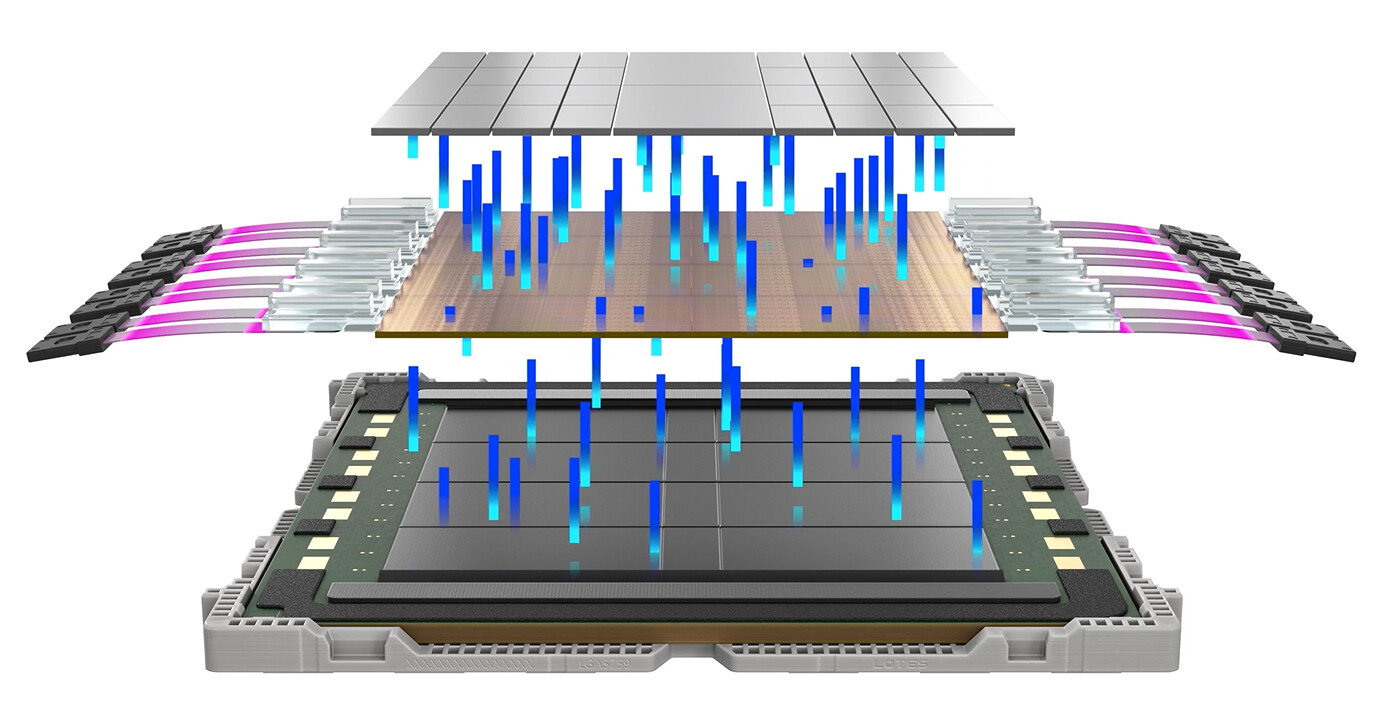
Synopsys Accelerates AI and Multi-Die Design Innovation on Advanced Samsung Foundry Processes
Synopsys, Inc. announced today its ongoing close collaboration with Samsung Foundry to power the next generation of designs for advanced edge AI, HPC, and AI applications. The collaboration between the companies is helping mutual customers achieve successful tape-outs of their complex designs using Synopsys' 3DIC Compiler and Samsung's advanced packaging technologies with fast turnaround time. Mutual customers can improve power, performance and area (PPA) with certified EDA flows for SF2P process, and minimize IP integration risk with the high-quality portfolio of IP on Samsung's most advanced process technologies.
"The adoption of Edge AI applications is driving the need for advancements in semiconductor technologies to enable complex computational tasks, improve efficiency, and expand AI capabilities across various industries and applications," said John Koeter, senior vice president for the Synopsys IP Group. "Together with Samsung Foundry, we're enabling the most advanced AI processors across a broad spectrum of use cases from high-performance AI inference engines for data centers to ultra-efficient Edge AI devices like cameras and drones, all optimized for development on sub-2 nm Samsung Foundry process technologies."
"The adoption of Edge AI applications is driving the need for advancements in semiconductor technologies to enable complex computational tasks, improve efficiency, and expand AI capabilities across various industries and applications," said John Koeter, senior vice president for the Synopsys IP Group. "Together with Samsung Foundry, we're enabling the most advanced AI processors across a broad spectrum of use cases from high-performance AI inference engines for data centers to ultra-efficient Edge AI devices like cameras and drones, all optimized for development on sub-2 nm Samsung Foundry process technologies."