On NVIDIA's Tile-Based Rendering
Looking back on NVIDIA's GDC presentation, perhaps one of the most interesting aspects approached was the implementation of tile-based rendering on NVIDIA's post-Maxwell architectures. This has been an adaptation of typically mobile approaches to graphics rendering which keeps their specific needs for power efficiency in mind - and if you'll "member", "Maxwell" was NVIDIA's first graphics architecture publicly touted for its "mobile first" design.
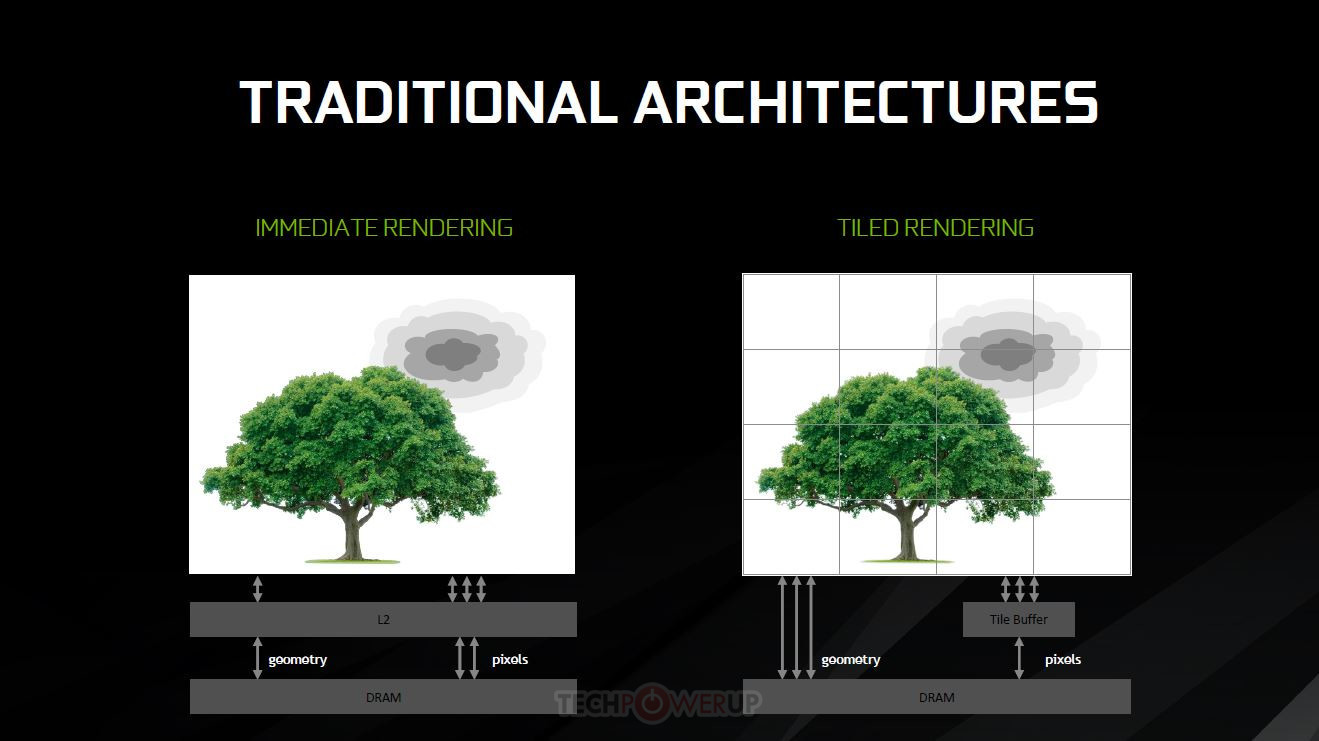
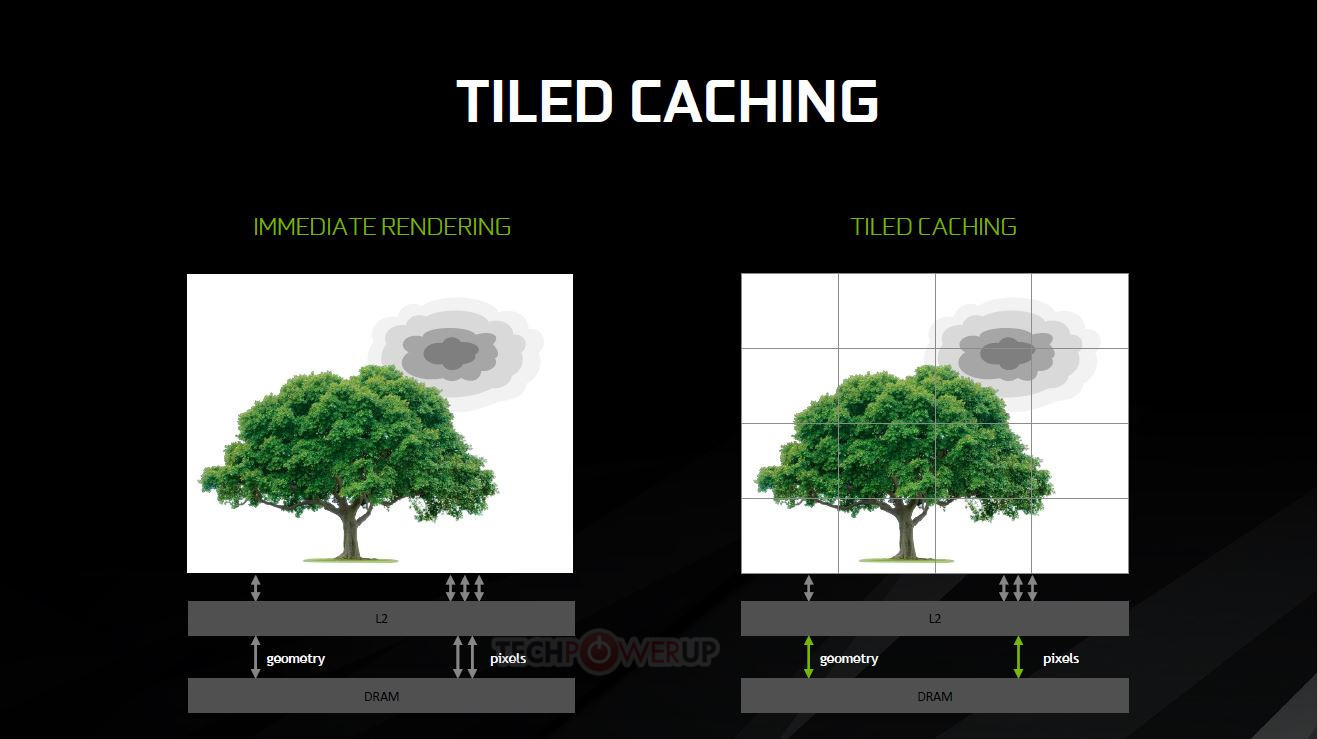
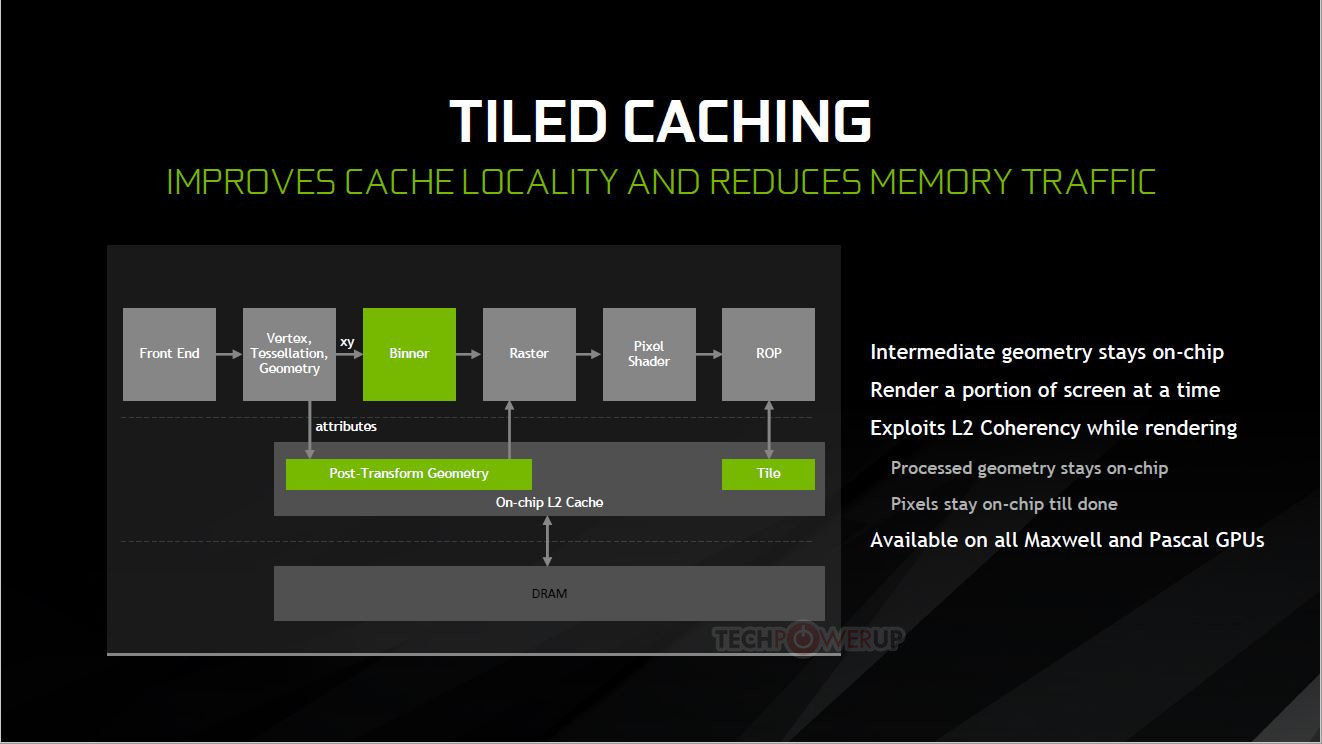
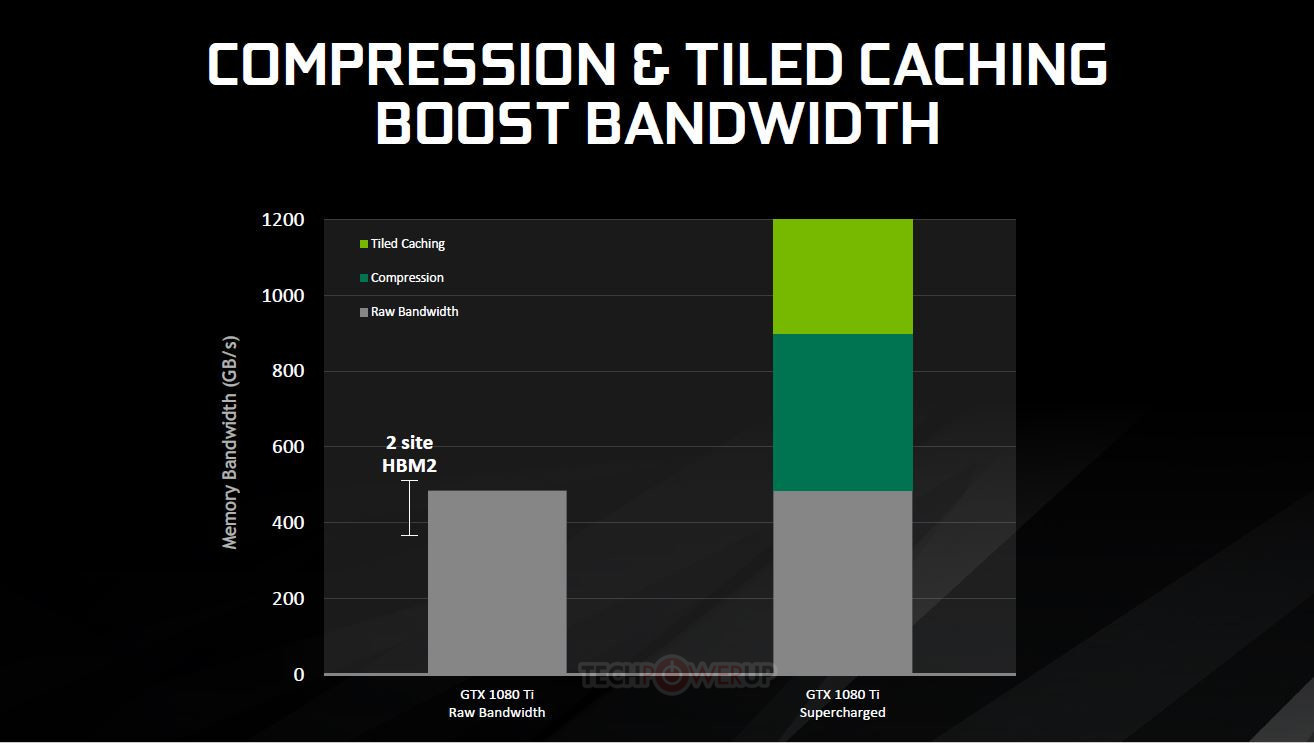
This approach essentially divides the screen into tiles, and then rasterizes the entire frame in a per-tile basis. 16×16 and 32×32 pixels are the usual tile sizes, but both Maxwell and Pascal can dynamically assess the required tile size for each frame, changing it on-the-fly as needed and according to the complexity of the scene. This looks to ensure that the processed data has a much smaller footprint than that of the full image rendering - small enough that it makes it possible for NVIDIA to keep the data in a much smaller amount of memory (essentially, the L2 memory), dynamically filling and flushing the available cache as possible until the full frame has been rendered. This means that the GPU doesn't have to access larger, slower memory pools as much, which primarily reduces the load on the VRAM subsystem (increasing available VRAM for other tasks), whilst simultaneously accelerating rendering speed. At the same time, a tile-based approach also lends itself pretty well to the nature of GPUs - these are easily parallelized operations, with the GPU being able to tackle many independent tiles simultaneously, depending on the available resources.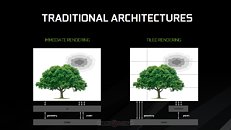
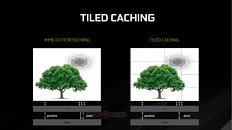


This approach essentially divides the screen into tiles, and then rasterizes the entire frame in a per-tile basis. 16×16 and 32×32 pixels are the usual tile sizes, but both Maxwell and Pascal can dynamically assess the required tile size for each frame, changing it on-the-fly as needed and according to the complexity of the scene. This looks to ensure that the processed data has a much smaller footprint than that of the full image rendering - small enough that it makes it possible for NVIDIA to keep the data in a much smaller amount of memory (essentially, the L2 memory), dynamically filling and flushing the available cache as possible until the full frame has been rendered. This means that the GPU doesn't have to access larger, slower memory pools as much, which primarily reduces the load on the VRAM subsystem (increasing available VRAM for other tasks), whilst simultaneously accelerating rendering speed. At the same time, a tile-based approach also lends itself pretty well to the nature of GPUs - these are easily parallelized operations, with the GPU being able to tackle many independent tiles simultaneously, depending on the available resources.