Tuesday, February 19th 2013

AMD "Jaguar" Micro-architecture Takes the Fight to Atom with AVX, SSE4, Quad-Core
AMD hedged its low-power CPU bets on the "Bobcat" micro-architecture for the past two years now. Intel's Atom line of low-power chips caught up in power-efficiency, CPU performance, to an extant iGPU performance, and recent models even feature out-of-order execution. AMD unveiled its next-generation "Jaguar" low-power CPU micro-architecture for APUs in the 5W - 25W TDP range, targeting everything from tablets to entry-level notebooks, and nettops.
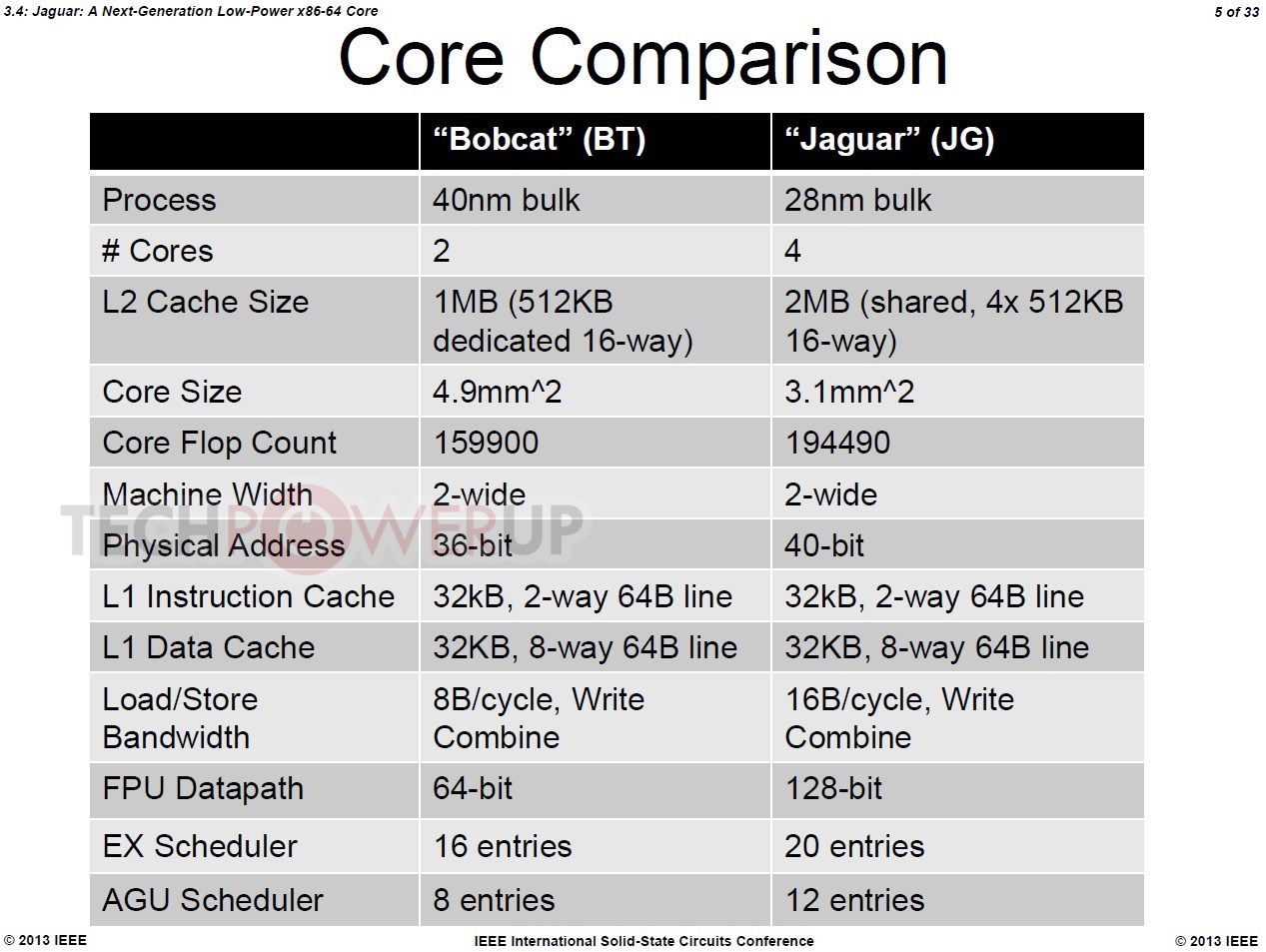
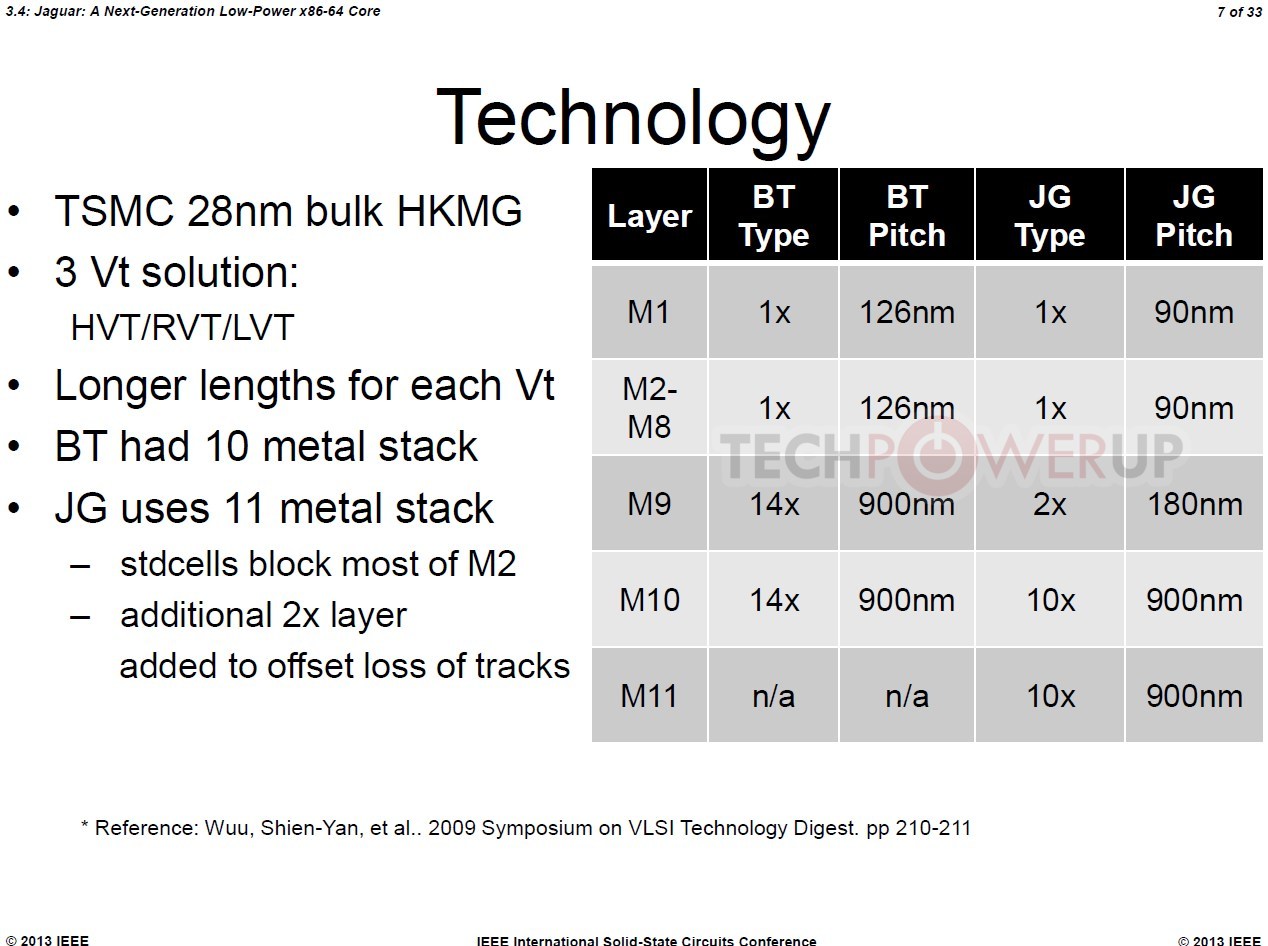
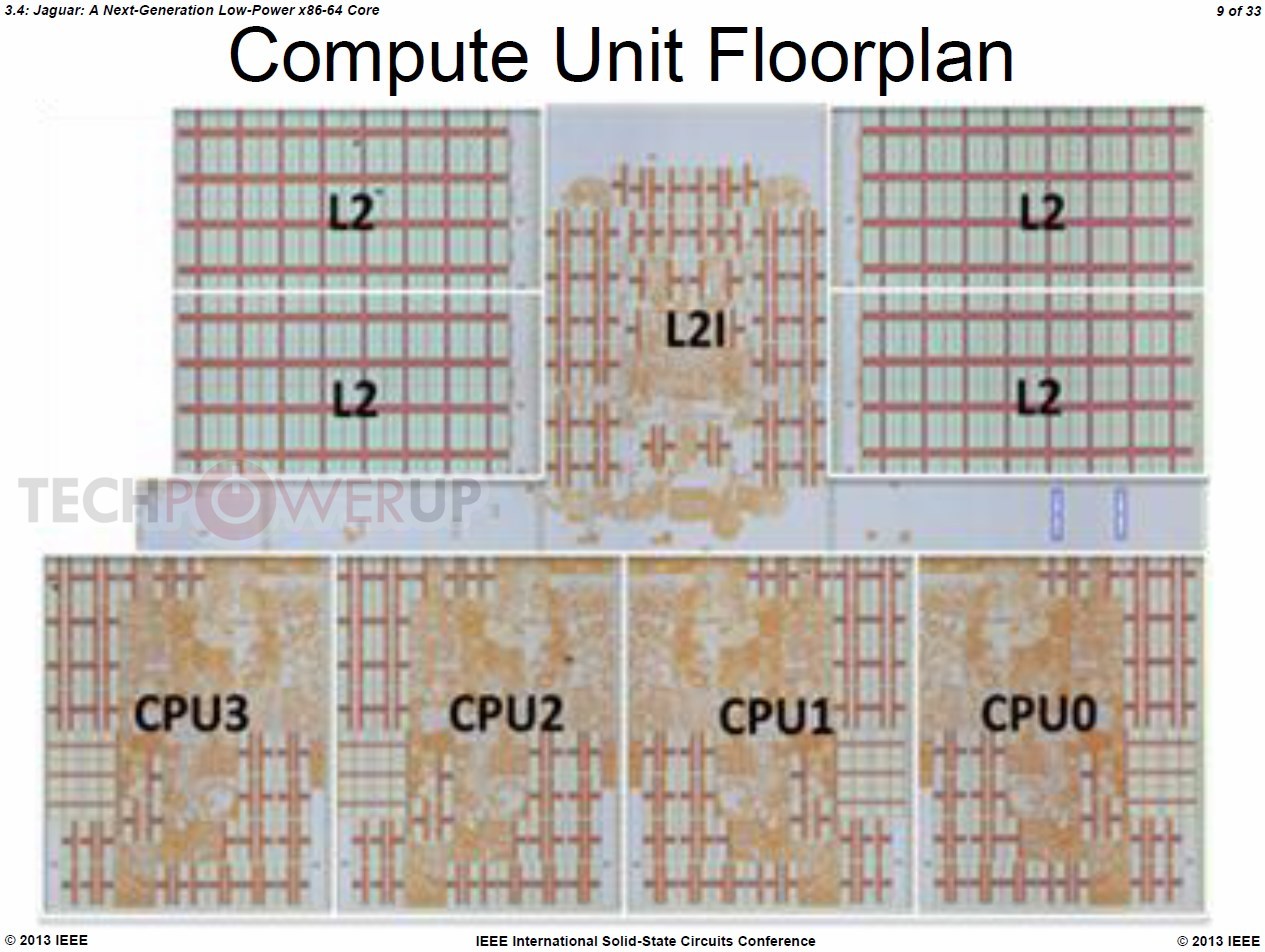
At its presentation at the 60th ISSC 2013 conference, AMD detailed "Jaguar," revealing a few killer features that could restore the company's competitiveness in the low-power CPU segment. To begin with, APUs with CPU cores based on this micro-architecture will be built on TSMC's 28-nanometer HKMG process. Jaguar allows for up to four x86-64 cores. The four cores, unlike Bulldozer modules, are completely independent, and only share a 2 MB L2 cache.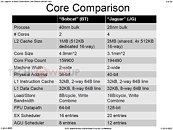


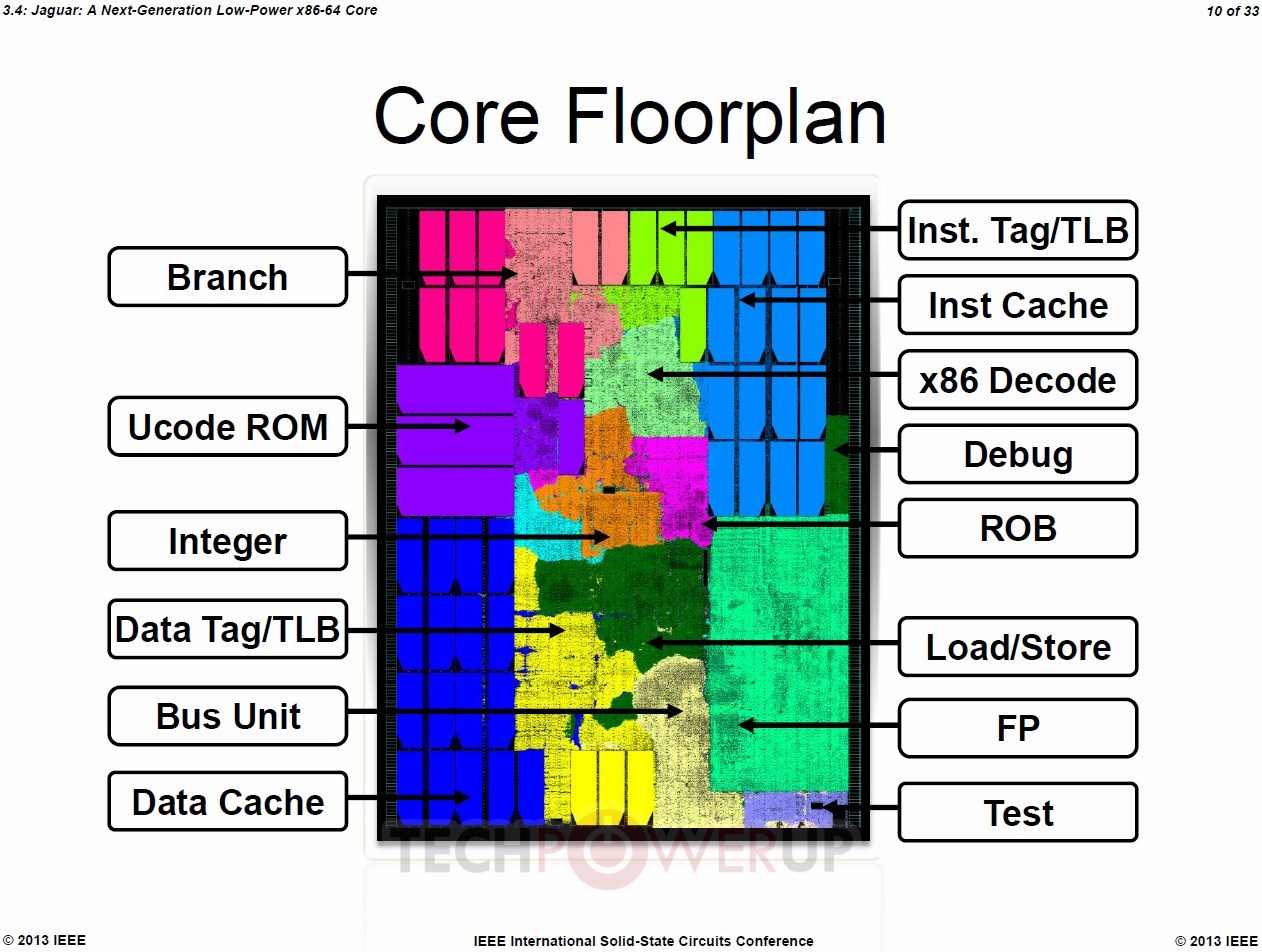
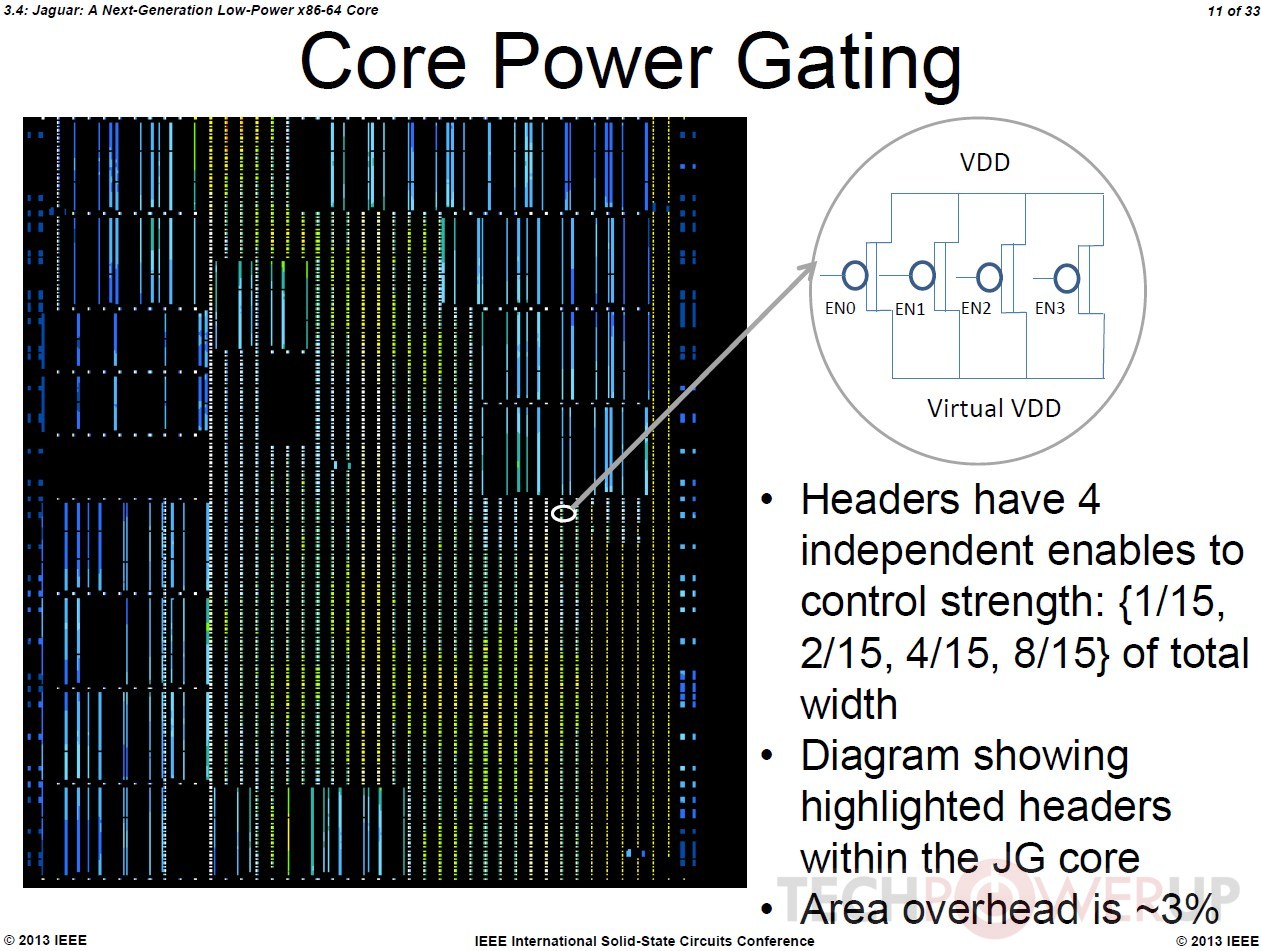
 "Jaguar" x86-64 cores feature a 40-bit wide physical address (Bobcat features 36-bit), 16-byte/cycle load/store bandwidth, which is double that of Bobcat, a 128-bit wide FPU data-path, which again is double that of Bobcat, and about 50 percent bigger scheduler queues. The instruction set is where AMD is looking to rattle Atom. Not only does Jaguar feature out-of-order execution, but also ISA instruction sets found on mainstream CPUs, such as AVX (advanced vector extensions), SIMD instruction sets such as SSSE3, SSE4.1, SSE4.2, and SSE4A, all of which are quite widely adopted by modern media applications. Also added is AES-NI, which accelerates AES data encryption. In the efficiency department, AMD claims to have improved its power-gating technology that completely cuts power to inactive cores, to conserve battery life.
"Jaguar" x86-64 cores feature a 40-bit wide physical address (Bobcat features 36-bit), 16-byte/cycle load/store bandwidth, which is double that of Bobcat, a 128-bit wide FPU data-path, which again is double that of Bobcat, and about 50 percent bigger scheduler queues. The instruction set is where AMD is looking to rattle Atom. Not only does Jaguar feature out-of-order execution, but also ISA instruction sets found on mainstream CPUs, such as AVX (advanced vector extensions), SIMD instruction sets such as SSSE3, SSE4.1, SSE4.2, and SSE4A, all of which are quite widely adopted by modern media applications. Also added is AES-NI, which accelerates AES data encryption. In the efficiency department, AMD claims to have improved its power-gating technology that completely cuts power to inactive cores, to conserve battery life.


At its presentation at the 60th ISSC 2013 conference, AMD detailed "Jaguar," revealing a few killer features that could restore the company's competitiveness in the low-power CPU segment. To begin with, APUs with CPU cores based on this micro-architecture will be built on TSMC's 28-nanometer HKMG process. Jaguar allows for up to four x86-64 cores. The four cores, unlike Bulldozer modules, are completely independent, and only share a 2 MB L2 cache.



71 Comments on AMD "Jaguar" Micro-architecture Takes the Fight to Atom with AVX, SSE4, Quad-Core
Also you said something about the pipeline being larger. How do you figure? This CPU doesn't use modules or the module design so why would the pipeline be longer? Shouldn't it be similar to the PII pipeline?
but now back to jaguar which is what this thread is about!
when jaguar was announced in the amd presentation they mentioned adding a stage to the pipleline, it used to be 11 now its 12 i believe, or 10 became 11 cant remember
and im talking about the integer pipelines, every cpu has one. and no pII had 13 stages if im not mistaken so bobcat had a new redesigned one. bulldozer has 19-22 also redesigned from pII
AMD XJS
As it stands, Intel is getting closer to making a viable Atom every revision. They suck on the graphics side, but have the weight to push Atom forward. AMD really caught the boat with an APU, but haven't done enough (as yet) to close the market to Intel offerings.
Here's to the hope that Intel will get thoroughly beaten by an excellent APU string. I'd get behind a quad core tablet running, ostensibly, 7xxx generation GCN graphics. It beats the tar out of the crap Intel has phoned in with Atom.
I heard JG will be inside PS4.
ps. 1.6GHz
- Orbis contains eight Jaguar cores at 1.6 Ghz, arranged as two “clusters”
- Each cluster contains 4 cores and a shared 2MB L2 cache
- 256-bit SIMD operations, 128-bit SIMD ALU
- SSE up to SSE4, as well as Advanced Vector Extensions (AVX)
- One hardware thread per core
- Decodes, executes and retires at up to two intructions/cycle
- Out of order execution
- Per-core dedicated L1-I and L1-D cache (32Kb each)
- Two pipes per core yield 12,8 GFlops performance
- 102.4 GFlops for system
1.6Ghz might get a little boost before the release, since they also doubled the RAM from 4GB to 8GB already.
btw a little off-toppic: anyone has any idea, how the hell are they going to deal with the insane amount of latency of the GDDR5 as main memory, this is something which puzzles me since yesterday?
and it was rated at 1.84gflops or something actually
as for the latency then i guess its up to the custom hsa memory controller, i would bet on that to handle things, after all the chip is an apu and its interesting to see what a buff apu can do, as the latency between cpu and gpu is much lower so gpgpu on an apu is much better than on a dedicated gpu with the same specs, and with gddr5 the high bandwidth will cover up the latency especialy that on consoles developers will optimize specifically for the hardware so it wont be too hard to tap into the flops available
and above all the good news out of this is that amd is smart to offer a multicore solution with with high latency to optimize because if anything this will only make their desktop solutions shine in future games since developers will start to work around it. this might explain why with steamroller amd paid no attention to most of the higher level cache subsystem (high latency on l3 and l2 cache)
Don't get me wrong, I'm sure Sony knows what they are doing and eight CPU cores is apparently makes it parallel enough to use GDDR5 as system memory, but I'm still very curious how they are doing it, because if it's better, I sure want something like that on our PC side as well:toast:
I think it will be fine. ;)
For example, a typical DDR3@1600 module has about 12ns latency in a modern PC.
Still, with some intelligent queues and cache management, this won't be too much of a problem.
## EDIT ##
Have I ever mentioned how I hate it when I get distracted when replying, only to find out I made myself look like an idiot by posting the exact same thing as the person before me? Well, I do.
Sorry Ikaruga.