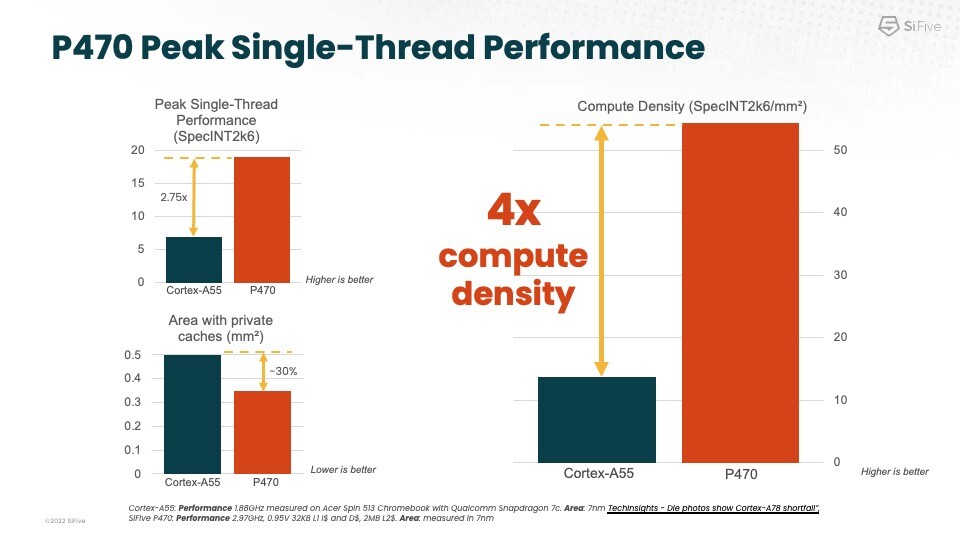
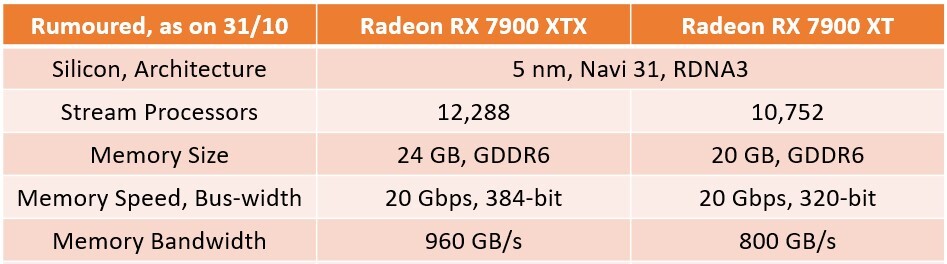
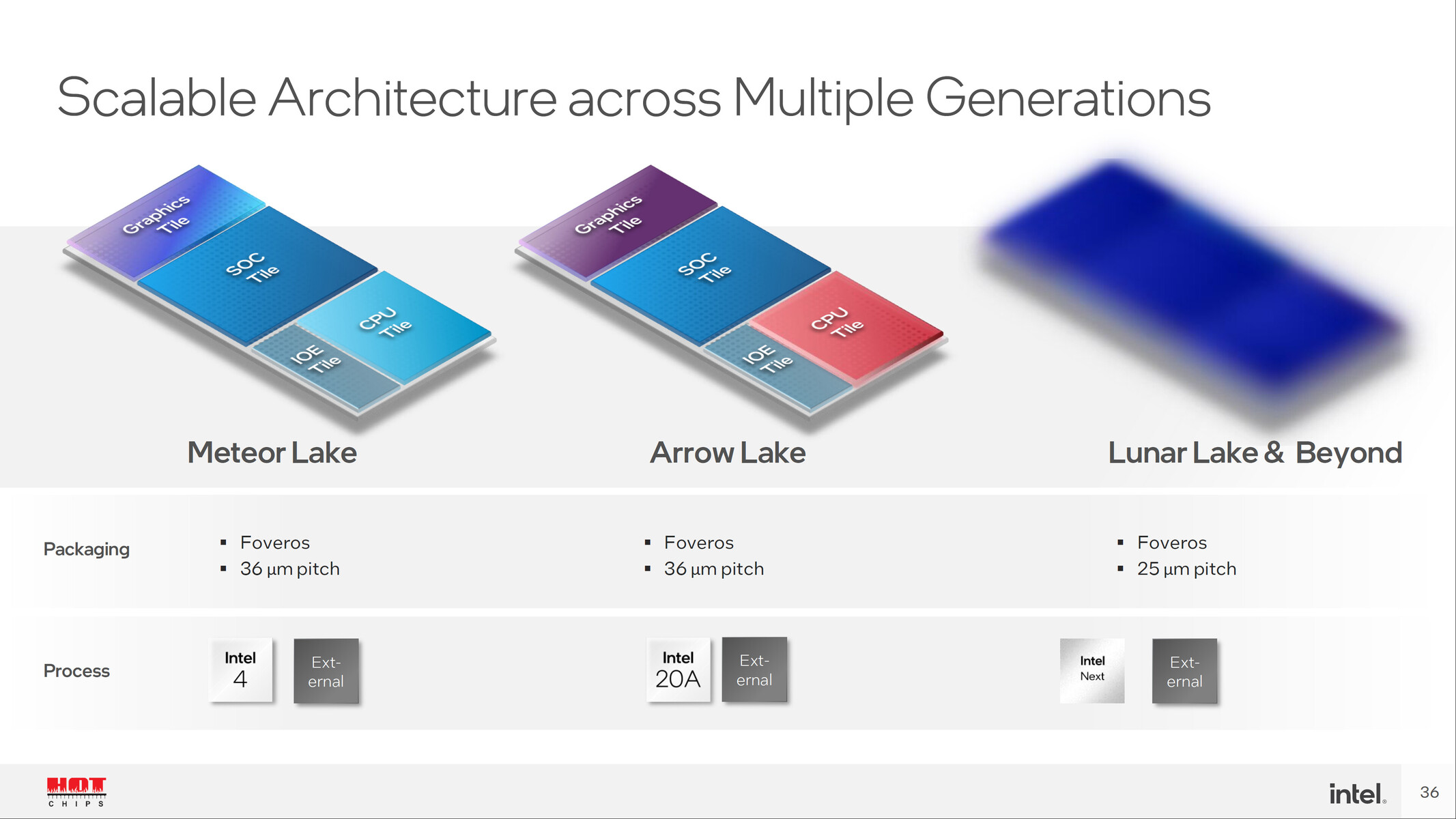
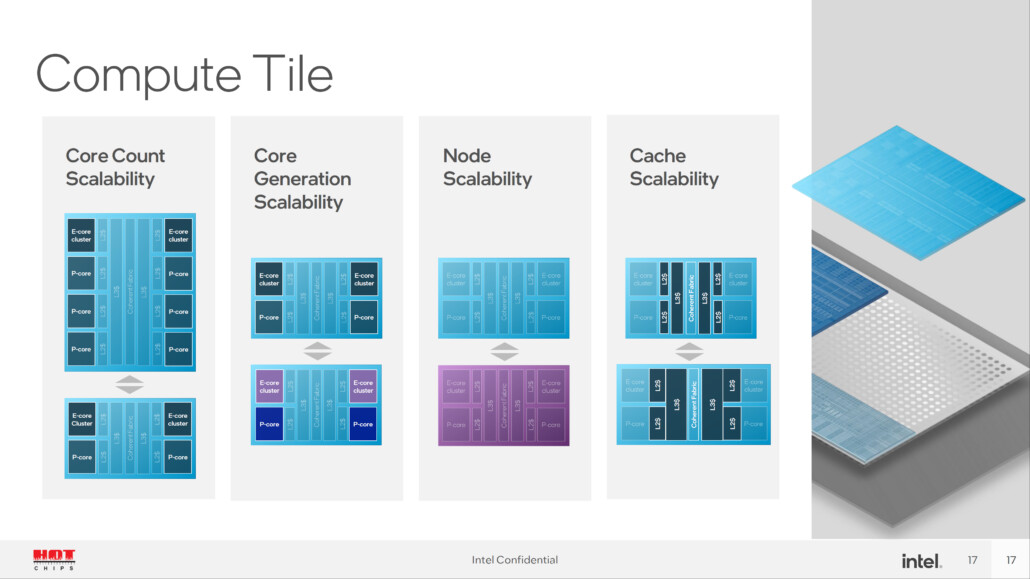
Huawei Prepares EUV Scanner for Sub-7 nm Chinese Chips
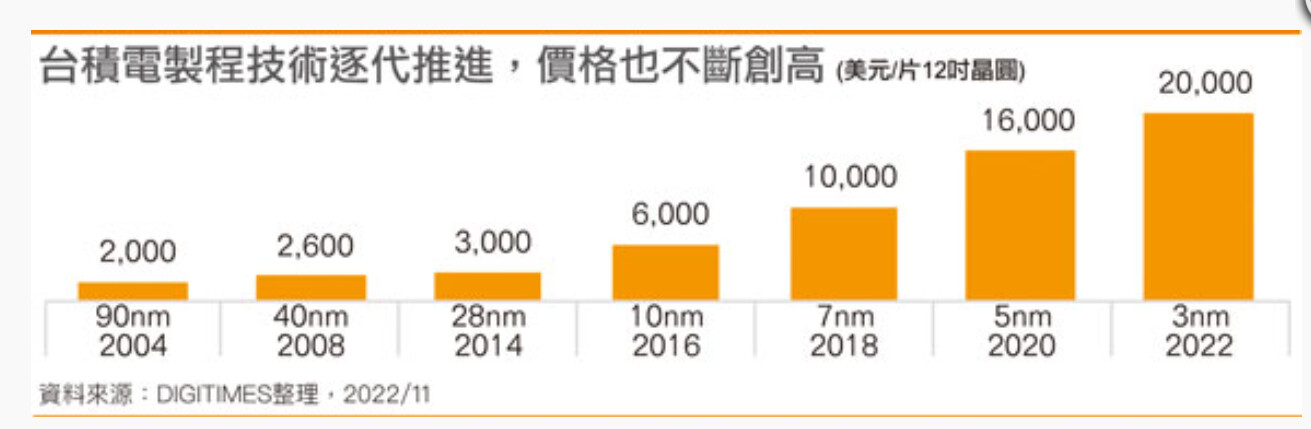
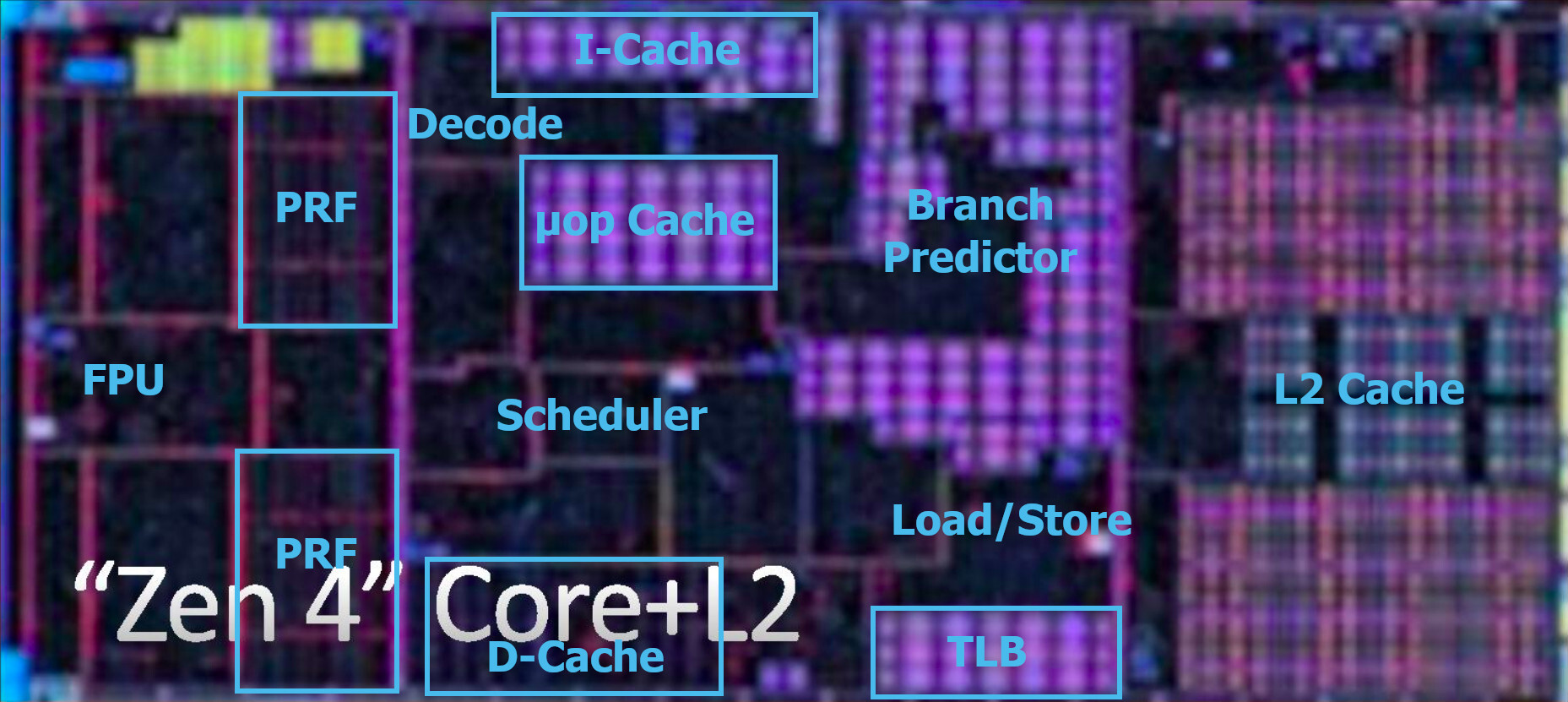
Huawei, the Chinese technology giant, has reportedly filed patents that it is developing extreme ultraviolet (EUV) scanners for use in the manufacturing process of semiconductors. This news comes amid increasing tensions between Huawei and the US government, which has imposed a series of sanctions on the company in recent years. According to UDN, Huawei has filed a patent that covers the entire EUV scanner with a 13.5 nm EUV light source, mirrors, lithography for printing circuits, and proper system control. While filing a patent is not the same as creating an accurate EUV scanner, it could enable China to produce a class of chips below 7 nm and have a homegrown semiconductor production, despite the ever-increasing US sanctions.
The development of EUV scanners is a significant milestone for Huawei and the semiconductor industry. However, the company's progress in this area may be hindered by the US government's sanctions, which have limited Huawei's access to certain technologies and markets. It is important to note that Chinese SMIC wanted to develop EUV fabrication based on third-party EUV tools; however, those plans were scrapped as the Wassenaar agreement came into action and prohibited the sales of advanced tools to Chinese companies. Huawei's development could represent a new milestone for the entire Chinese industry.
The development of EUV scanners is a significant milestone for Huawei and the semiconductor industry. However, the company's progress in this area may be hindered by the US government's sanctions, which have limited Huawei's access to certain technologies and markets. It is important to note that Chinese SMIC wanted to develop EUV fabrication based on third-party EUV tools; however, those plans were scrapped as the Wassenaar agreement came into action and prohibited the sales of advanced tools to Chinese companies. Huawei's development could represent a new milestone for the entire Chinese industry.