 115
115
Intel Lunar Lake Technical Deep Dive - So many Revolutions in One Chip
Connectivity & IO »Intel NPU 4 Makes Lunar Lake Copilot+ Ready


This is Intel's second processor generation to feature a neural processing unit (NPU), a component that efficiently accelerates AI, however, Intel is referring to the one in Lunar Lake as NPU 4. This is because it's counting its pre-NPU AI acceleration hardware implementations, such as GFNI and AVX512 or VNNI, as primordial NPUs, even though you can't get any of today's NPU-specific workloads to work on them.

The big story here is that the NPU 4 powering Lunar Lake has four times the AI inferencing performance as the NPU 3 found in Meteor Lake. The AI inferencing performance leaps from 12 TOPS in Meteor Lake, to 48 TOPS on Lunar Lake. This meets and exceeds the 40 TOPS requirement set by Microsoft to accelerate local sessions of Copilot+, and qualify for the Copilot+ AI PC certification.
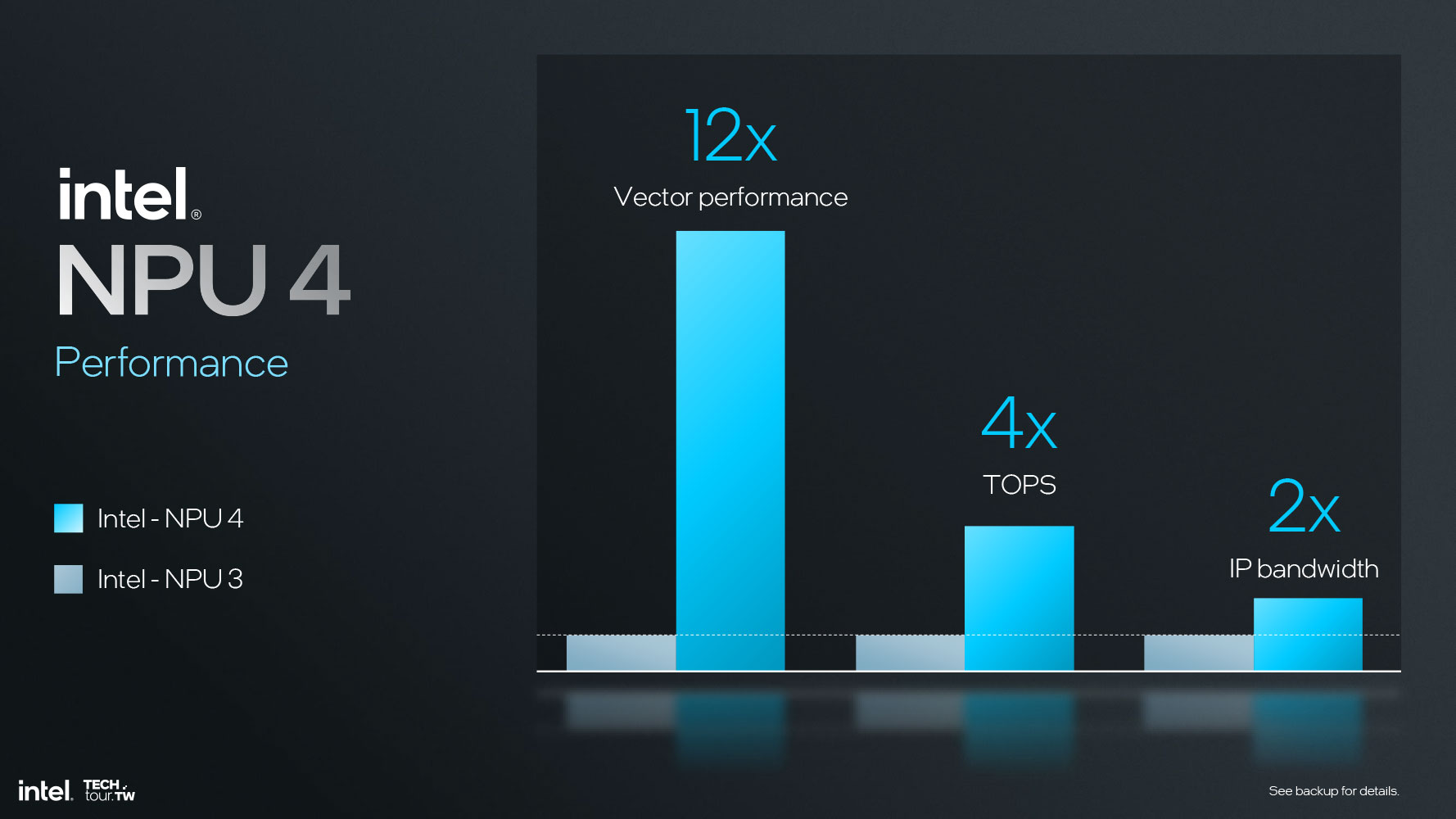
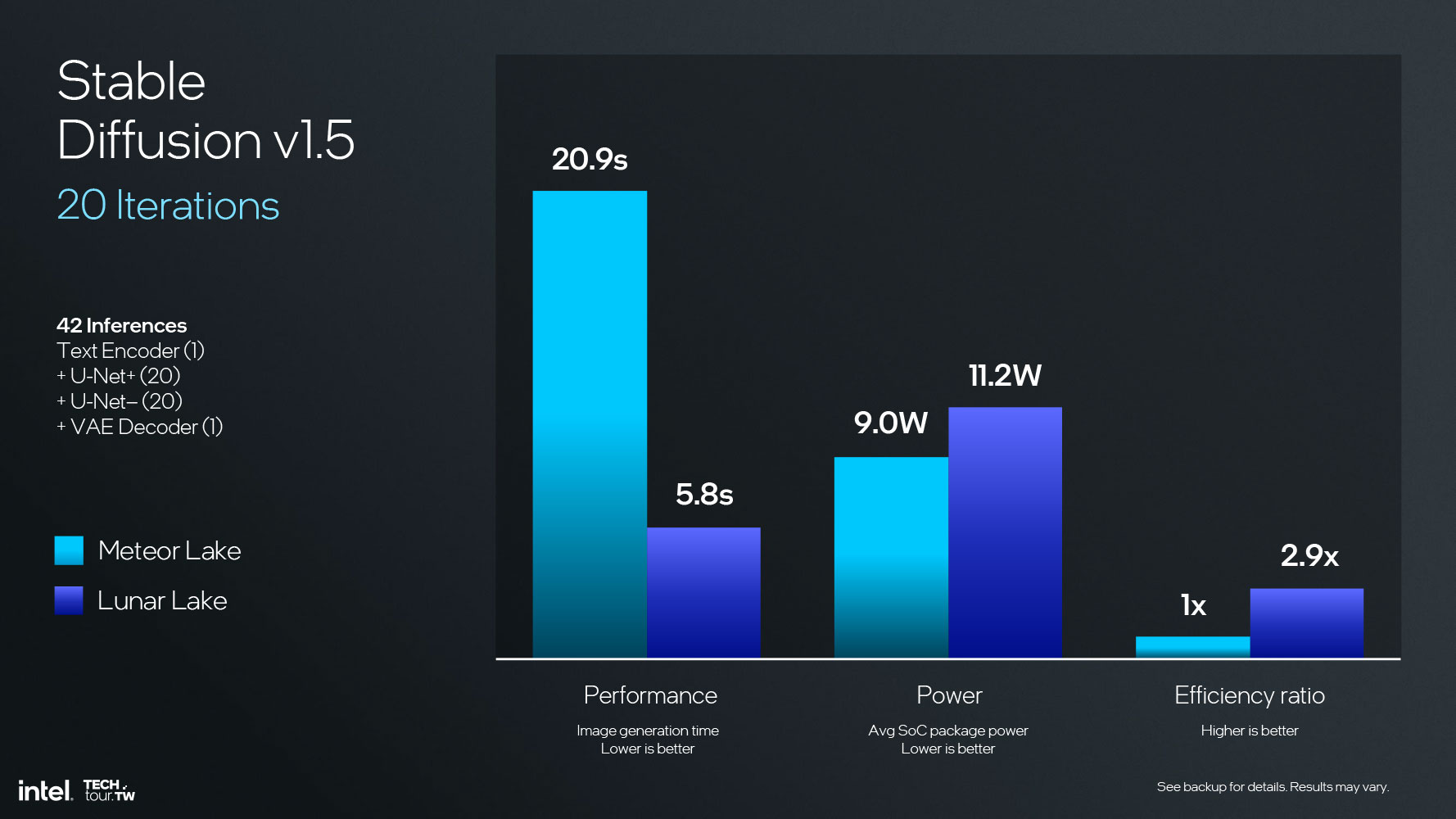
Such linear scaling in AI inferencing performance comes from not just architectural improvements (which work to reduce the NPU's power footprint); but also increasing the NCE (neural compute engine) counts from 2 on NPU 3 (Meteor Lake) to 6 on NPU 4 (Lunar Lake); with proportionate increases in the scratchpad RAM, DMA bandwidth, and L2 cache.

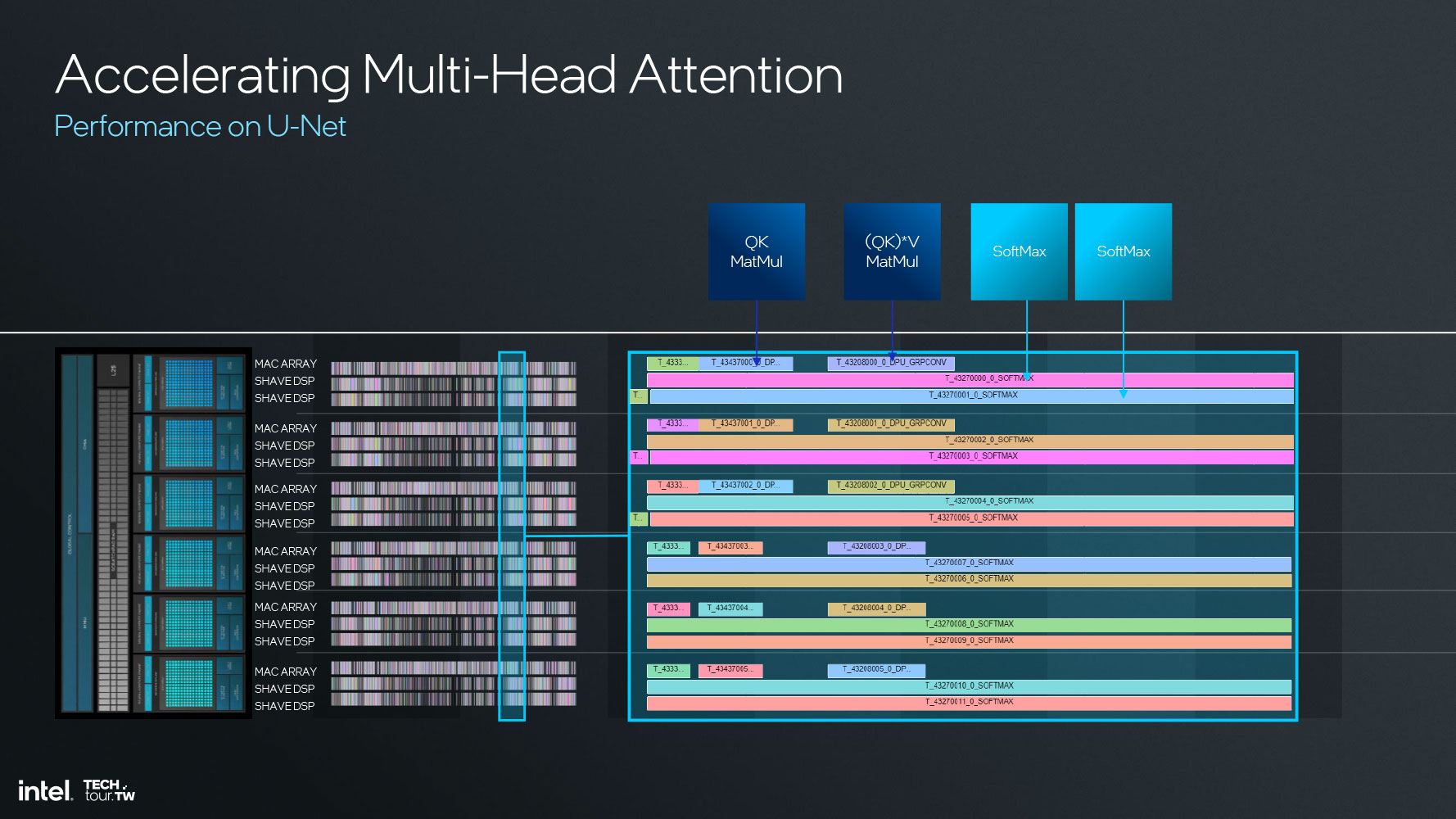
The NPU 4 matrix multiplication and convolution (MAC) array supports INT8 and FP16 data types, with 2048 MAC/cycle INT8, or 1024 MAC/cycle FP16. Intel claims a doubling in performance/Watt over NPU 3, thanks to improvements in the activation functions, data conversion, upgrades to the SHAVE DSP, and a doubling in the bandwidth of the DMA engine.
The raw vector performance of NPU 4 is now 12 times that of NPU 3, with 4 times the AI TOPS, and 2 times the bandwidth of the NPU to the fabric.
Jul 3rd, 2025 21:04 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- What Windows is overall the best to you and why? (266)
- Will you buy a RTX 5090? (610)
- What phone you use as your daily driver? And, a discussion of them. (1756)
- GPU-Z Display Bug via DP 2.1? (3)
- What would you buy? (51)
- A Final Fantasy IX Reminiscence - My love letter and homage to one of the best stories ever told (90)
- GravityMark v1.89 GPU Benchmark (309)
- RTX 5070 discussion (5)
- STAR CITIZEN - RSI POLARIS Project (39)
- Undervolting my i7-9750H (4)
Popular Reviews
- ASUS ROG Crosshair X870E Extreme Review
- Crucial T710 2 TB Review - Record-Breaking Gen 5
- Fractal Design Scape Review - Debut Done Right
- PowerColor ALPHYN AM10 Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - An Excellent Choice
- Upcoming Hardware Launches 2025 (Updated May 2025)
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- SCHENKER KEY 18 Pro (E25) Review - Top-Tier Contender
- AVerMedia CamStream 4K Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- NVIDIA Grabs Market Share, AMD Loses Ground, and Intel Disappears in Latest dGPU Update (212)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (115)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (105)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)
- NVIDIA DLSS Transformer Cuts VRAM Usage by 20% (97)