Thursday, January 24th 2019

AMD Zen 2 12-Core, 24-Thread Matisse CPU Spotted in UserBenchmark
A new development could shake up our expectations on AMD's new Ryzen 2 CPUs, which if true, could mean that previous rumors of much increased core-counts at the top of AMD's offerings were true. User TUM Apisak, who has been involved in multiple information leaks and scouting for the hardware world, has digged enough to find a submitted UserBenchmark that screams of a 12-core, 24-thread AMD Matisse part (an engineering sample at that, so keep your hats on for the presented clock speeds).
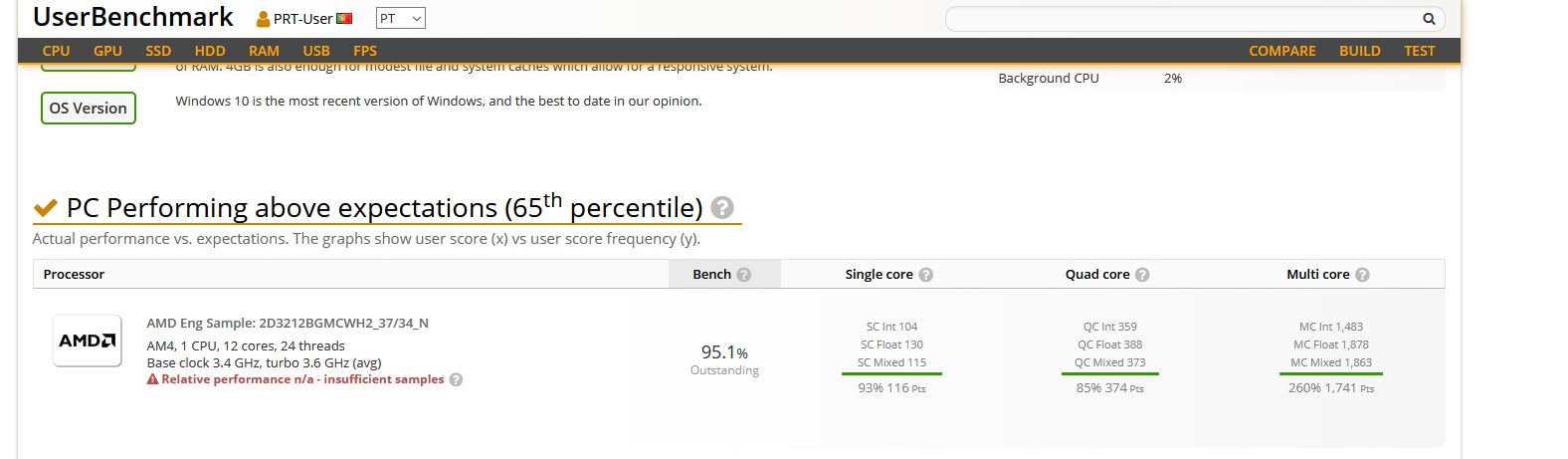
The benchmark list the used CPU via product code 2D3212BGMCWH2_37 / 34_N (H2 is indicative of a Matisse CPU The benchmark is listing a base clock speed of 3.4 GHz and an average boost clock speed of 3.6 GHz. The rest of the system specs are very, very basic, with 4 GB of 1333 MHz DDR4 memory being used on a new AMD platform, based on the Myrtle-MTS based chipset. The processor is listed having a 105 watts TDP and 32 MB of L3 cache.

Sources:
TUM Apisak Twitter, User Benchmark
The benchmark list the used CPU via product code 2D3212BGMCWH2_37 / 34_N (H2 is indicative of a Matisse CPU The benchmark is listing a base clock speed of 3.4 GHz and an average boost clock speed of 3.6 GHz. The rest of the system specs are very, very basic, with 4 GB of 1333 MHz DDR4 memory being used on a new AMD platform, based on the Myrtle-MTS based chipset. The processor is listed having a 105 watts TDP and 32 MB of L3 cache.
35 Comments on AMD Zen 2 12-Core, 24-Thread Matisse CPU Spotted in UserBenchmark
While I do expect a final 12-core Zen 2 to be slightly higher clocked and get slightly better single and quad core scores, and the Zen 2 to have the upper hand in energy efficiency, I don't expect there to be a 60W difference in TDP. Let's hope Intel at least ditches the integrated graphics, it has nothing to do in a 10-core.
I do wonder though what place these CPUs deserve in the market. Don't get me wrong, options are fine and while they look compelling, what market demand do they serve?
It's obviously not gaming. And many heavy multithreaded workloads are also consuming of memory bandwidth. I guess these are relevant for people looking for a "HEDT lite", perhaps image editing or coding, but probably not heavy encoding or simulations. Personally I would probably not consider these high-core "mainstream" CPUs from either company, as I value the flexibility for more memory bandwidth and capacity, and when investing this much money anyway, the expandability of the platform is also something to consider.
I wouldn't read too much into the specifics of the setup as an indicator of problems with the platform. It's highly likely that this is some kind of validation setup, and the BIOS which was just a few days old might be an indicator of a BIOS or motherboard testing lab.
I'm not sure making a unified L3 cache for several chiplets is a good idea in general, but not primarily because of latency as Darmok N Jalad mentioned, but because of the way L3 works. As you said, L3 is a victim cache, and in most designs it's an inclusive cache. There is a reason why Skylake-X changed this, because it's very inefficient use of die space, and it also means that increasing L2 will also decrease the efficiency of L3. As you probably know, modern CPUs typically split L1 cache into instruction and data caches, while L2 and L3 is both. And while L3 cache is shared between multiple cores, the actual sharing is commonly very minimal. The entire cache is overwritten every few microseconds, so the chance of two cores needing data from the same cache line is very minimal, because when you have multiple threads working, they have to use separate data, otherwise they would stall all the time. So the only thing that is generally shared between cores is instructions, if the cores are executing the same part of the code of course. And the few times the times the L3 victim cache is useful for data, it's usually from the same core that evicted it. So to sum up, L3 is largely wasteful in its current application, and only gives minor benefits.
I think it's time to re-evaluate L3 cache's role, and the changes Intel did in Skylake-X is probably just the beginning. Perhaps a split L3 cache, or instructions only L3 cache? Perhaps L3 shouldn't be shared and be data only, but L4 be instructions only and shared?