 29
29
AMD EPYC Architecture & Technical Overview
(29 Comments) »Introduction
AMD put nearly all their eggs in the Zen architecture bucket after having given up years of market share to Intel in the consumer, HEDT, and even server industry market segments. To many, this was a massive risk considering the ~40% IPC increase promised (and required to compete), but with the Ryzen desktop processors, AMD showed that they did achieve that and more. Ryzen CPUs introduced up to 8 cores and16 threads to customers previously getting half that number from Intel and carved out a place in the market thanks to their price/performance ratio, especially with applications that take advantage of parallel workload processing.
With their upcoming Threadripper series, AMD is making use of their new Infinity Fabric design to essentially put the equivalent of up to two 8-core CPUs into one massive package. Featuring up to 16 cores and 32 threads due to their Simultaneous Multithreading (SMT), AMD will challenge Intel for the HEDT platform for the prosumer and professional alike. While that is upcoming still, AMD today took the wraps off their solution for the datacenter and server market.
The words "EPYC" and "32C/64T" were in high flow in the PC tech press media coverage since before Computex even, and with the launch today, we get detailed information on the EPYC platform and all optimizations AMD has done.

This article aims to bring forth the salient features of the EPYC server architecture. We will go over the lineup, take a closer look at the new "Zen" core design, understand better how the memory and IO connectivity work, and describe the new security features. As such, we thank AMD for providing said information. Let us begin with a look at the entire EPYC CPU lineup now.
The Lineup


AMD has announced a plethora of both 2P and 1P socket CPUs under the EPYC brand today, with the 2P system CPUs beginning with the EPYC 7251 8C/16T 120 W TDP CPU and culminating in the powerhouse EPYC 7601 32C/64T 180 W TDP CPU. There are thus a total of nine 2P offerings with core counts ranging from 8 to 32, and all of them offer 128 PCIe Gen 3.0 lanes with support for 8-channels of DDR4 2667 MHz system memory (up to 2 TB per CPU). Note the varying TDP for some of the SKUs - this is a result of the increased control over the performance/power balance across the entire system.
The 1P system CPUs are arguably even more interesting, albeit fewer in number. We get the same 8-channel DDR4 memory and 128 PCIe lane support here, meaning there is 2P feature set support with the 1P systems as well. The three offerings have core counts ranging from 16 to 32 with the top-end SKU having a slightly smaller boost clock compared to the 2P flagship.

We now have pricing and retail availability information for most of the SKUs, and it has been tabulated above. AMD is hitting Intel's respective competition at a lower price point here.
Core Design & Cache System
The new so-called "Zen" architecture was designed from the ground up with datacenters in mind, for optimal balance of performance and power, and has four key points we will be exploring:- New high-performance core design
- New high bandwidth, low latency cache system
- Simultaneous Multithreading (SMT)
- Energy efficient 14 nm FinFET process

There are similarities with the Zen microarchitecture used in Ryzen, but I see more differences at the same time. As a quick summary, this new core design can fetch and decode four x86 assembler instructions per cycle. Like on all modern CPU designs, the x86 instructions are broken down into a sequence of micro-ops, which can be processed more efficiently. In order to accelerate this process, Zen includes Op Cache capable of storing 2K instructions.
The left side of the diagram shows the integer machinery, which contains four integer units with a total of 168 registers capable of 192 simultaneous instructions, two load/store units with support for up to 72 out-of-order loads and smart prefetch.
The right side of the diagram contains two floating point units with 128 FMACs (fused multiply-accumulate execution units) for compute. The floating point units are built as four pipes with two Fadd and Fmul operation units and have dual AES (advanced encryption standard) units to aid in fast single-threaded performance or increase SMT-based throughput with SHA (secure hash algorithm) encryption support for SHA-1 and SHA-256 algorithms.


The cache system here has four sub-components:
- 4-way. 64 KB I-cache (Instruction cache)
- 8-way, 32 KB D-cache (Data cache)
- 8-way, 512 KB L2 cache
- Large shared 2 MB/core L3 cache
The L3 cache is shared as part of a CPU complex (CCX) comprised of four cores connected to a L3 cache (shared, total of 8 MB per CCX). This L3 cache is made out of four slices, 16-way associative and mostly exclusive of L2. The association works such that each core can access every cache with the same average latency.

As an example, AMD has provided details on how a neural net prediction would work with this new core and cache design. We see here the prediction of two branches per cycle; a large L1/L2 branch target buffer, 32 entry-return stack (large, good for VM), and 512 entry ITA (indirect target array) are all capable of predicting multiple targets from the same branch.

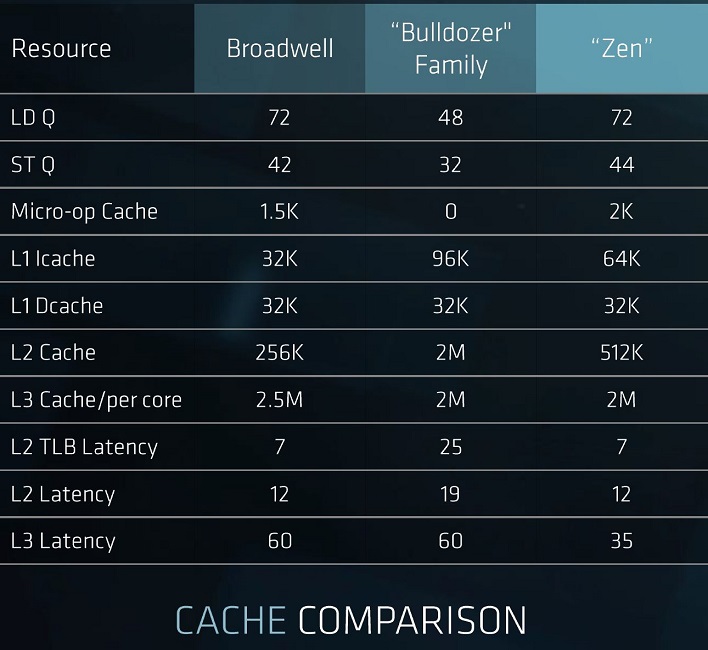
Here's a quick comparison of the core design and cache systems for AMD "Bulldozer" and "Zen" based microarchitectures and Intel's Broadwell-E/EP families. Note that Intel still has to unveil their 2017 Skylake Purley architecture, so what we are seeing from AMD today will have to compete against that as well.
Our Patreon Silver Supporters can read articles in single-page format.
Apr 3rd, 2025 03:25 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- NZXT N9 X870E is out (despite their website still saying: coming soon) (9)
- A slightly strange problem with a GPU (10)
- RX 9000 series GPU Owners Club (116)
- Mllse 6600s that are locked at 500 mhz. (1)
- Since all gpu's models perform the same, why review dozen of different models? (4)
- Is RX 9070 VRAM temperature regular value or hotspot? (298)
- TechPowerUp Screenshot Thread (MASSIVE 56K WARNING) (4266)
- Windows 11 General Discussion (5917)
- Montech KING 95 - your opinions? (14)
- New AM5 build [help] (14)
Popular Reviews
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- Sapphire Radeon RX 9070 XT Pulse Review
- SilverStone Lucid 04 Review
- PowerColor Radeon RX 9070 Hellhound Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- ASRock Phantom Gaming B850 Riptide Wi-Fi Review - Amazing Price/Performance
- Palit GeForce RTX 5070 GamingPro OC Review
- Pwnage Trinity CF Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Samsung 9100 Pro 2 TB Review - The Best Gen 5 SSD
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (96)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)
- China Develops Domestic EUV Tool, ASML Monopoly in Trouble (88)