 53
53
NVIDIA Turing GeForce RTX Technology & Architecture
Anti-Aliasing with Deep Learning (DLSS) »Deep Learning and Tensor Core
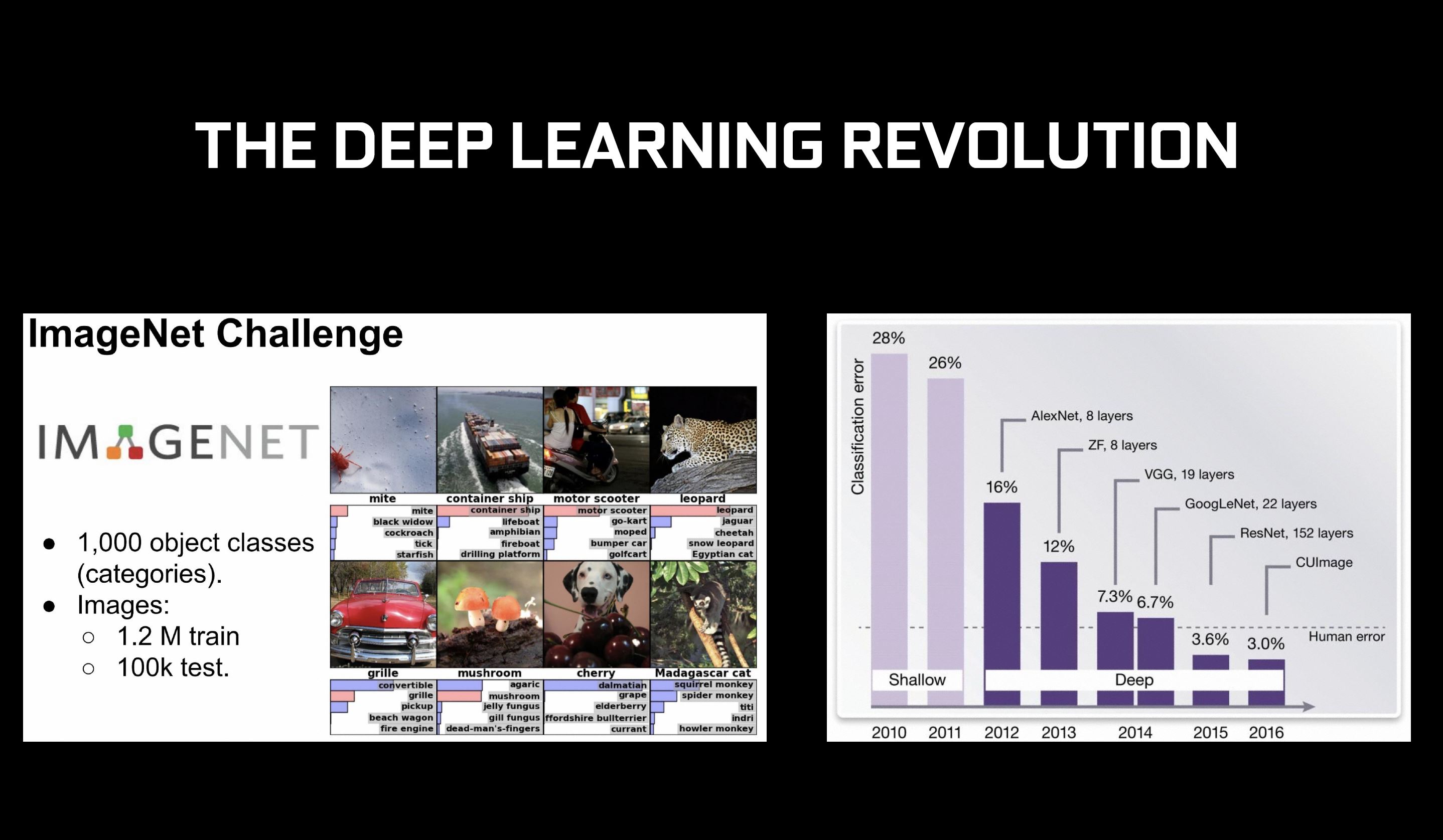

NVIDIA has been stressing their support of deep learning for generations of GPU microarchitectures now, so much so that they have partnered with several of the top research universities in the world to implement it in tasks ranging from mundane to exciting alike. With Turing, NVIDIA introduced NGX (to go hand-in-hand with RTX, get it?) as the new deep learning neural graphics framework. NVIDIA NGX uses deep neural networks (DNNs) and the so-called "neural services" to enable AI functionality for enhanced and accelerated graphics and rendering. NGX takes advantage of the Turing tensor cores, more on this below, to enable features such as Deep Learning Anti-Aliasing (DLSS), which merits its own page and will be examined subsequently. Other venues where NGX plays a role in graphics include, as per the NVIDIA whitepaper put out today, AI InPainting content-aware image replacement, AI Slow-Mo very high-quality and smooth slow motion, and AI Super Rez smart resolution resizing.
Deep learning with Turing also plays a role with inferencing applications, be it activities such as identifying common objects in digital photographs, identifying road hazards for self-driving cars, or real-time language translation. Deep learning has even been implemented in the intereference application of customized ad profiles for you online, which is why those product recommendations based on your Internet history come about quicker and more accurately than ever before. As it is, there has been a significant reported improvement in TensorRT, which is NVIDIA's in-house framework for inferencing), CUDA, cuDNN (CUDA Deep Neural Network) library, and, of course, the new Turing tensor core, which all result in better performance in the field.


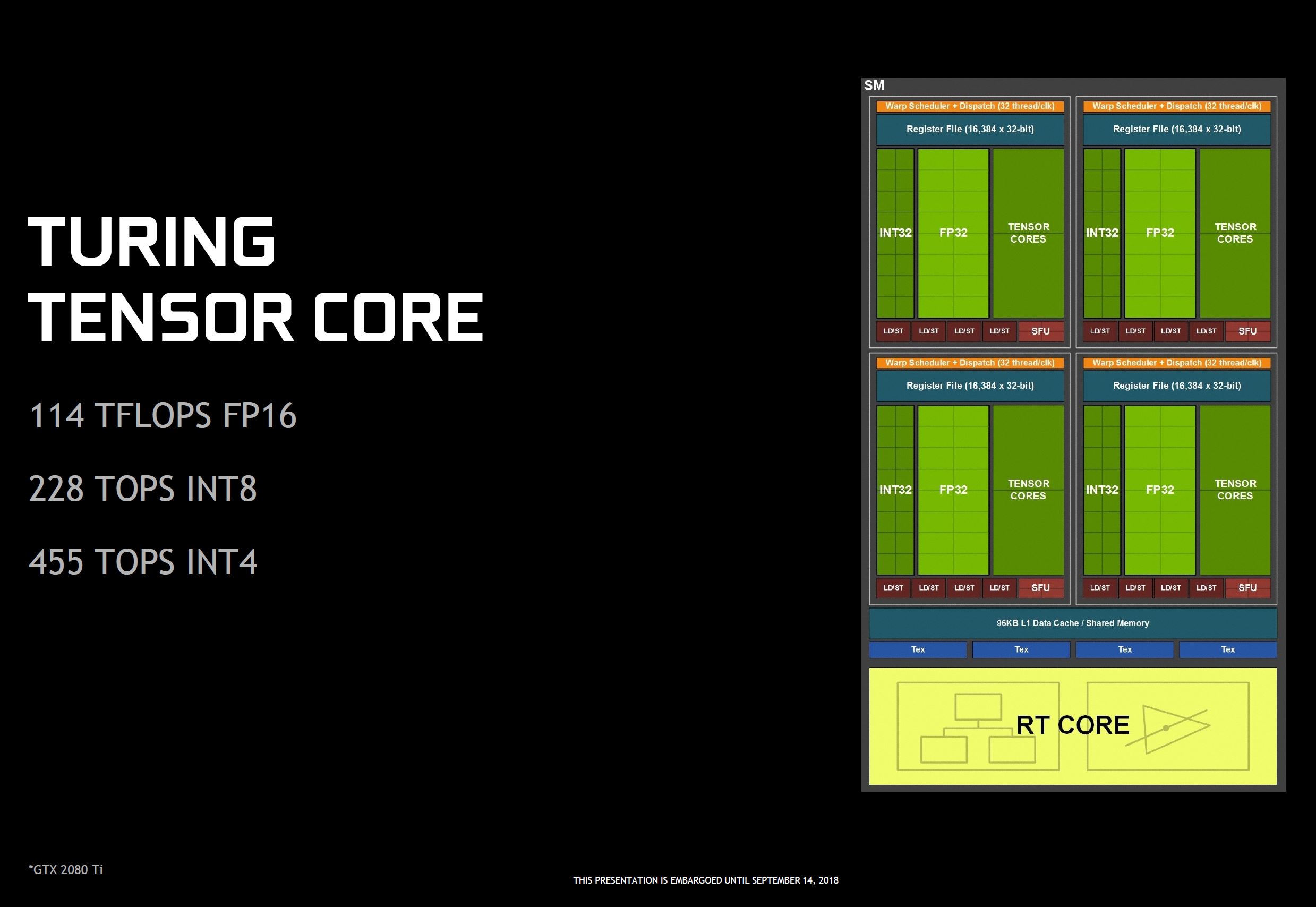
Turing tensor cores enable a lot of the deep learning optimization discussed above, which comes along with integrated support for INT8 matrix operations on a relatively fast time scale. There is also added support for a low-precision INT4 matrix approach to benefit R&D into sub 8-bit neural networks. As before, FP16 operations are fully enabled with the Turing tensor core for workloads that demand even higher precision.
Each Turing tensor core can perform up to 64 FMA (floating-point fused multiply-add) operations per clock across provided FP16 inputs. As we saw before, TU102 has up to 576 tensor cores to enable split as eight per streaming multiprocessor (SM), such that a single SM can tackle 512 FP16 FMA operations per clock or 1024 FP operations in total per clock. The new fast INT8 mode enables double this rate for a total of up to 2048 FP operations per clock. All this contributes, combined with other deep learning features mentioned above, to Turing-based GPUs being the state-of-the-art hardware and software combination for extensive deep learning inclusion across various industries of interest today.
Jul 18th, 2025 19:04 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- lower score 5070Ti after replacing the PSU (0)
- AI Job Losses: let's count the losses up, total losses to AI so far 94,000 and counting (34)
- TPU's Nostalgic Hardware Club (20539)
- 3DMARK "LEGENDARY" (329)
- Hatsune Miku x ASUS TUF Gaming Build (67)
- What's your latest tech purchase? (24304)
- Anime Nation (13051)
- Ferrari themed mod cont. 4070s repaste (7)
- Stalker 2 is looking great. (213)
- Share your CPU-X Benchmarks! (6)
Popular Reviews
- Razer Blade 16 (2025) Review - Thin, Light, Punchy, and Efficient
- SilverStone SETA H2 Review
- Thermal Grizzly WireView Pro Review
- Pulsar X2 Crazylight Review
- MSI GeForce RTX 5060 Gaming OC Review
- Our Visit to the Hunter Super Computer
- NVIDIA GeForce RTX 5080 Founders Edition Review
- NVIDIA GeForce RTX 5050 8 GB Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - An Excellent Choice
- Upcoming Hardware Launches 2025 (Updated May 2025)
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- AMD Radeon RX 9070 XT Gains 9% Performance at 1440p with Latest Driver, Beats RTX 5070 Ti (131)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (124)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (115)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- NVIDIA DLSS Transformer Cuts VRAM Usage by 20% (99)
- AMD Sampling Next-Gen Ryzen Desktop "Medusa Ridge," Sees Incremental IPC Upgrade, New cIOD (97)