 75
75
Chat with NVIDIA RTX Tech Demo Review
Conclusion »Using Chat with RTX

After training Chat with RTX on our 60,000 news articles, we started quizzing it. None of the questions listed were intentionally crafted to be difficult for AI. We simply wondered "what could we ask this thing?." We began by asking what's the amount of cache on Raptor Lake—a rather nebulous question, once you think about it, since we didn't mention the processor model. It put out the answer 68 MB, with 36 MB of L3 cache, and 32 MB of L2 cache—the correct answer (8x 2 MB L2 for the P-cores, and 4x 4 MB for the E-core clusters in the 8P+16E Raptor Lake-S silicon). It ends its answer with a link to the text file it drew this information from. It's obviously not copy pasting statements from the news post, but composing a natural language answer based on the information it sees.
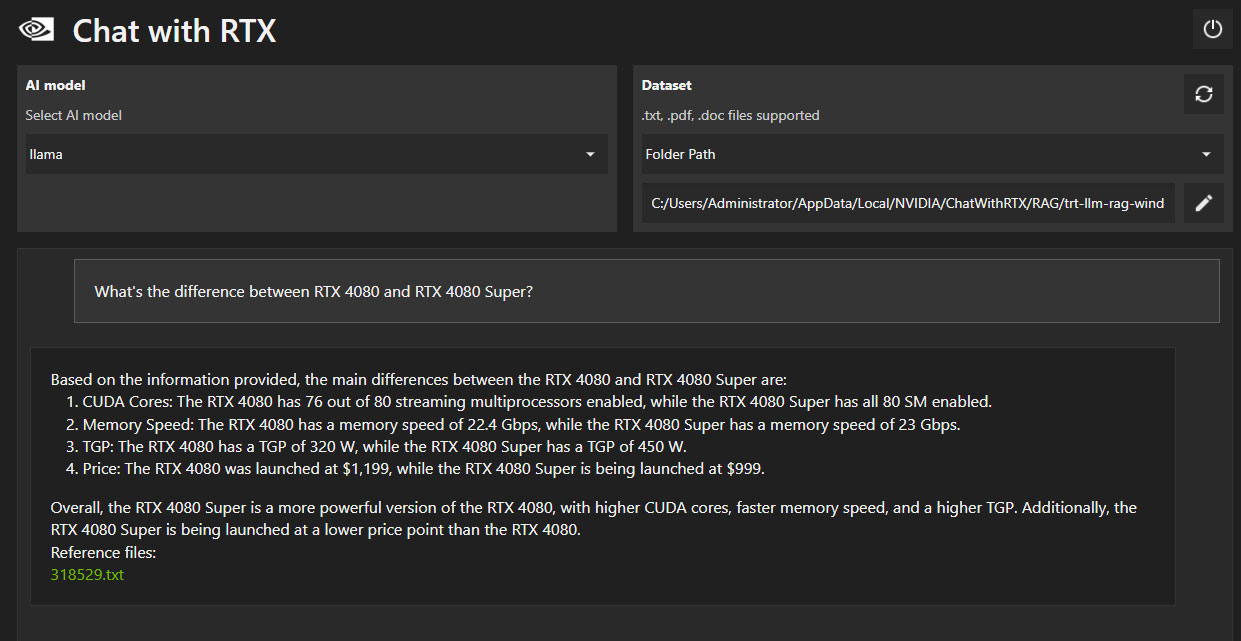
Here's another example, where we ask it how a GeForce RTX 4080 SUPER differs from the original RTX 4080 from 2022. Most information is correct, but the TGP is incorrectly listed as 450 W. Our original article is very clear that this is the theoretical limit of the cable configuration, not the actual power limit.


These answers make very little sense to the educated reader, even though they look plausible at a first look—one of the biggest dangers of AI-generated texts.

In its current state, Chat with RTX isn't able to connect follow-up questions to an original question. This is mentioned in NVIDIA's reviewer's guide, so it's not unexpected.

Next, we started feeding it some queries that we might encounter in real-life, and here things aren't looking so good.


Some of the answers are plainly wrong. But here, too, they do look very credible at first look.
Interpreting YouTube Videos?
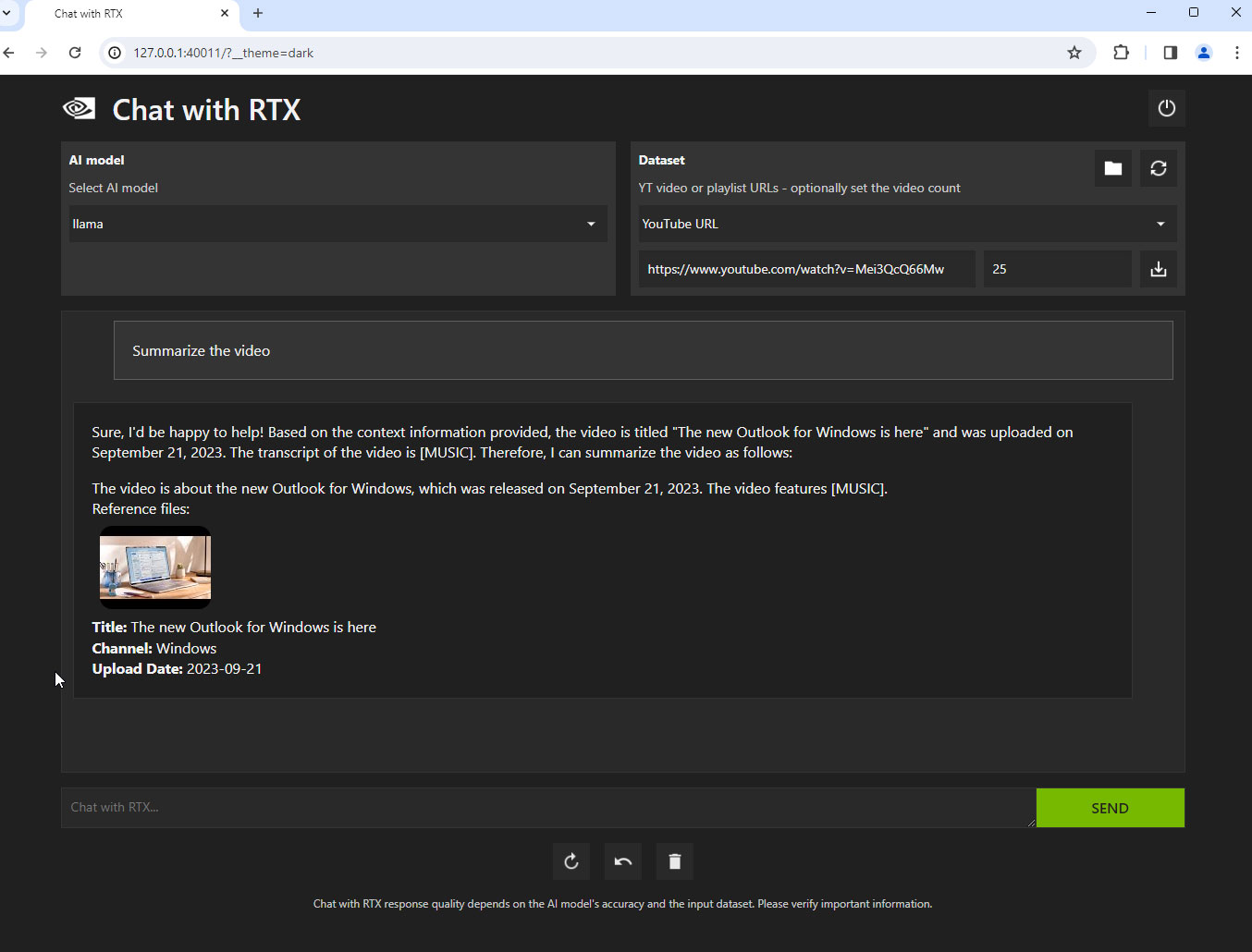
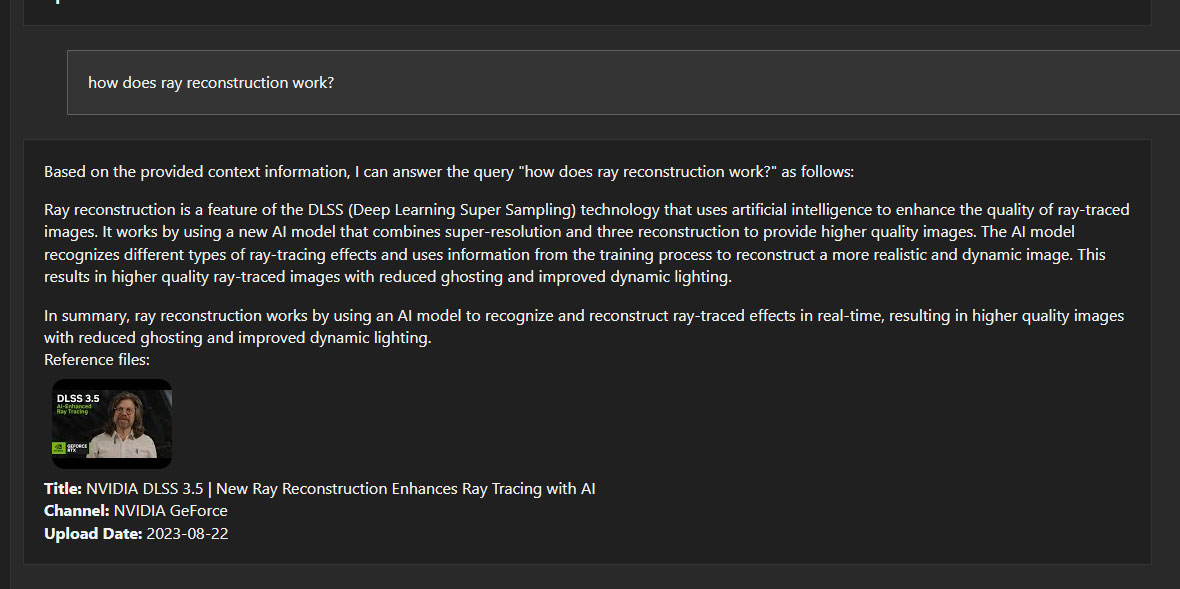
An interesting feature with the Chat with RTX application is its ability to interpret and answer questions related to YouTube videos. You feed in a YouTube video URL, or the link to a playlist, it indexes the data and can answer questions. Very impressive!
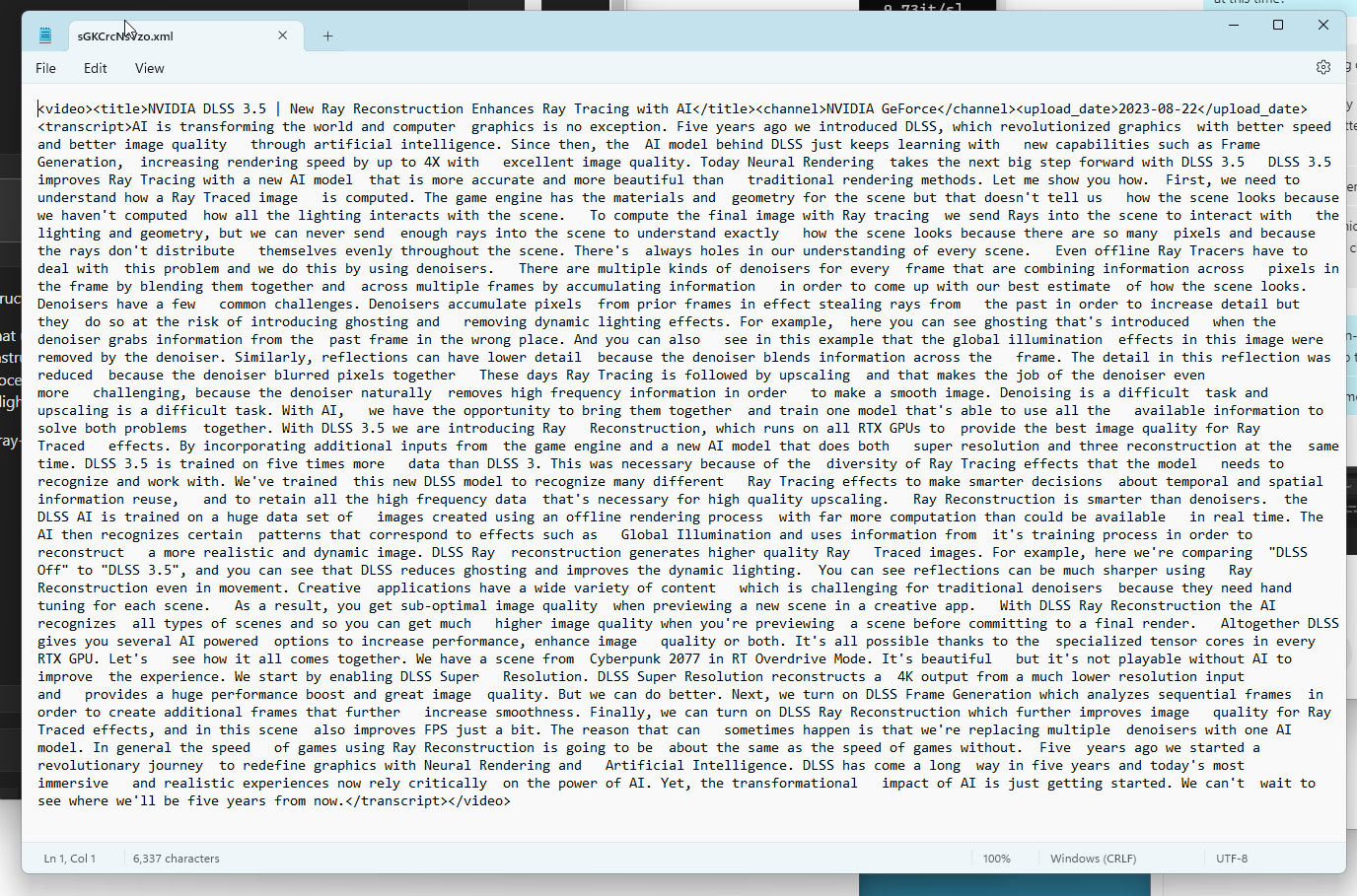
Here's how it really works—when you point it to a YouTube video, it looks for the English language closed captions (CC) file, which is provided by YouTube. There's no magic happening here, the application isn't interpreting the audio/video stream of the video, no image recognition or speech to text happening at all—it's simply answering questions based on the CC file it downloads from YT. No doubt that's a fantastic idea and will make it much easier to condense the information in long videos. In some queries you'll notice that the responses even include SDH cues like "[Music]."
Jul 15th, 2025 15:49 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- Stupid things one has done with hardware (64)
- No offense, here are some things that bother me about your understanding of fans. (143)
- Recommend me a decent budget card :) (33)
- What's your latest tech purchase? (24278)
- TOS 6 on Ugreen NAS (0)
- Folding Pie and Milestones!! (9620)
- TPU's F@H Team (20436)
- Is there a WIFI chip I should get? (4)
- TPU's Nostalgic Hardware Club (20513)
- PNY RTX 5080 16GB (1)
Popular Reviews
- MSI GeForce RTX 5060 Gaming OC Review
- Our Visit to the Hunter Super Computer
- Lexar NM1090 Pro 4 TB Review
- SilverStone SETA H2 Review
- NVIDIA GeForce RTX 5050 8 GB Review
- Fractal Design Epoch RGB TG Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - An Excellent Choice
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Upcoming Hardware Launches 2025 (Updated May 2025)
- Corsair FRAME 5000D RS Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- AMD Radeon RX 9070 XT Gains 9% Performance at 1440p with Latest Driver, Beats RTX 5070 Ti (131)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (122)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (115)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)
- NVIDIA DLSS Transformer Cuts VRAM Usage by 20% (99)