Friday, February 2nd 2018
Backblaze Releases Hard Drive Stats for 2017, HGST Most Reliable
Overview
At the end of 2017 we had 93,240 spinning hard drives. Of that number, there were 1,935 boot drives and 91,305 data drives. This post looks at the hard drive statistics of the data drives we monitor. We'll review the stats for Q4 2017, all of 2017, and the lifetime statistics for all of the drives Backblaze has used in our cloud storage data centers since we started keeping track.
Hard Drive Reliability Statistics for Q4 2017
At the end of Q4 2017 Backblaze was monitoring 91,305 hard drives used to store data. For our evaluation we remove from consideration those drives which were used for testing purposes and those drive models for which we did not have at least 45 drives (read why after the chart). This leaves us with 91,243 hard drives. The table below is for the period of Q4 2017.
 A few things to remember when viewing this chart:
A few things to remember when viewing this chart:
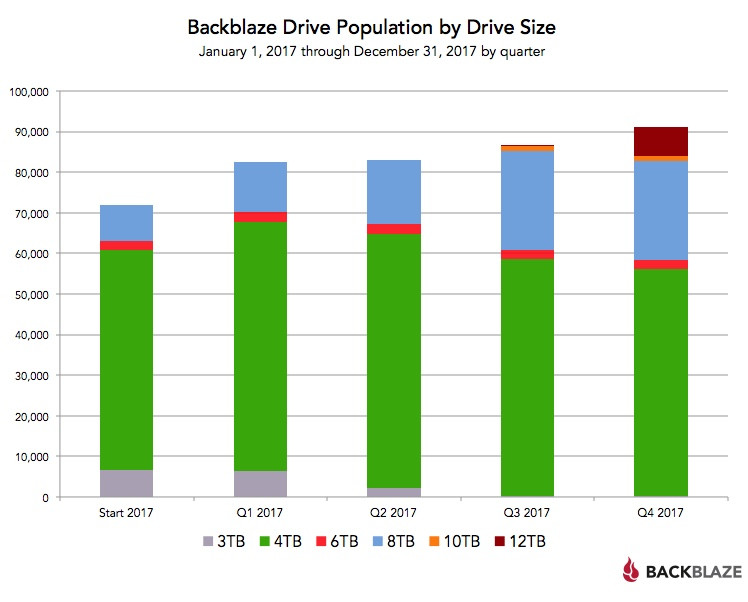
Looking back over 2017, we not only added new drives, we "bulked up" by swapping out functional and smaller 2, 3, and 4TB drives with larger 8, 10, and 12TB drives. The changes in drive quantity by quarter are shown in the chart below: For 2017 we added 25,746 new drives, and lost 6,442 drives to retirement for a net of 19,304 drives. When you look at storage space, we added 230 petabytes and retired 19 petabytes, netting us an additional 211 petabytes of storage in our data center in 2017.
For 2017 we added 25,746 new drives, and lost 6,442 drives to retirement for a net of 19,304 drives. When you look at storage space, we added 230 petabytes and retired 19 petabytes, netting us an additional 211 petabytes of storage in our data center in 2017.
2017 Hard Drive Failure Stats
Below are the lifetime hard drive failure statistics for the hard drive models that were operational at the end of Q4 2017. As with the quarterly results above, we have removed any non-production drives and any models that had fewer than 45 drives. The chart above gives us the lifetime view of the various drive models in our data center. The Q4 2017 chart at the beginning of the post gives us a snapshot of the most recent quarter of the same models.
The chart above gives us the lifetime view of the various drive models in our data center. The Q4 2017 chart at the beginning of the post gives us a snapshot of the most recent quarter of the same models.
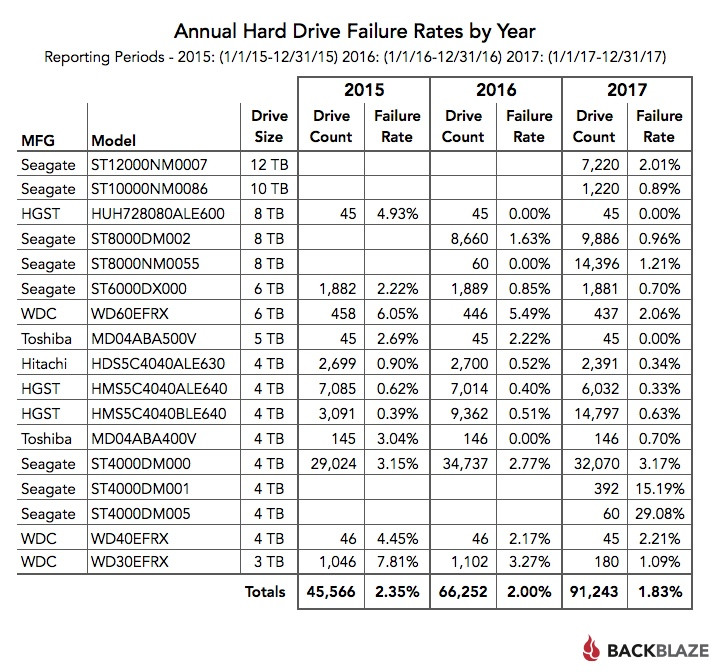
Let's take a look at the same models over time, in our case over the past 3 years (2015 through 2017), by looking at the annual failure rates for each of those years. The failure rate for each year is calculated for just that year. In looking at the results the following observations can be made:
The failure rate for each year is calculated for just that year. In looking at the results the following observations can be made:
The failure rates for both of the 6 TB models, Seagate and WDC, have decreased over the years while the number of drives has stayed fairly consistent from year to year.
While it looks like the failure rates for the 3 TB WDC drives have also decreased, you'll notice that we migrated out nearly 1,000 of these WDC drives in 2017. While the remaining 180 WDC 3 TB drives are performing very well, decreasing the data set that dramatically makes trend analysis suspect.
The Toshiba 5 TB model and the HGST 8 TB model had zero failures over the last year. That's impressive, but with only 45 drives in use for each model, not statistically useful.
The HGST/Hitachi 4 TB models delivered sub 1.0% failure rates for each of the three years. Amazing.
A Few More Numbers
To save you countless hours of looking, we've culled through the data to uncover the following tidbits regarding our ever changing hard drive farm.
Source:
Backblaze
At the end of 2017 we had 93,240 spinning hard drives. Of that number, there were 1,935 boot drives and 91,305 data drives. This post looks at the hard drive statistics of the data drives we monitor. We'll review the stats for Q4 2017, all of 2017, and the lifetime statistics for all of the drives Backblaze has used in our cloud storage data centers since we started keeping track.
Hard Drive Reliability Statistics for Q4 2017
At the end of Q4 2017 Backblaze was monitoring 91,305 hard drives used to store data. For our evaluation we remove from consideration those drives which were used for testing purposes and those drive models for which we did not have at least 45 drives (read why after the chart). This leaves us with 91,243 hard drives. The table below is for the period of Q4 2017.


- The failure rate listed is for just Q4 2017. If a drive model has a failure rate of 0%, it means there were no drive failures of that model during Q4 2017.
- There were 62 drives (91,305 minus 91,243) that were not included in the list above because we did not have at least 45 of a given drive model. The most common reason we would have fewer than 45 drives of one model is that we needed to replace a failed drive and we had to purchase a different model as a replacement because the original model was no longer available. We use 45 drives of the same model as the minimum number to qualify for reporting quarterly, yearly, and lifetime drive statistics.
- Quarterly failure rates can be volatile, especially for models that have a small number of drives and/or a small number of drive days. For example, the Seagate 4 TB drive, model ST4000DM005, has a annualized failure rate of 29.08%, but that is based on only 1,255 drive days and 1 (one) drive failure.
- AFR stands for Annualized Failure Rate, which is the projected failure rate for a year based on the data from this quarter only.
Looking back over 2017, we not only added new drives, we "bulked up" by swapping out functional and smaller 2, 3, and 4TB drives with larger 8, 10, and 12TB drives. The changes in drive quantity by quarter are shown in the chart below:
2017 Hard Drive Failure Stats
Below are the lifetime hard drive failure statistics for the hard drive models that were operational at the end of Q4 2017. As with the quarterly results above, we have removed any non-production drives and any models that had fewer than 45 drives.

Let's take a look at the same models over time, in our case over the past 3 years (2015 through 2017), by looking at the annual failure rates for each of those years.
The failure rates for both of the 6 TB models, Seagate and WDC, have decreased over the years while the number of drives has stayed fairly consistent from year to year.
While it looks like the failure rates for the 3 TB WDC drives have also decreased, you'll notice that we migrated out nearly 1,000 of these WDC drives in 2017. While the remaining 180 WDC 3 TB drives are performing very well, decreasing the data set that dramatically makes trend analysis suspect.
The Toshiba 5 TB model and the HGST 8 TB model had zero failures over the last year. That's impressive, but with only 45 drives in use for each model, not statistically useful.
The HGST/Hitachi 4 TB models delivered sub 1.0% failure rates for each of the three years. Amazing.
A Few More Numbers
To save you countless hours of looking, we've culled through the data to uncover the following tidbits regarding our ever changing hard drive farm.
- 116,833 - The number of hard drives for which we have data from April 2013 through the end of December 2017. Currently there are 91,305 drives (data drives) in operation. This means 25,528 drives have either failed or been removed from service due for some other reason - typically migration.
- 29,844 - The number of hard drives that were installed in 2017. This includes new drives, migrations, and failure replacements.
- 81.76 - The number of hard drives that were installed each day in 2017. This includes new drives, migrations, and failure replacements.
- 95,638 - The number of drives installed since we started keeping records in April 2013 through the end of December 2017.
- 55.41 - The average number of hard drives installed per day from April 2013 to the end of December 2017. The installations can be new drives, migration replacements, or failure replacements.
- 1,508 - The number of hard drives that were replaced as failed in 2017.
- 4.13 - The average number of hard drives that have failed each day in 2017.
- 6,795 - The number of hard drives that have failed from April 2013 until the end of December 2017.
- 3.94 - The average number of hard drives that have failed each day from April 2013 until the end of December 2017.
68 Comments on Backblaze Releases Hard Drive Stats for 2017, HGST Most Reliable
I think my last really bad experience with a hard drive was WD, as I had one fail, got a replacement that failed almost instantly and then got a replacement for that. That said, this was well over 10 years ago.
Back in the not so good, old days, with Conner, Quantum/Maxtor (they merged at one point) it was much more likely you'd see drive failures, as they were the bottom of the barrel products imho and experience. Sure, they were cheap, but oh so unreliable. Guess who bought both companies?
On other hand, reminds me time when I bought cheapo consumer SeaGate (1TB) and WD. And SeaGate was half-dead within 6 months and WD died in 3. Tthats not for comparing those two companies, its just that regular consumer HDDs are shit, without pardon.
Might buy some HGST, looks interesting.. funny enough, long time ago, they didnt have exactly best reputation. :D If you remember Hitachi Deathstar..
Your concern applies equally to their testing and stat reporting method. We don't know how long these drives have been in service. We only know the pool of drives during the short 4 month period of time these numbers cover provided a certain amount of drive days of work. We don't know how old those drive actually are, or how long they've been in service before the stat period started. In their method, if they started using PartA a year before they started their stat recording period, and started using PartB only a month before, then I guarantee you PartB is going to look like it has a lower failure rate. It is this exact reason that failure rate test is not done this way. It is measured from moment a part is put in service to the moment it dies or the moment it reaches the decided "EOL".
Useful information would be how many drives failed in the first, say, 3 years they are in use. That'd be a useful statistic and a proper failure rate number. Not this bullshit "we had 1 drive fail and we're going to call it a 30% failure rate".
Of course, even if they did provide the proper failure rate, BackBlazes numbers would still be completely meaningless to the average consumer anyway...I'd take a Seagate desktop/Barracuda drive over a WD Green/Blue any day. The WD Green/Blue drives are garbage. But I'd take a WD Black/Purple/Red/Gold over every Seagate except the ES drives, and I'd take a Seagate ES drive over pretty much any other drive on the market. Those drives are damn near bulletproof. It is about the model of drive, not the brand.
You have to ask yourself. If Seagate was junk, why does BackBlaze, a data storage company, use by a large margin more Seagate drives than any other brand? 74% of their drive are Seagate. That's three times as much as the next manufacturer, HGST, which only accounts for 25% of their drives. WD only accounts for a whole 1% of the drives they use, and they don't even have 1000 WD drives in service, so it really isn't a good enough sample size to judge accurately how they perform.It is because they had 60 drives and one failed, so they say that is a 30% failure rate... It's not, but they say it is.
365 days per year / ( days / drives / failrues)
365 / ( 1255 / 60 / 1 ) = 17.45 drives replaced annually.
( 17.45 / 60 ) * 100 = 29.083% of drives replaced per year.
HGST HMS5C4040BLE640:
365 / ( 1,369,721 / 14,797 / 17 ) = 67.032 drives replaced annually.
( 67.032 / 14,797 ) * 100 = 0.453% of drives replaced per year.
These are projected defect rates for a year based on how many of said drives they are currently running. Makes sense?
Were these failures during infancy (the most common failure in HDD), or after being run for 6 years (also common)? Do we know anything else about these drives other than how many got replaced? No.
I've never understood why so many sheep put so much stock in BB using commercial drives in enterzprise environments. Use the tool for the job. They are using drives as not intended, and thus not providing any useful info to either consumers or enterprise users.
We have no idea how long the drive were already in service before they started tracking these numbers. And guessing on future failure rates based on extremely small sample sizes and small time frames does not provide any sort of accurate data either.
This is specifically why failure rates are not measured this way.Also, this this and this again! You can try to justify their method of calculating failure rates all you want, but at the end of the day the data is still useless because of how they are using the drives as well as what they consider a failure. They will consider a drive failed if the RAID array marks it failed. But consumer drives in RAID arrays often get falsely marked as failed because consumer drives don't support TLER. They also pack consumer drives into huge multi drive enclosures, exposing them to heat and vibration they were never designed to encounter.
Again, they have admitted to not including data from Western Digital models that had 100% failure rates. Let that sink in for a second. When has research data ever been accurate when they just threw out data they didn't like? Answer, it hasn't.
Now, before anyone says "OMG, you're just defending Seagate and trying to bash WD by pointing out WD has models with 100% failure rate" again I'm going to go back to the fact that I'm stating that BackBlazes finding mean absolutely nothing because they are using desktop drives in enterprise environments. The WD models did not fail because they were bad drives or WD is a bad company. Those WD models failed because WD desktop drives simply do not like to run in RAID arrays. They made a very large noise about people using desktop drives in RAID arrays, and were the first to remove TLER from their desktop drives. In fact, it has been speculated that they actually purposely increased the time it takes their desktop drives to recover from an error specifically to make them largely incompatible with RAID arrays. Again, this isn't a bash on them. These 100% failure drives work great for their intended purpose, which is running as a single drive in a desktop computer.
If you want an interesting example of why TLER is important and how vibration affects large arrays of hard drive just watch this video:
When a drive encounters vibration issues like this, TLER kicks in and tells the controller that the disk is having an issue completely the commands sent to it in a timely manner. It basically lets the RAID controller know the drive is still working, but it is taking longer than normal to completely the commands for some reason. I guarantee you that if the drives in that video didn't support TLER, the RAID array would have likely marked the drives responsible for the long wait time as failed, because without TLER the drive just sits there working on the command and never reports back to the RAID controller. RAID controllers don't like this, if they issue a command and it takes too long without any response at all from the drive, they mark the drive failed.
ST4000DM005 - 2,10%
ST4000DM004 - 3,60%
There was a bit more of later sold, which is probably why it has bit higher % failure. Based on customer reports, they kinda crap, but thats understandable for that price. Still very far from 30%. :D
They dont share stats if its sold under 100 pieces. Based on reviews, they are actually sold a lot.. (I guess that low price does its magic).
Yea and those % are drives that were accepted as RMA pieces. Means they really failed.
I always bought Seagate drives, had 2 x 320 models in raid, one died (was made in china whereas the surviving one was made in taiwan), had a few 500 GB ones all 7200.11, one of the 500GB died (probably made in china as well), at one point bought a new one for a rigg i was fixing, at the store i was given a chinese seagate and i thought to myself it was going to fail, i had an hard time installing and getting it to run and it popped in less than half an hour, there was even smoke coming from the new hdd, returned it and replaced it for a samsung F3 i still own...
Still have a seagate 7200.12 (made in taiwan) it has some bad sectors but it still works pretty good, i've had 2 WD drives a 640GB black and 1TB green, the black is about 30k+ h the green was also over 30K all without issues, but these where mostly idle drives...
Last year when i was in need of increasing storage and after reading Blackblaze reports, i decided on a 4TB WD red, 4TB drives proved to be more reliable than 3TB ones and WD always been more reliable too, Hitachi drives where harder to find though...
Other than all of this, what would Backblaze stand to gain from reporting bad figures? It doesn't help them or any of the manufacturers/parties involved.
Would you mind sitting here and explaining to the crowd the difference between the different hard drives? It is quite massive when you take a standard desktop drive, NAS drive, enterprise drive etc. These aren't just all the same with a different sticker. There is a reason mtbf isn't the same.