NUDT MT-3000 Hybrid CPU Reportedly Utilized by Tianhe-3 Supercomputer
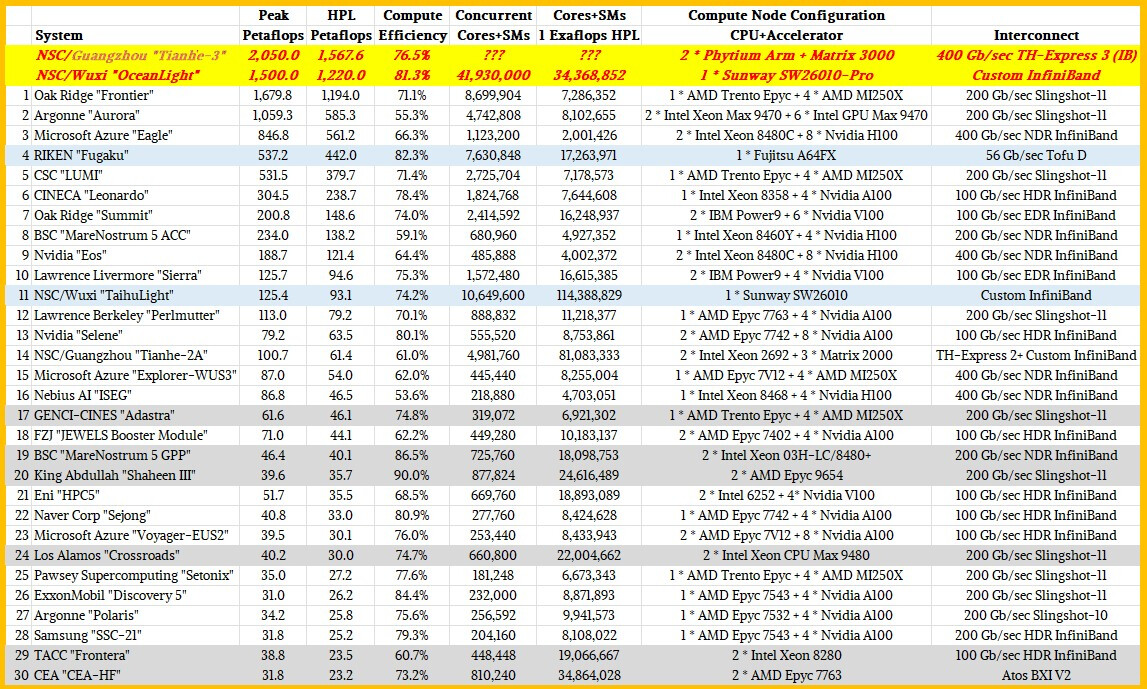
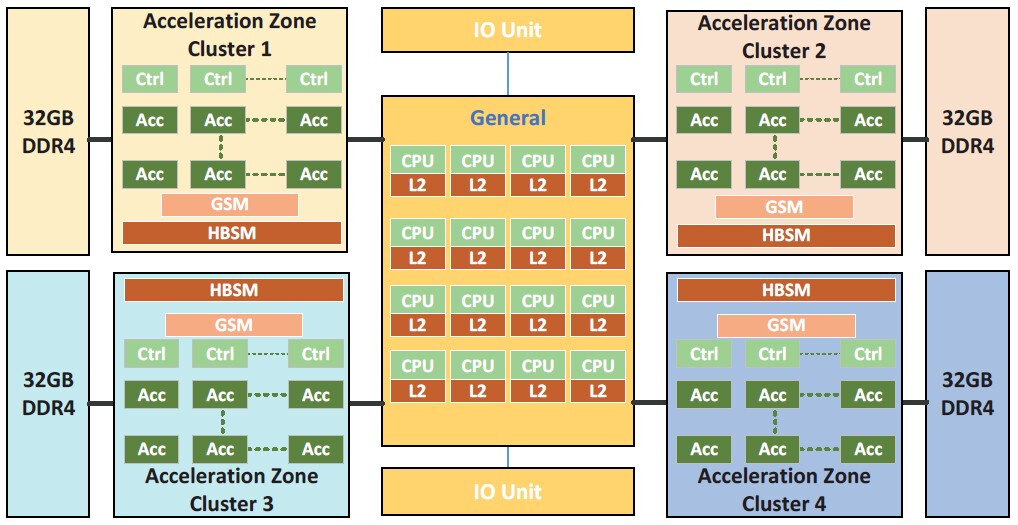
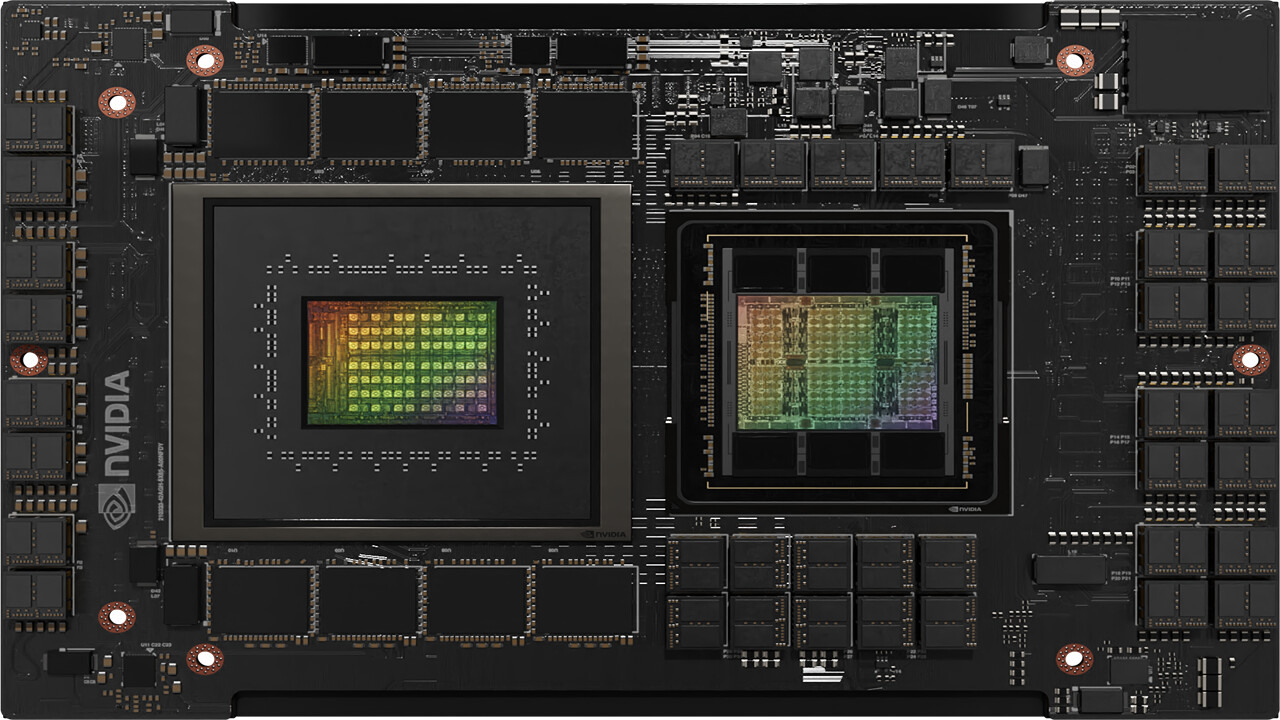
China's National Supercomputer Center (NUDT) introduced their Tianhe-3 system as a prototype back in early 2019—at the time it had been tested by thirty local organizations. Notable assessors included the Chinese Academy of Sciences and the China Aerodynamics Research and Development Center. The (previous generation) Tianhe-2 system currently sits in a number seven position of world-ranked Supercomputers—offering a measured performance of 33.86 petaFLOPS/s. The internal makeup of its fully formed successor has remained a mystery...until now. The Next Platform believes that the "Xingyi" monikered third generation supercomputer houses the Guangzhou-based lab's MT-3000 processor design. Author, Timothy Prickett Morgan, boasted about acquiring exclusive inside knowledge ahead of international intelligence agencies—many will be keeping an eye on the NUDT, since it is administered by the National University of Defence Technology (itself owned by the Chinese government).
The Next Platform has a track record of outing intimate details relating to Chinese-developed scientific breakthroughs—the semi-related "Oceanlight" system installed at their National Supercomputer Center (Wuxi) was "figured out" two years ago. Tianhe-3 and Oceanlight face significant competition in the form of "El Capitan"—this is the USA's prime: "supercomputer being built right now at Lawrence Livermore National Laboratory by Hewlett Packard Enterprise in conjunction with compute engine supplier AMD. We need to know because we want to understand the very different—and yet, in some ways similar—architectural path that China seems to have taken with the Xingyi architecture to break through the exascale barrier."



The Next Platform has a track record of outing intimate details relating to Chinese-developed scientific breakthroughs—the semi-related "Oceanlight" system installed at their National Supercomputer Center (Wuxi) was "figured out" two years ago. Tianhe-3 and Oceanlight face significant competition in the form of "El Capitan"—this is the USA's prime: "supercomputer being built right now at Lawrence Livermore National Laboratory by Hewlett Packard Enterprise in conjunction with compute engine supplier AMD. We need to know because we want to understand the very different—and yet, in some ways similar—architectural path that China seems to have taken with the Xingyi architecture to break through the exascale barrier."