 61
61
NVIDIA GeForce Ampere Architecture, Board Design, Gaming Tech & Software
NVIDIA Reflex & G-SYNC 360 »RTX IO
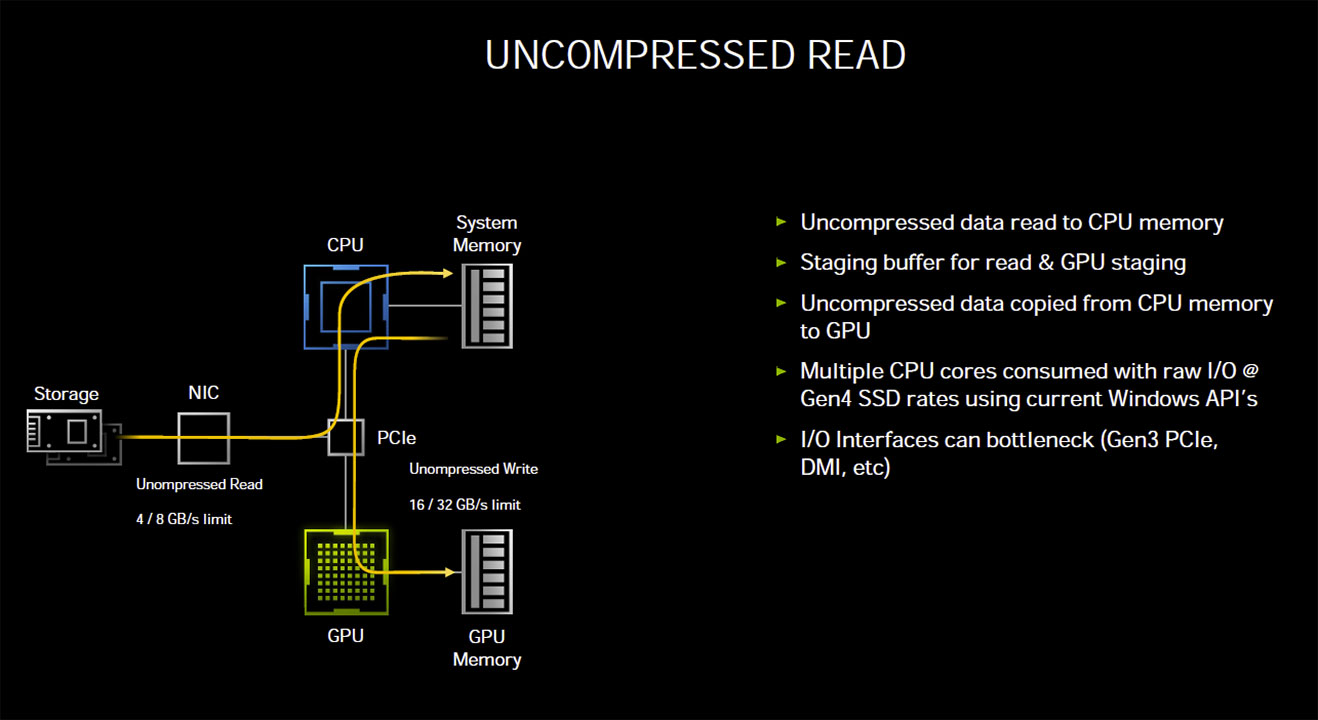

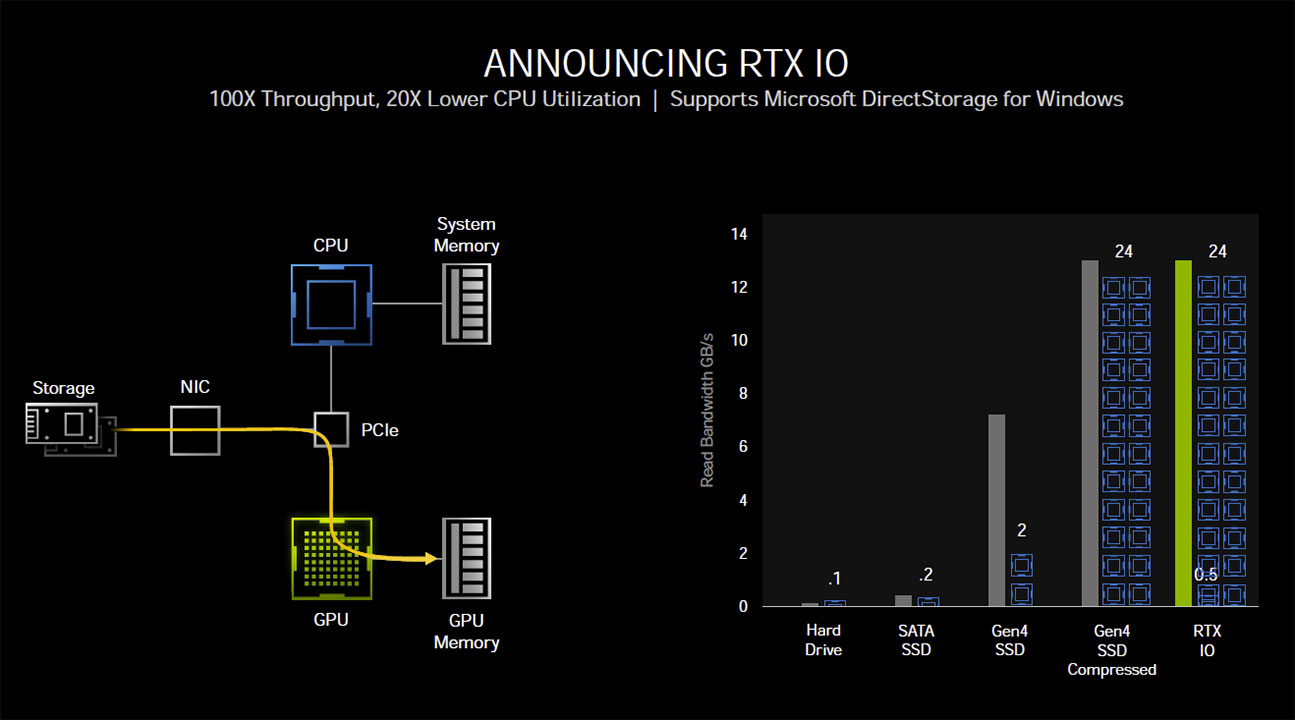
Storage is the slowest hardware component in a computer, and SATA SSDs helped mitigate this to an extent, particularly with access times and IO; however, a SATA SSD is still infinitesimally slower than the dual-channel DDR4-4000 memory, your processor's L3 cache, or even the 19 Gbps GDDR6X memory on Ampere cards. M.2 NVMe SSDs, which leverage PCIe as the interconnect, have had a transformational impact on storage, mostly because they evolves in bandwidth with each new PCIe generation. Previous-generation PCIe Gen 3 based M.2 NVMe SSDs could offer up to 3.5 GB/s of sequential transfers, and PCIe Gen 4 based ones are expected to do 7 GB/s. Efforts are already underway to make the SSDs of the future even faster than PCIe, with Intel working on Optane Persistent Memory, an SSD that uses DRAM IO and can talk directly to a compatible processor's memory controller, just like a DRAM module would. Future looking bright? Hold up.
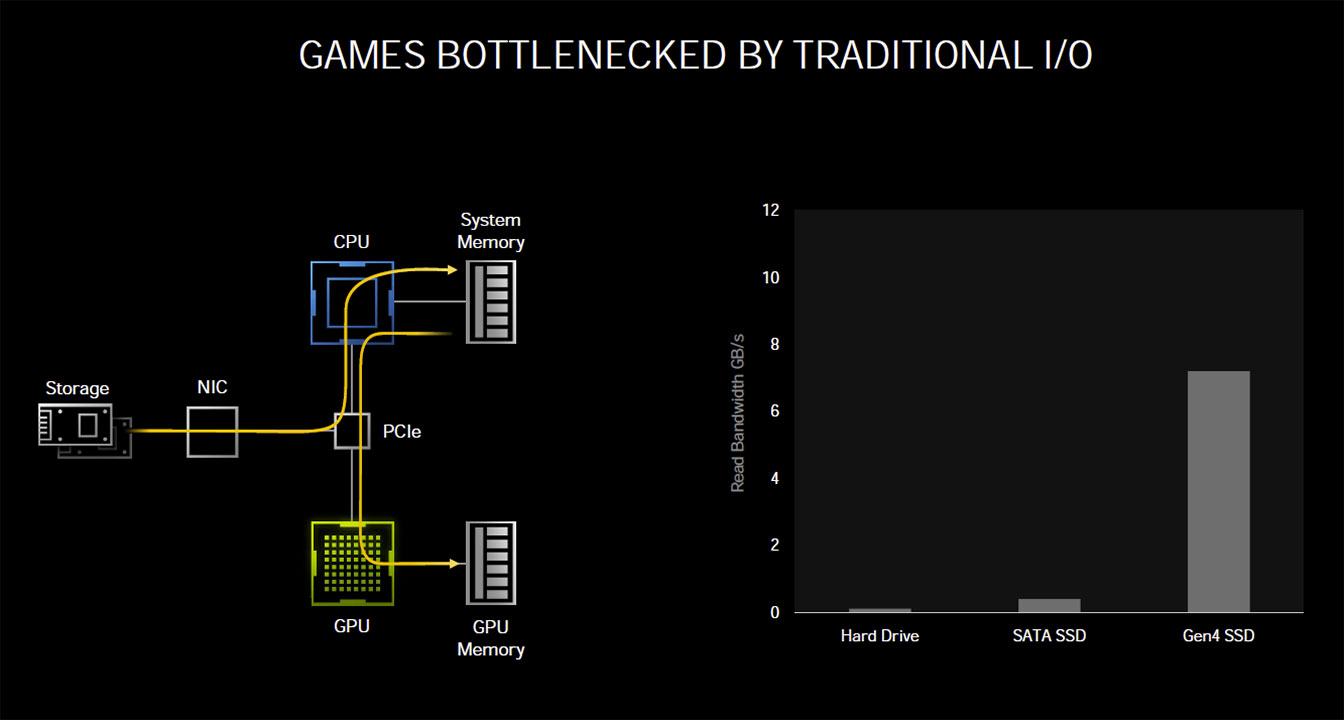
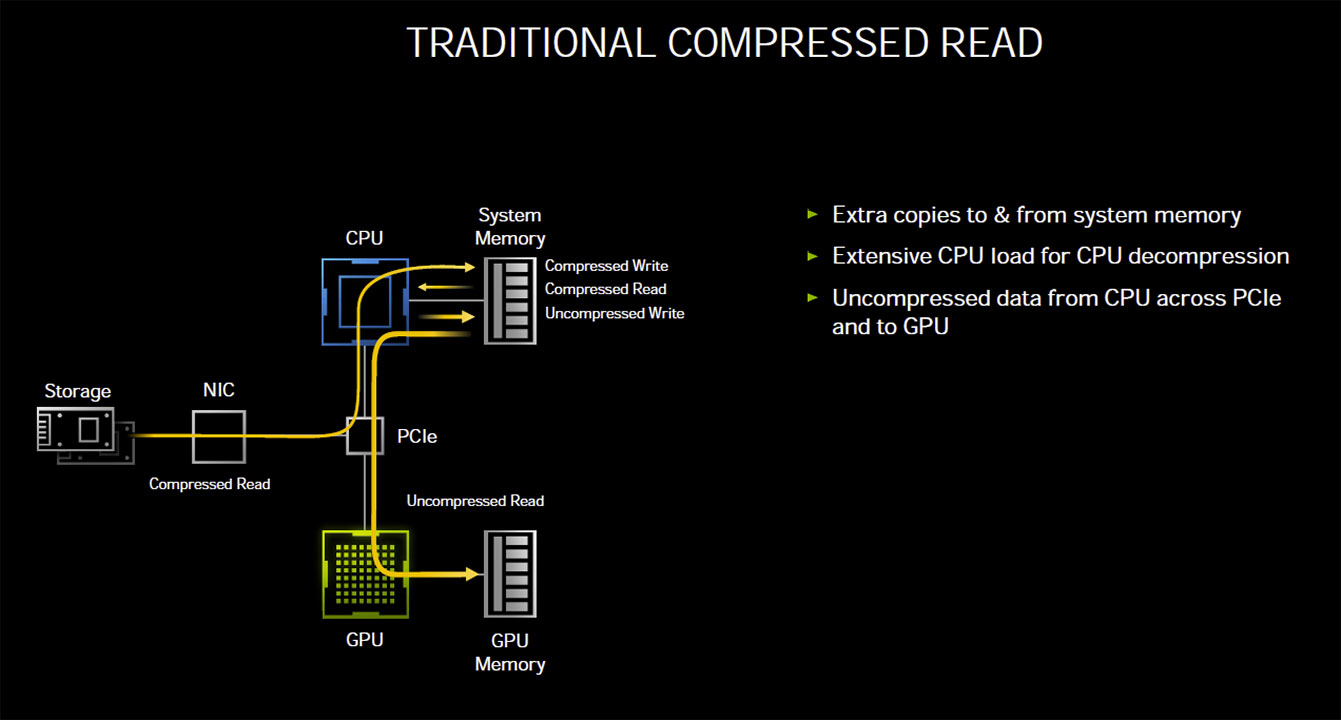
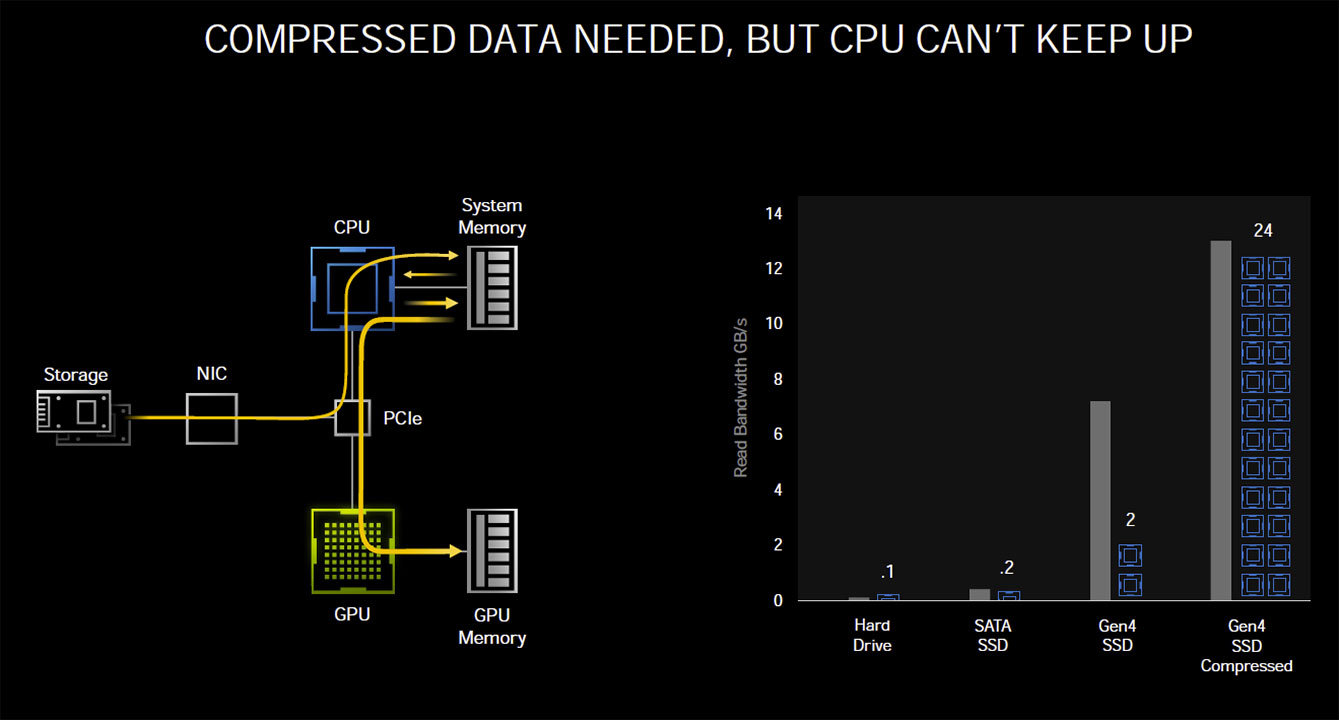
Storage isn't without overhead, and each storage IO request in a conventional PC architecture still relies on the CPU to process the IO request. According to tests by NVIDIA, reading uncompressed data from an SSD at 7 GB/s—the maximum sequential read speed of PCIe Gen 4 M.2 NVMe SSDs—requires the full utilization of two CPU cores. The OS typically spreads this workload across all available CPU cores/threads on a modern multi-core CPU. Things change dramatically when compressed data, such as game resources, are being read in a gaming scenario, with a high number of IO requests. Modern AAA games have hundreds of thousands of individual resources crammed into compressed resource-pack files. Although at a disk IO-level, ones and zeroes are still being moved at up to 7 GB/s, the de-compressed data stream at the CPU-level can be as high as 14 GB/s (best case compression). Add to this that each IO request comes with its own overhead—a set of instructions for the CPU to fetch x resource from y file and deliver it to z buffer, along with instructions to de-compress or decrypt the resource.
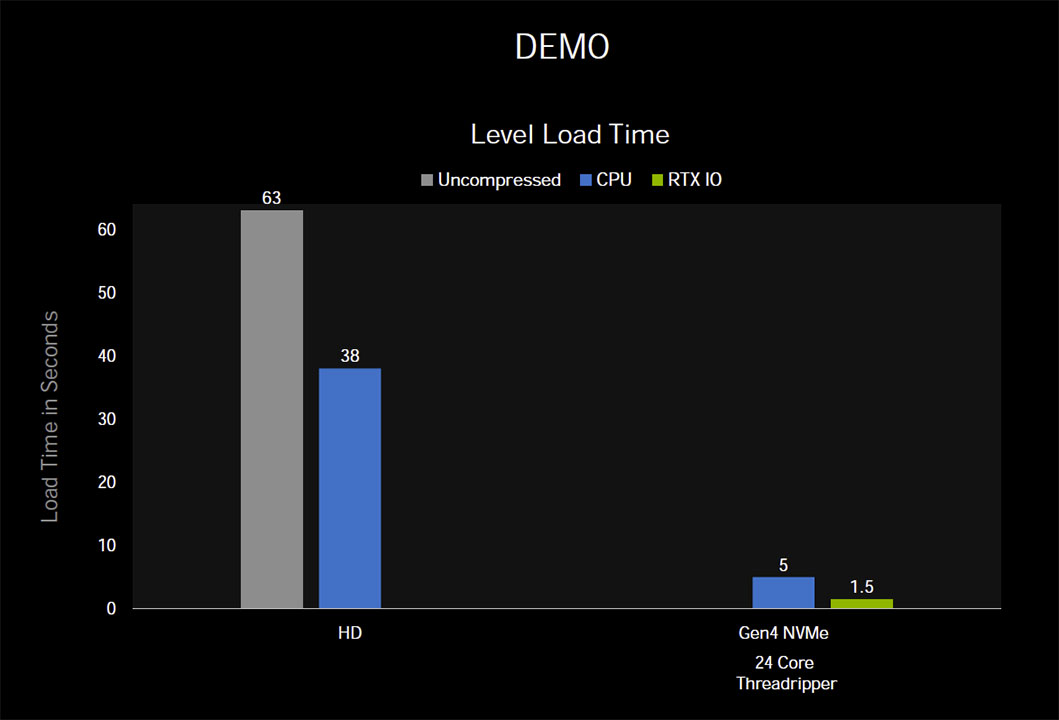
This could take an enormous amount of CPU muscle at a high IO throughput scale, and NVIDIA pegs the number of CPU cores required as high as 24. Microsoft sought to fix this problem by introducing the DirectStorage API, which enables a GPU to pull compressed data directly from the storage device, unpacking and decompressing the data on the GPU. NVIDIA RTX IO builds on this. NVIDIA RTX IO is a concentric outer layer of DirectStorage that is optimized further for gaming, and NVIDIA's GPU architecture. RTX IO brings GPU-accelerated lossless data decompression to the table, which means data remains compressed and bunched up as it is moved from the disk to the GPU, leveraging DirectStorage. NVIDIA claims this improves IO performance by a factor of two. NVIDIA further claims that GeForce RTX GPUs, thanks to their high CUDA core counts, are capable of offloading "dozens" of CPU cores, driving decompression performance beyond even what compressed data loads PCIe Gen 4 SSDs can throw at them.
Jul 13th, 2025 02:11 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- 9800x3D - 6400 CL32 1:1 not stable (12)
- Best motherboards for XP gaming (115)
- Is there a WIFI chip I should get? (1)
- What are you playing? (23945)
- 9060 XT 16GB or 6800 XT/6900XT? (30)
- ASUS ProArt GeForce RTX 4060 Ti OC Edition 16GB GDDR6 Gaming - nvflash64 VBIOS mismatch (5)
- Upgrade from old x58 system (10)
- New ToS of Take Two and 2K (11)
- Someone run games on AMD BC-250 under Linux * Cut down PS5 die to 6 CPU cores 24 GPU cores for use in crypto mining (86)
- GPU strip blinking,Trixx software not working properly,fan health fail... (1)
Popular Reviews
- Fractal Design Epoch RGB TG Review
- Lexar NM1090 Pro 4 TB Review
- Corsair FRAME 5000D RS Review
- Our Visit to the Hunter Super Computer
- NVIDIA GeForce RTX 5050 8 GB Review
- NZXT N9 X870E Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - An Excellent Choice
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Upcoming Hardware Launches 2025 (Updated May 2025)
- Chieftec Iceberg 360 Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- AMD Radeon RX 9070 XT Gains 9% Performance at 1440p with Latest Driver, Beats RTX 5070 Ti (131)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (120)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (115)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)
- NVIDIA DLSS Transformer Cuts VRAM Usage by 20% (97)