achieve this."



The discussion moved onto game subscription services—a hotbed talking point as of late—Yoshida seemed to be happy with his company's normal mode of operation: "Well, we do subscription business model. At the same time, people usually play one game at the time, so an all-you-can-eat type of many games may not be so valuable compared with video streaming services. We have kind of balanced a hybrid service on PlayStation Network: subscription as well as paid content." Microsoft is a market leader with its Xbox and PC Game Pass services, now bolstered with a takeover of Activision Blizzard—the Sony CEO remained calm regarding his firm's main rival: "Healthy competition is necessary for the Games Industry to grow and at Sony we believe it is important to provide gamers with different options to play so we will continue our efforts to achieve this."





AMD Instinct MI300X GPUs Featured in LaminiAI LLM Pods
LaminiAI appears to be one of AMD's first customers to receive a bulk order of Instinct MI300X GPUs—late last week, Sharon Zhou (CEO and co-founder) posted about the "next batch of LaminiAI LLM Pods" up and running with Team Red's cutting-edge CDNA 3 series accelerators inside. Her short post on social media stated: "rocm-smi...like freshly baked bread, 8x MI300X is online—if you're building on open LLMs and you're blocked on compute, lmk. Everyone should have access to this wizard technology called LLMs."
An attached screenshot of a ROCm System Management Interface (ROCm SMI) session showcases an individual Pod configuration sporting eight Instinct MI300X GPUs. According to official blog entries, LaminiAI has utilized bog-standard MI300 accelerators since 2023, so it is not surprising to see their partnership continue to grow with AMD. Industry predictions have the Instinct MI300X and MI300A models placed as great alternatives to NVIDIA's dominant H100 "Hopper" series—AMD stock is climbing due to encouraging financial analyst estimations.



An attached screenshot of a ROCm System Management Interface (ROCm SMI) session showcases an individual Pod configuration sporting eight Instinct MI300X GPUs. According to official blog entries, LaminiAI has utilized bog-standard MI300 accelerators since 2023, so it is not surprising to see their partnership continue to grow with AMD. Industry predictions have the Instinct MI300X and MI300A models placed as great alternatives to NVIDIA's dominant H100 "Hopper" series—AMD stock is climbing due to encouraging financial analyst estimations.





Microsoft Sets 16 GB RAM as Minimum-Requirement for Copilot and Windows AI Features
Microsoft has reportedly set 16 GB as the minimum system requirement for AI PCs, a TrendForce market research report finds. To say that Microsoft has a pivotal role to play in PC hardware specs is an understatement. This year sees the introduction of the first "AI PCs," or PCs with on-device AI acceleration for several new features native to Windows 11 23H2, mainly Microsoft Copilot. From the looks of it, Copilot is receiving the highest corporate attention from Microsoft, as the company looks to integrate the AI chatbot that automates and generates work, into the mainstream PC. In fact, Microsoft is even pushing for a dedicated Copilot button on PC keyboards along the lines of the key that brings up the Start menu. The company's biggest move with Copilot will be the 2024 introduction of Copilot Pro, an AI assistant integrated with Office and 365, which the company plans to sell on a subscription basis alone.
Besides cloud-based acceleration, Microsoft's various AI features will rely on some basic hardware specs for local acceleration. One of them of course is the NPU, with Intel's AI Boost and AMD's Ryzen AI being introduced with their latest mobile processors. The other requirement will be memory. AI acceleration is a highly memory sensitive operation, and LLMs require a sizable amount of fast frequent-access memory. So Microsoft arrived at 16 GB as the bare minimum amount of memory for not just native acceleration, but also cloud-based Copilot AI features to work. This should see the notebooks of 2024 set 16 GB as their baseline memory specs; and for commercial notebooks to scale up to 32 GB or even 64 GB, depending on organizational requirements. The development bodes particularly well for the DRAM industry.
Besides cloud-based acceleration, Microsoft's various AI features will rely on some basic hardware specs for local acceleration. One of them of course is the NPU, with Intel's AI Boost and AMD's Ryzen AI being introduced with their latest mobile processors. The other requirement will be memory. AI acceleration is a highly memory sensitive operation, and LLMs require a sizable amount of fast frequent-access memory. So Microsoft arrived at 16 GB as the bare minimum amount of memory for not just native acceleration, but also cloud-based Copilot AI features to work. This should see the notebooks of 2024 set 16 GB as their baseline memory specs; and for commercial notebooks to scale up to 32 GB or even 64 GB, depending on organizational requirements. The development bodes particularly well for the DRAM industry.


ARM Confirms Existence of Next-gen Cortex-X "Blackhawk" Unit
Last week Patrick Moorhead, CEO and founder of Moor Insights & Strategy, shared his insider sourced thoughts about ARM's next generation Cortex-X processor: "Blackhawk is planned to enable in smartphones shipping at the end of 2024. I think phones could be on the shelf a year from now at CES or maybe MWC." Moorhead believes that Cortex-X4's successor will be the most powerful option available at launch, which forms part of (ARM CEO) Rene Haas's strategy to "eliminate the performance gap between ARM-designed processors and custom ARM implementations." He believes that "this is a big and bold claim," since Apple is widely considered to rule the roost here with its cutting edge ARM-based Bionic designs. Moorhead's inside information has "Blackhawk" demonstrating the "largest year-over-year IPC performance increase in 5 years" citing undisclosed Geekbench 6 results.
He also presented evidence that the artificial intelligence processing is a key focus: "I am hopeful these performance goals translate to app performance as well. ARM also believes that Blackhawk will provide "great" LLM performance. I will assume that this has to do with big CPU IPC performance improvements as ARM says that its Cortex CPU is the #1 AI target for developers...The NPU and GPU can be an efficient way to run AI, but a CPU is the easiest and most pervasive way, which is why developers target it. A higher-performing CPU obviously helps here, but as the world moves increasingly to smaller language models, Arm's platform with higher-performing CPU and GPU combined with its tightly integrated ML libraries and frameworks will likely result in a more efficient experience on devices."


He also presented evidence that the artificial intelligence processing is a key focus: "I am hopeful these performance goals translate to app performance as well. ARM also believes that Blackhawk will provide "great" LLM performance. I will assume that this has to do with big CPU IPC performance improvements as ARM says that its Cortex CPU is the #1 AI target for developers...The NPU and GPU can be an efficient way to run AI, but a CPU is the easiest and most pervasive way, which is why developers target it. A higher-performing CPU obviously helps here, but as the world moves increasingly to smaller language models, Arm's platform with higher-performing CPU and GPU combined with its tightly integrated ML libraries and frameworks will likely result in a more efficient experience on devices."



New LeftoverLocals Vulnerability Threatens LLM Security on Apple, AMD, and Qualcomm GPUs
New York-based security firm Trail of Bits has identified a security vulnerability with various GPU models, which include AMD, Qualcomm, and Apple. This vulnerability, named LeftoverLocals, could potentially allow attackers to steal large amounts of data from a GPU's memory. Mainstream client-GPUs form a sizable chunk of the hardware accelerating AI and LLMs, as they cost a fraction of purpose-built data-center GPUs, and are available in the retail market. Unlike CPUs, which have undergone extensive hardening against data leaks, GPUs were primarily designed for graphics acceleration and lack similar data privacy architecture. To our knowledge, none of the client GPUs use virtualization with their graphics memory. Graphics acceleration in general is a very memory sensitive application, and requires SIMD units to have bare-metal access to memory, with as little latency as possible.
First the good news—for this vulnerability to be exploited, it requires the attacker to have access to the target device with the vulnerable GPU (i.e. cut through OS-level security). The attack could break down data silos on modern computers and servers, allowing unauthorized access to GPU memory. The potential data breach could include queries, responses generated by LLMs, and the weights driving the response. The researchers tested 11 chips from seven GPU makers and found the vulnerability in GPUs from Apple, AMD, and Qualcomm. While NVIDIA, Intel, and Arm first-party GPUs did not show evidence of the vulnerability, Apple, Qualcomm, and AMD confirmed to wired that their GPUs are affected, and that they're working on a security response. Apple has released fixes for its latest M3 and A17 processors, but older devices with previous generations of Apple silicon remain vulnerable. Qualcomm is providing security updates, and AMD plans to offer mitigations through driver updates in March 2024.
First the good news—for this vulnerability to be exploited, it requires the attacker to have access to the target device with the vulnerable GPU (i.e. cut through OS-level security). The attack could break down data silos on modern computers and servers, allowing unauthorized access to GPU memory. The potential data breach could include queries, responses generated by LLMs, and the weights driving the response. The researchers tested 11 chips from seven GPU makers and found the vulnerability in GPUs from Apple, AMD, and Qualcomm. While NVIDIA, Intel, and Arm first-party GPUs did not show evidence of the vulnerability, Apple, Qualcomm, and AMD confirmed to wired that their GPUs are affected, and that they're working on a security response. Apple has released fixes for its latest M3 and A17 processors, but older devices with previous generations of Apple silicon remain vulnerable. Qualcomm is providing security updates, and AMD plans to offer mitigations through driver updates in March 2024.


Apple Wants to Store LLMs on Flash Memory to Bring AI to Smartphones and Laptops
Apple has been experimenting with Large Language Models (LLMs) that power most of today's AI applications. The company wants these LLMs to serve the users best and deliver them efficiently, which is a difficult task as they require a lot of resources, including compute and memory. Traditionally, LLMs have required AI accelerators in combination with large DRAM capacity to store model weights. However, Apple has published a paper that aims to bring LLMs to devices with limited memory capacity. By storing LLMs on NAND flash memory (regular storage), the method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding optimization in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Instead of storing the model weights on DRAM, Apple wants to utilize flash memory to store weights and only pull them on-demand to DRAM once it is needed.
Two principal techniques are introduced within this flash memory-informed framework: "windowing" and "row-column bundling." These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to native loading approaches on CPU and GPU, respectively. Integrating sparsity awareness, context-adaptive loading, and a hardware-oriented design pave the way for practical inference of LLMs on devices with limited memory, such as SoCs with 8/16/32 GB of available DRAM. Especially with DRAM prices outweighing NAND Flash, setups such as smartphone configurations could easily store and inference LLMs with multi-billion parameters, even if the DRAM available isn't sufficient. For a more technical deep dive, read the paper on arXiv here.
Two principal techniques are introduced within this flash memory-informed framework: "windowing" and "row-column bundling." These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to native loading approaches on CPU and GPU, respectively. Integrating sparsity awareness, context-adaptive loading, and a hardware-oriented design pave the way for practical inference of LLMs on devices with limited memory, such as SoCs with 8/16/32 GB of available DRAM. Especially with DRAM prices outweighing NAND Flash, setups such as smartphone configurations could easily store and inference LLMs with multi-billion parameters, even if the DRAM available isn't sufficient. For a more technical deep dive, read the paper on arXiv here.


Phison Predicts 2024: Security is Paramount, PCIe 5.0 NAND Flash Infrastructure Imminent as AI Requires More Balanced AI Data Ecosystem
Phison Electronics Corp., a global leader in NAND flash controller and storage solutions, today announced the company's predictions for 2024 trends in NAND flash infrastructure deployment. The company predicts that rapid proliferation of artificial intelligence (AI) technologies will continue apace, with PCIe 5.0-based infrastructure providing high-performance, sustainable support for AI workload consistency as adoption rapidly expands. PCIe 5.0 NAND flash solutions will be at the core of a well-balanced hardware ecosystem, with private AI deployments such as on-premise large language models (LLMs) driving significant growth in both everyday AI and the infrastructure required to support it.
"We are moving past initial excitement over AI toward wider everyday deployment of the technology. In these configurations, high-quality AI output must be achieved by infrastructure designed to be secure, while also being affordable. The organizations that leverage AI to boost productivity will be incredibly successful," said Sebastien Jean, CTO, Phison US. "Building on the widespread proliferation of AI applications, infrastructure providers will be responsible for making certain that AI models do not run up against the limitations of memory - and NAND flash will become central to how we configure data center architectures to support today's developing AI market while laying the foundation for success in our fast-evolving digital future."
"We are moving past initial excitement over AI toward wider everyday deployment of the technology. In these configurations, high-quality AI output must be achieved by infrastructure designed to be secure, while also being affordable. The organizations that leverage AI to boost productivity will be incredibly successful," said Sebastien Jean, CTO, Phison US. "Building on the widespread proliferation of AI applications, infrastructure providers will be responsible for making certain that AI models do not run up against the limitations of memory - and NAND flash will become central to how we configure data center architectures to support today's developing AI market while laying the foundation for success in our fast-evolving digital future."


Intel's New 5th Gen "Emerald Rapids" Xeon Processors are Built with AI Acceleration in Every Core
Today at the "AI Everywhere" event, Intel launched its 5th Gen Intel Xeon processors (code-named Emerald Rapids) that deliver increased performance per watt and lower total cost of ownership (TCO) across critical workloads for artificial intelligence, high performance computing (HPC), networking, storage, database and security. This launch marks the second Xeon family upgrade in less than a year, offering customers more compute and faster memory at the same power envelope as the previous generation. The processors are software- and platform-compatible with 4th Gen Intel Xeon processors, allowing customers to upgrade and maximize the longevity of infrastructure investments while reducing costs and carbon emissions.
"Designed for AI, our 5th Gen Intel Xeon processors provide greater performance to customers deploying AI capabilities across cloud, network and edge use cases. As a result of our long-standing work with customers, partners and the developer ecosystem, we're launching 5th Gen Intel Xeon on a proven foundation that will enable rapid adoption and scale at lower TCO." -Sandra Rivera, Intel executive vice president and general manager of Data Center and AI Group.

"Designed for AI, our 5th Gen Intel Xeon processors provide greater performance to customers deploying AI capabilities across cloud, network and edge use cases. As a result of our long-standing work with customers, partners and the developer ecosystem, we're launching 5th Gen Intel Xeon on a proven foundation that will enable rapid adoption and scale at lower TCO." -Sandra Rivera, Intel executive vice president and general manager of Data Center and AI Group.


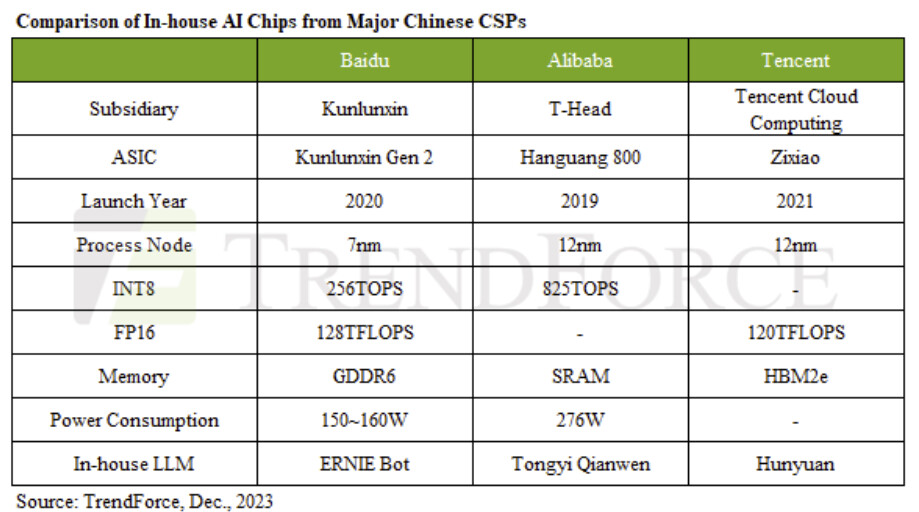
China Continues to Enhance AI Chip Self-Sufficiency, but High-End AI Chip Development Remains Constrained
Huawei's subsidiary HiSilicon has made significant strides in the independent R&D of AI chips, launching the next-gen Ascend 910B. These chips are utilized not only in Huawei's public cloud infrastructure but also sold to other Chinese companies. This year, Baidu ordered over a thousand Ascend 910B chips from Huawei to build approximately 200 AI servers. Additionally, in August, Chinese company iFlytek, in partnership with Huawei, released the "Gemini Star Program," a hardware and software integrated device for exclusive enterprise LLMs, equipped with the Ascend 910B AI acceleration chip, according to TrendForce's research.
TrendForce conjectures that the next-generation Ascend 910B chip is likely manufactured using SMIC's N+2 process. However, the production faces two potential risks. Firstly, as Huawei recently focused on expanding its smartphone business, the N+2 process capacity at SMIC is almost entirely allocated to Huawei's smartphone products, potentially limiting future capacity for AI chips. Secondly, SMIC remains on the Entity List, possibly restricting access to advanced process equipment.
TrendForce conjectures that the next-generation Ascend 910B chip is likely manufactured using SMIC's N+2 process. However, the production faces two potential risks. Firstly, as Huawei recently focused on expanding its smartphone business, the N+2 process capacity at SMIC is almost entirely allocated to Huawei's smartphone products, potentially limiting future capacity for AI chips. Secondly, SMIC remains on the Entity List, possibly restricting access to advanced process equipment.

AWS Unveils Next Generation AWS-Designed Graviton4 and Trainium2 Chips
At AWS re:Invent, Amazon Web Services, Inc. (AWS), an Amazon.com, Inc. company (NASDAQ: AMZN), today announced the next generation of two AWS-designed chip families—AWS Graviton4 and AWS Trainium2—delivering advancements in price performance and energy efficiency for a broad range of customer workloads, including machine learning (ML) training and generative artificial intelligence (AI) applications. Graviton4 and Trainium2 mark the latest innovations in chip design from AWS. With each successive generation of chip, AWS delivers better price performance and energy efficiency, giving customers even more options—in addition to chip/instance combinations featuring the latest chips from third parties like AMD, Intel, and NVIDIA—to run virtually any application or workload on Amazon Elastic Compute Cloud (Amazon EC2).

MediaTek's New Dimensity 8300 Chipset Redefines Premium Experiences in 5G Smartphones
MediaTek today announced the Dimensity 8300, a power-efficient chipset designed for premium 5G smartphones. As the newest SoC in the Dimensity 8000 lineup, this chipset combines generative AI capabilities, low-power savings, adaptive gaming technology, and fast connectivity to bring flagship-level experiences to the premium 5G smartphone segment.
Based on TSMC's 2nd generation 4 nm process, the Dimensity 8300 has an octa-core CPU with four Arm Cortex-A715 cores and four Cortex-A510 cores built on Arm's latest v9 CPU architecture. With this powerful core configuration, the Dimensity 8300 boasts 20% faster CPU performance and 30% peak gains in power efficiency compared to the previous generation chipset. Additionally, the Dimensity 8300's Mali-G615 MC6 GPU upgrade provides up to 60% greater performance and 55% better power efficiency. Plus, the chipset's impressive memory and storage speeds ensure users can enjoy smooth and dynamic experiences in gaming, lifestyle applications, photography, and more.
Based on TSMC's 2nd generation 4 nm process, the Dimensity 8300 has an octa-core CPU with four Arm Cortex-A715 cores and four Cortex-A510 cores built on Arm's latest v9 CPU architecture. With this powerful core configuration, the Dimensity 8300 boasts 20% faster CPU performance and 30% peak gains in power efficiency compared to the previous generation chipset. Additionally, the Dimensity 8300's Mali-G615 MC6 GPU upgrade provides up to 60% greater performance and 55% better power efficiency. Plus, the chipset's impressive memory and storage speeds ensure users can enjoy smooth and dynamic experiences in gaming, lifestyle applications, photography, and more.


SK hynix Showcases Next-Gen AI and HPC Solutions at SC23
SK hynix presented its leading AI and high-performance computing (HPC) solutions at Supercomputing 2023 (SC23) held in Denver, Colorado between November 12-17. Organized by the Association for Computing Machinery and IEEE Computer Society since 1988, the annual SC conference showcases the latest advancements in HPC, networking, storage, and data analysis. SK hynix marked its first appearance at the conference by introducing its groundbreaking memory solutions to the HPC community. During the six-day event, several SK hynix employees also made presentations revealing the impact of the company's memory solutions on AI and HPC.
Displaying Advanced HPC & AI Products
At SC23, SK hynix showcased its products tailored for AI and HPC to underline its leadership in the AI memory field. Among these next-generation products, HBM3E attracted attention as the HBM solution meets the industry's highest standards of speed, capacity, heat dissipation, and power efficiency. These capabilities make it particularly suitable for data-intensive AI server systems. HBM3E was presented alongside NVIDIA's H100, a high-performance GPU for AI that uses HBM3 for its memory.




Displaying Advanced HPC & AI Products
At SC23, SK hynix showcased its products tailored for AI and HPC to underline its leadership in the AI memory field. Among these next-generation products, HBM3E attracted attention as the HBM solution meets the industry's highest standards of speed, capacity, heat dissipation, and power efficiency. These capabilities make it particularly suitable for data-intensive AI server systems. HBM3E was presented alongside NVIDIA's H100, a high-performance GPU for AI that uses HBM3 for its memory.





Dropbox and NVIDIA Team to Bring Personalized Generative AI to Millions of Customers
Today, Dropbox, Inc. and NVIDIA announced a collaboration to supercharge knowledge work and improve productivity for millions of Dropbox customers through the power of AI. The companies' collaboration will expand Dropbox's extensive AI functionality with new uses for personalized generative AI to improve search accuracy, provide better organization, and simplify workflows for its customers across their cloud content.
Dropbox plans to leverage NVIDIA's AI foundry consisting of NVIDIA AI Foundation Models, NVIDIA AI Enterprise software and NVIDIA accelerated computing to enhance its latest AI-powered product experiences. These include Dropbox Dash, universal search that connects apps, tools, and content in a single search bar to help customers find what they need; Dropbox AI, a tool that allows customers to ask questions and get summaries on large files across their entire Dropbox; among other AI capabilities in Dropbox.
Dropbox plans to leverage NVIDIA's AI foundry consisting of NVIDIA AI Foundation Models, NVIDIA AI Enterprise software and NVIDIA accelerated computing to enhance its latest AI-powered product experiences. These include Dropbox Dash, universal search that connects apps, tools, and content in a single search bar to help customers find what they need; Dropbox AI, a tool that allows customers to ask questions and get summaries on large files across their entire Dropbox; among other AI capabilities in Dropbox.

NVIDIA Introduces Generative AI Foundry Service on Microsoft Azure for Enterprises and Startups Worldwide
NVIDIA today introduced an AI foundry service to supercharge the development and tuning of custom generative AI applications for enterprises and startups deploying on Microsoft Azure.
The NVIDIA AI foundry service pulls together three elements—a collection of NVIDIA AI Foundation Models, NVIDIA NeMo framework and tools, and NVIDIA DGX Cloud AI supercomputing services—that give enterprises an end-to-end solution for creating custom generative AI models. Businesses can then deploy their customized models with NVIDIA AI Enterprise software to power generative AI applications, including intelligent search, summarization and content generation.
The NVIDIA AI foundry service pulls together three elements—a collection of NVIDIA AI Foundation Models, NVIDIA NeMo framework and tools, and NVIDIA DGX Cloud AI supercomputing services—that give enterprises an end-to-end solution for creating custom generative AI models. Businesses can then deploy their customized models with NVIDIA AI Enterprise software to power generative AI applications, including intelligent search, summarization and content generation.

NVIDIA Announces up to 5x Faster TensorRT-LLM for Windows, and ChatGPT API-like Interface
Even as CPU vendors are working to mainstream accelerated AI for client PCs, and Microsoft setting the pace for more AI in everyday applications with Windows 11 23H2 Update; NVIDIA is out there reminding you that every GeForce RTX GPU is an AI accelerator. This is thanks to its Tensor cores, and the SIMD muscle of the ubiquitous CUDA cores. NVIDIA has been making these for over 5 years now, and has an install base of over 100 million. The company is hence focusing on bring generative AI acceleration to more client- and enthusiast relevant use-cases, such as large language models.
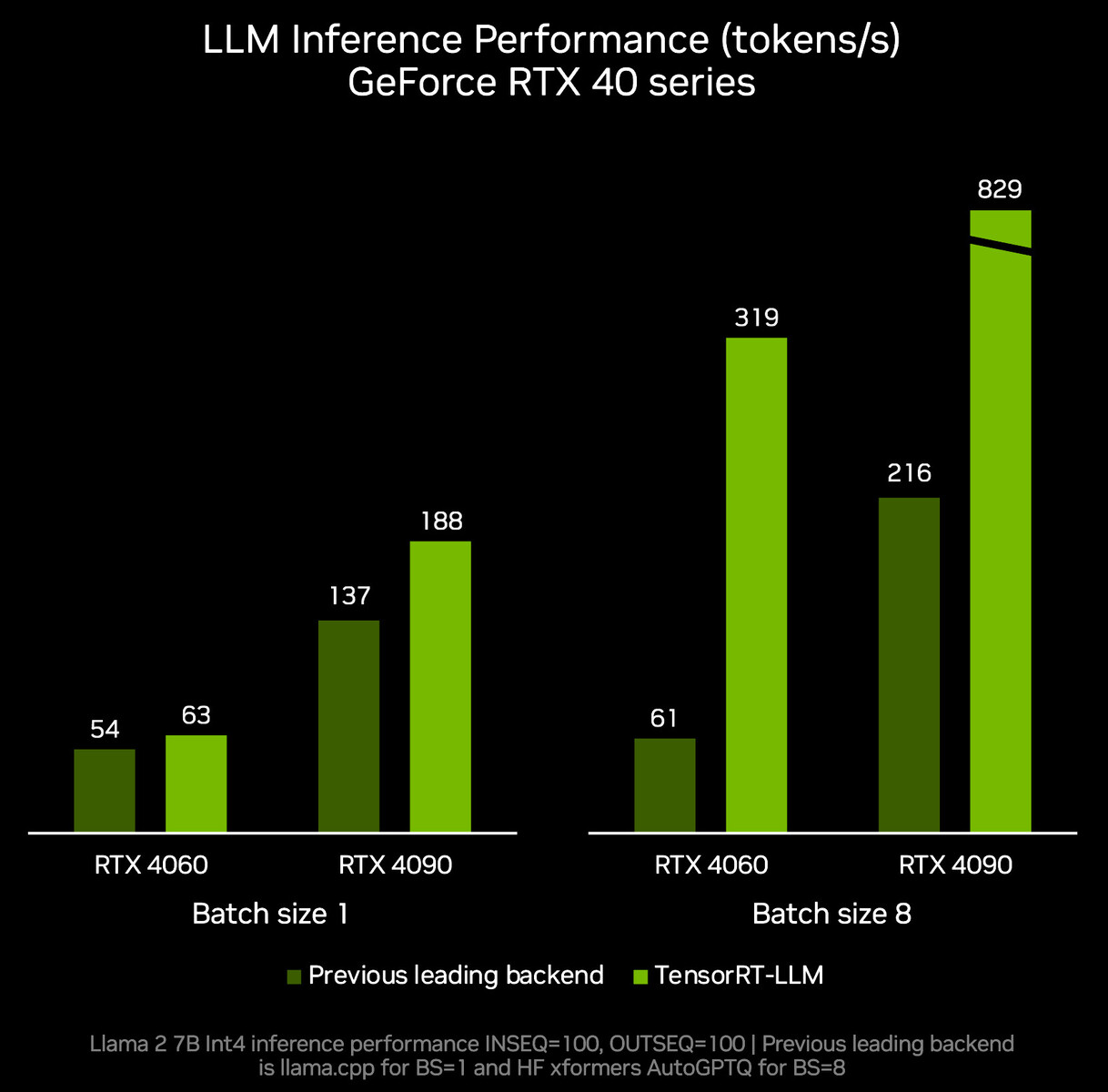
NVIDIA at the Microsoft Ignite event announced new optimizations, models, and resources to bring accelerated AI to everyone with an NVIDIA GPU that meets the hardware requirements. To begin with, the company introduced an update to TensorRT-LLM for Windows, a library that leverages NVIDIA RTX architecture for accelerating large language models (LLMs). The new TensorRT-LLM version 0.6.0 will release later this month, and improve LLM inference performance by up to 5 times in terms of tokens per second, when compared to the initial release of TensorRT-LLM from October 2023. In addition, TensorRT-LLM 0.6.0 will introduce support for popular LLMs, including Mistral 7B and Nemtron-3 8B. Accelerating these two will require a GeForce RTX 30-series "Ampere" or 40-series "Ada" GPU with at least 8 GB of main memory.

NVIDIA at the Microsoft Ignite event announced new optimizations, models, and resources to bring accelerated AI to everyone with an NVIDIA GPU that meets the hardware requirements. To begin with, the company introduced an update to TensorRT-LLM for Windows, a library that leverages NVIDIA RTX architecture for accelerating large language models (LLMs). The new TensorRT-LLM version 0.6.0 will release later this month, and improve LLM inference performance by up to 5 times in terms of tokens per second, when compared to the initial release of TensorRT-LLM from October 2023. In addition, TensorRT-LLM 0.6.0 will introduce support for popular LLMs, including Mistral 7B and Nemtron-3 8B. Accelerating these two will require a GeForce RTX 30-series "Ampere" or 40-series "Ada" GPU with at least 8 GB of main memory.

Lenovo Announces the ThinkStation P8 Powered by AMD Ryzen Threadripper PRO 7000 WX-Series and NVIDIA RTX Graphics
Today, Lenovo announced the new ThinkStation P8 tower workstation powered by AMD Ryzen Threadripper PRO 7000 WX-Series processors and NVIDIA RTX GPUs. Designed to deliver unparalleled performance, reliability and flexibility for professionals who demand the best from their workstations, the bold new ThinkStation P8 builds on the success of the award-winning P620, the world's first workstation powered by AMD Ryzen Threadripper PRO processors. Featuring an optimized thermal design in a versatile Aston Martin inspired chassis, the ThinkStation P8 combines Lenovo's legendary reliability, customer experience and innovation with breakthrough compute architecture courtesy of AMD and NVIDIA. ThinkStation P8 raises the bar for intense workloads across multiple segments focused on outcome-based workflow agility.
"At Lenovo, we understand that our customers need high-quality workstations that can adapt to their changing and diverse needs. That's why we collaborated with AMD and NVIDIA to create the ThinkStation P8, a workstation that combines power, flexibility and enterprise-grade features," said Rob Herman, vice president and general manager, Workstation and Client AI Business Unit, Lenovo. "Designed to offer unparalleled performance and scalability, whether to run complex simulations, render stunning visuals, or develop cutting-edge AI applications, the ThinkStation P8 can handle it all. And with Lenovo's certifications, security and support, you can trust that the ThinkStation P8 will exceed expectations."




"At Lenovo, we understand that our customers need high-quality workstations that can adapt to their changing and diverse needs. That's why we collaborated with AMD and NVIDIA to create the ThinkStation P8, a workstation that combines power, flexibility and enterprise-grade features," said Rob Herman, vice president and general manager, Workstation and Client AI Business Unit, Lenovo. "Designed to offer unparalleled performance and scalability, whether to run complex simulations, render stunning visuals, or develop cutting-edge AI applications, the ThinkStation P8 can handle it all. And with Lenovo's certifications, security and support, you can trust that the ThinkStation P8 will exceed expectations."





Supermicro Expands AI Solutions with the Upcoming NVIDIA HGX H200 and MGX Grace Hopper Platforms Featuring HBM3e Memory
Supermicro, Inc., a Total IT Solution Provider for AI, Cloud, Storage, and 5G/Edge, is expanding its AI reach with the upcoming support for the new NVIDIA HGX H200 built with H200 Tensor Core GPUs. Supermicro's industry leading AI platforms, including 8U and 4U Universal GPU Systems, are drop-in ready for the HGX H200 8-GPU, 4-GPU, and with nearly 2x capacity and 1.4x higher bandwidth HBM3e memory compared to the NVIDIA H100 Tensor Core GPU. In addition, the broadest portfolio of Supermicro NVIDIA MGX systems supports the upcoming NVIDIA Grace Hopper Superchip with HBM3e memory. With unprecedented performance, scalability, and reliability, Supermicro's rack scale AI solutions accelerate the performance of computationally intensive generative AI, large language Model (LLM) training, and HPC applications while meeting the evolving demands of growing model sizes. Using the building block architecture, Supermicro can quickly bring new technology to market, enabling customers to become more productive sooner.
Supermicro is also introducing the industry's highest density server with NVIDIA HGX H100 8-GPUs systems in a liquid cooled 4U system, utilizing the latest Supermicro liquid cooling solution. The industry's most compact high performance GPU server enables data center operators to reduce footprints and energy costs while offering the highest performance AI training capacity available in a single rack. With the highest density GPU systems, organizations can reduce their TCO by leveraging cutting-edge liquid cooling solutions.
Supermicro is also introducing the industry's highest density server with NVIDIA HGX H100 8-GPUs systems in a liquid cooled 4U system, utilizing the latest Supermicro liquid cooling solution. The industry's most compact high performance GPU server enables data center operators to reduce footprints and energy costs while offering the highest performance AI training capacity available in a single rack. With the highest density GPU systems, organizations can reduce their TCO by leveraging cutting-edge liquid cooling solutions.

NVIDIA Turbocharges Generative AI Training in MLPerf Benchmarks
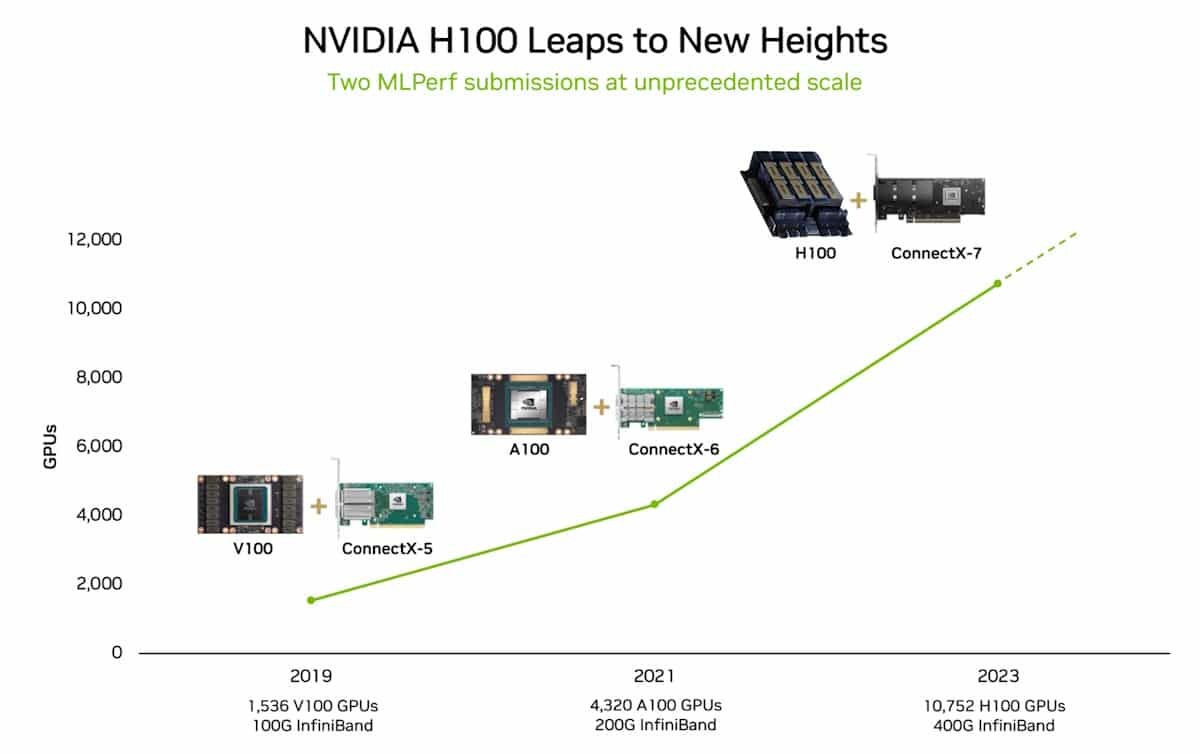
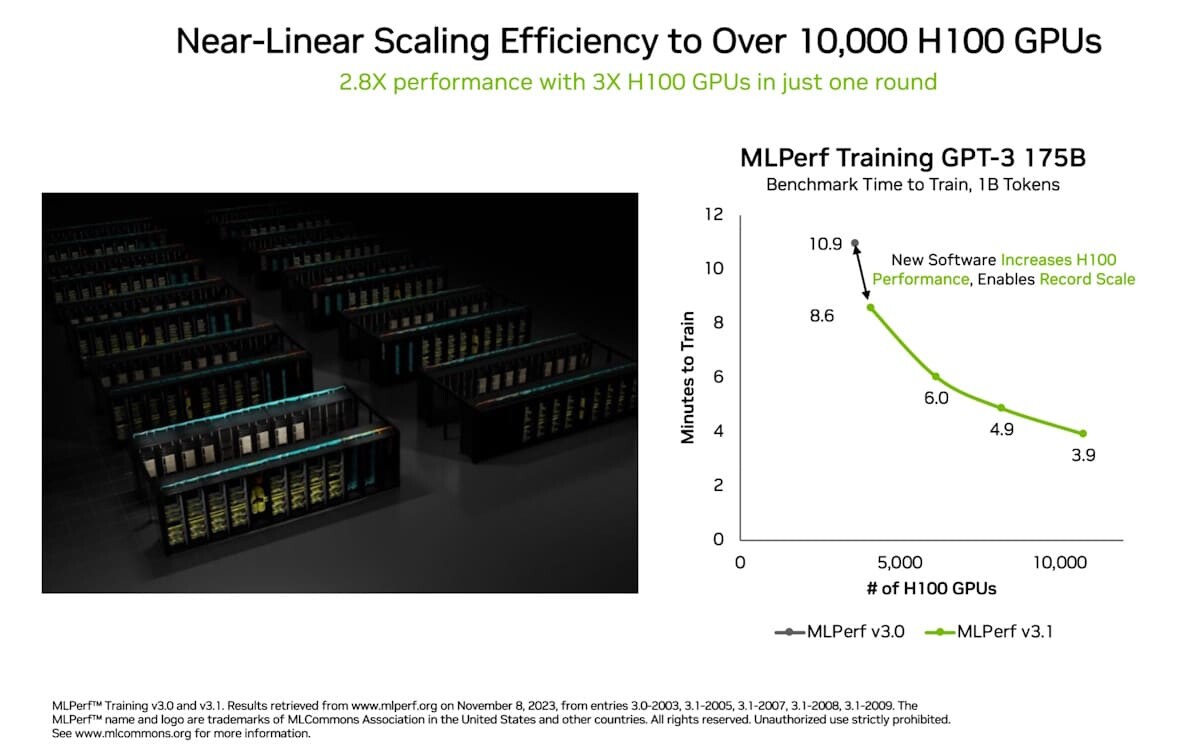
NVIDIA's AI platform raised the bar for AI training and high performance computing in the latest MLPerf industry benchmarks. Among many new records and milestones, one in generative AI stands out: NVIDIA Eos - an AI supercomputer powered by a whopping 10,752 NVIDIA H100 Tensor Core GPUs and NVIDIA Quantum-2 InfiniBand networking - completed a training benchmark based on a GPT-3 model with 175 billion parameters trained on one billion tokens in just 3.9 minutes. That's a nearly 3x gain from 10.9 minutes, the record NVIDIA set when the test was introduced less than six months ago.
The benchmark uses a portion of the full GPT-3 data set behind the popular ChatGPT service that, by extrapolation, Eos could now train in just eight days, 73x faster than a prior state-of-the-art system using 512 A100 GPUs. The acceleration in training time reduces costs, saves energy and speeds time-to-market. It's heavy lifting that makes large language models widely available so every business can adopt them with tools like NVIDIA NeMo, a framework for customizing LLMs. In a new generative AI test this round, 1,024 NVIDIA Hopper architecture GPUs completed a training benchmark based on the Stable Diffusion text-to-image model in 2.5 minutes, setting a high bar on this new workload. By adopting these two tests, MLPerf reinforces its leadership as the industry standard for measuring AI performance, since generative AI is the most transformative technology of our time.



The benchmark uses a portion of the full GPT-3 data set behind the popular ChatGPT service that, by extrapolation, Eos could now train in just eight days, 73x faster than a prior state-of-the-art system using 512 A100 GPUs. The acceleration in training time reduces costs, saves energy and speeds time-to-market. It's heavy lifting that makes large language models widely available so every business can adopt them with tools like NVIDIA NeMo, a framework for customizing LLMs. In a new generative AI test this round, 1,024 NVIDIA Hopper architecture GPUs completed a training benchmark based on the Stable Diffusion text-to-image model in 2.5 minutes, setting a high bar on this new workload. By adopting these two tests, MLPerf reinforces its leadership as the industry standard for measuring AI performance, since generative AI is the most transformative technology of our time.


MediaTek Announces the Dimensity 9300 Flagship SoC, with Big Cores Only
MediaTek today announced the Dimensity 9300, its newest flagship mobile chip with a one-of-a-kind All Big Core design. The unique configuration combines extreme performance with MediaTek's industry-leading power efficiency to deliver unmatched user experiences in gaming, video capture and on-device generative AI processing.
"The Dimensity 9300 is MediaTek's most powerful flagship chip yet, bringing a huge boost in raw computing power to flagship smartphones with our groundbreaking All Big Core design," said Joe Chen, President at MediaTek. "This unique architecture, combined with our upgraded on-chip AI Processing Unit, will usher in a new era of generative AI applications as developers push the limits with edge AI and hybrid AI computing capabilities."
"The Dimensity 9300 is MediaTek's most powerful flagship chip yet, bringing a huge boost in raw computing power to flagship smartphones with our groundbreaking All Big Core design," said Joe Chen, President at MediaTek. "This unique architecture, combined with our upgraded on-chip AI Processing Unit, will usher in a new era of generative AI applications as developers push the limits with edge AI and hybrid AI computing capabilities."

Mar 28th, 2025 08:10 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Post your CrystalDiskMark speeds (616)
- Will you buy a RTX 5090? (455)
- Technical Issues - TPU Main Site & Forum (2025) (81)
- Should you physically remove secondary NVMe drives when performing a clean Windows install? (40)
- AMD RX 9070 XT & RX 9070 non-XT thread (OC, undervolt, benchmarks, ...) (64)
- Future-proofing my OLED (33)
- RTX 3050 with GA107 GPU incomplete information and sensor issue. (0)
- Post your Monster Hunter Wilds benchmark scores (151)
- Compatibility With Alphacool Core RX 9070 XT Taichi GPU WaterBlock ?? (0)
- Recommended PhysX card for 5xxx series? [Is vRAM relevant?] (226)
Popular Reviews
- Sapphire Radeon RX 9070 XT Pulse Review
- Samsung 9100 Pro 2 TB Review - The Best Gen 5 SSD
- Assassin's Creed Shadows Performance Benchmark Review - 30 GPUs Compared
- Pulsar Feinmann F01 Review
- ASRock Phantom Gaming B860I Lightning Wi-Fi Review
- be quiet! Pure Rock Pro 3 Black Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- ASRock Radeon RX 9070 XT Taichi OC Review - Excellent Cooling
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- ASUS ProArt X870E-Creator Wi-Fi Review
Controversial News Posts
- AMD RDNA 4 and Radeon RX 9070 Series Unveiled: $549 & $599 (260)
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (142)
- Microsoft Introduces Copilot for Gaming (123)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (118)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (96)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)