Monday, June 14th 2021

AMD Files Patent for its Own x86 Hybrid big.LITTLE Processor
AMD is innovating its own x86 hybrid processor technology formulated along the Arm big.LITTLE hybrid CPU core topology that inspired Hybrid processors by Intel. Under this, the processor has two kinds of CPU cores with very different performance/Watt bands—one kind focuses on performance and remains dormant under mild processing loads; while the other hand handles most lightweight processing loads that don't require powerful cores. This is easier said than done, as the two kinds of cores feature significantly different CPU core microarchitectures, and instruction sets.
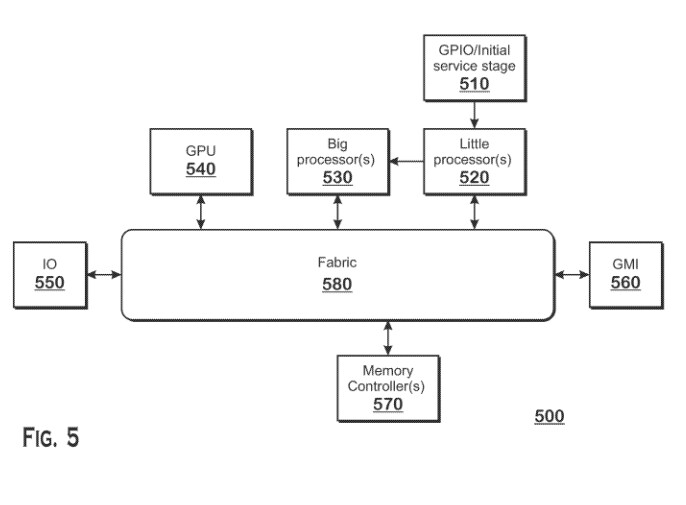
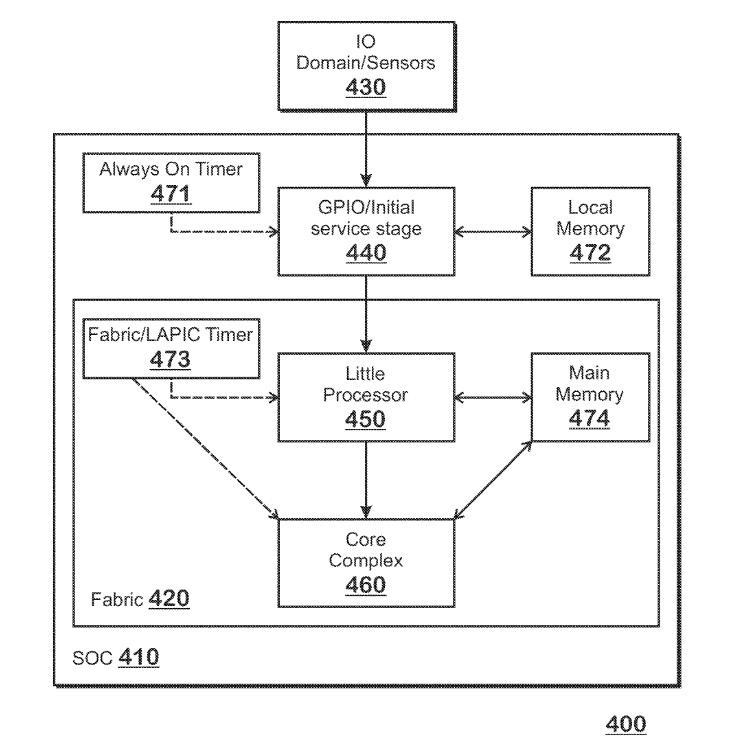
AMD has filed a patent describing a method for processing workloads to be switched between the two CPU core types, on the fly. Unlike homogenous CPU core designs where workload from one core is seamlessly picked up by another over a victim cache like the L3, there is some logic involved in handover between the two core types. According to the patent application, in an AMD hybrid processor, the two CPU core types are interfaced over the processor's main switching fabric, and not a victim cache, much in the same way as the CPU cores and integrated GPU are separated in current-gen AMD APUs.
 According to the patent application, AMD's CPU core type switching logic is dictated by a number of factors, such as CPU core utilization of the low-power color, its memory utilization, the need for instruction sets only found with the performance core, and machine architecture states. The patent also briefly references a power-management mechanism that saves system power by gating the two core types based on utilization. Power savings are the primary objective of any big.LITTLE topology.
According to the patent application, AMD's CPU core type switching logic is dictated by a number of factors, such as CPU core utilization of the low-power color, its memory utilization, the need for instruction sets only found with the performance core, and machine architecture states. The patent also briefly references a power-management mechanism that saves system power by gating the two core types based on utilization. Power savings are the primary objective of any big.LITTLE topology.
The patent description can be accessed here.
Source:
Kepler_L2 (Twitter)
AMD has filed a patent describing a method for processing workloads to be switched between the two CPU core types, on the fly. Unlike homogenous CPU core designs where workload from one core is seamlessly picked up by another over a victim cache like the L3, there is some logic involved in handover between the two core types. According to the patent application, in an AMD hybrid processor, the two CPU core types are interfaced over the processor's main switching fabric, and not a victim cache, much in the same way as the CPU cores and integrated GPU are separated in current-gen AMD APUs.
The patent description can be accessed here.
21 Comments on AMD Files Patent for its Own x86 Hybrid big.LITTLE Processor
From the graphs it looks like the big and small core are separated and connected via fabric. So different chiplets? I suppose so.
They might wanna implement Big.Little architecture to mobile APUs to further enhance power saving capabilities.
However there is probability that they just need to make patent just to enable using it in future IF some-when it will be needed.
Real (whatever that means) desktop products are only one segment, you know, right? This is very relevant in many environments where power and heat are and will always be bottlenecks...
Power draw in low usage cases is already a place where AMD is weak and where they draw more power than Intel even when in full load cases they destroy Intel on performance/W so it's a good thing they're trying to improve on this.
Die utilization is another one. smaller simpler core to use way less space versus their relative performance. You can put them more in the same space. Big core are really for the the single threaded load. You could probably get higher performance per die space in highly multithreaded code by using more smaller cores in the same die space. I am not sure about game (altought if the main thread run in the big core, i don't see why it wouldn't be good) but many workload could benefits from it like video encoding, Rendering, etc.
Larger cache might also change how CPU are made, if the L3 always contain what the CPU want to execute, it may no longer need to have all the mechanism there to improve overall performance while the CPU wait for Data.
I also don't understand why people are so against this in desktop. People, leave the engineering side of things to the engineers. If, at the end of the day you get better performance, that is what matters.
Another important point mentioned previously is that in the same die space you can get more performance with more smaller cores compared to fewer big cores. Why? Because having a big core with a huge OOO window and making it work efficiently, that is, use as much of those resources that it has is more difficult than maximizing smaller cores.
So in the end, a 16 big cores vs a 8 big cores and 16 smaller ones might bring you more performance from the 8+16 with similar die space usage, pluuus, you are more efficient when idle/partially loaded thanks to those smaller cores.
I actually think that power efficiency in desktop is also an objective for Intel, for the same reason why they want ATX12VO, power regulations from states/government.
Well People talk a lot about IPC, but work accomplish per joule is still a critical point on all platform including desktop. Nobody want to have to deal with a 1000w CPU.
"Little" core aren't only smaller, they use less power for the same amount of work. This means you can do more work with the same power envelope. In the end, this is what everyone want on all platform.
A lot of the low hanging fruit from multi-core multi die CPU designs might run it's course a bit so less emphasis on too much general purpose might be the way forward in favor of task specific speeds ups to more latency sensitive workloads that are only lightly threaded for example.
I just see a doorway to dynamic L1/L2 cache size and design structure between chip dies to be leveraged. Why wouldn't you want a L1 or L2 cache that's a bit lower latency than one on another die? Why might you want a bit higher L1/L2 cache latency rather than a cache hit penalty at the same time by accessing the next level cache? There are obvious performance and power efficiency reasons to why cache's are designed a particular way. It's just not possible for them to be perfect across all use cases in terms of performance and efficiency however there is always a balance. I see this is a nice way of achieving higher balance. I do think the L3 cache could absolutely be shared and tasks across the L3 cache combined in highly parallel workloads. Lighter less parallel workloads I could see a round robin cache approach based on the chip die where a task retroactively selects the best suited L1/L2 cache design structure on the fly where it will use one over another to speed up a given part of a given task on hand.
Make a new cut-down Zen optimized for die space and low power.
Bring back AMD's Atom competitor with significant updates.
Use ARM cores.
Using ARM cores has been my thought for some time, MS has the ability to do so, the Linux people surely have as well, plus AMD have produced their own ARM CPU's before, so already have some experience with ARM and possibly the most significant point here (apart from the software) is that AMD and Samsung are already collaborating with Samsung Fabricating AMD parts and Samsung licencing AMD RDNA GPU cores for Samsung mobile chips.
The rumors are they would use Zen4 core as the little core and Zen5+ as the big core, all x64.
MicroShaft and Linux already run the OS and Apps on ARM cores, I see no (good) reason why the OS in either case could not be literally run on top of each other. I would run the "base" OS on the Arm cores so that the base system will natively run low power and background system tasks, with the "upper" OS running the big AMD64 (x86) cores for things that need it.
Arm cores have been heavily optimised for Web Apps and video already, the relatively small performance loss of running Web Apps (browsers primarily) on the "little" Arm cores would likely be unnoticeable except on benchmarks, and Browsers are the only "low power" App that I am aware of that is deceptively needy of high performance CPU's.
On the MS side, there would undoubtedly be a massive cludge, but as Gaming and other high performance needing Apps are slowly moving away from MS to Linux anyway, I would expect Linux to be the ideal OS platform, or I should say, Dual OS platform. There is also no real reason why using such an Arm/AMD64 hybrid CPU cannot be done using Linux on the Arm coses as the "base" OS and Windows on top of that, in many respects this would be the ideal solution.
There would potentially be great boons for system security by going this route of essentially running two OS's one on top of the other, which is commonplace with Servers.
There is still a long time to wait for this to happen, so we will likely not get anything concrete for a couple of years, up until then, this is pure speculation and a thought experiment.Intel's upcoming solution has a similar couple of problems itself, the first is likely not a real issue at all and that is that the "small cores" do not have Hyper Threading, the second issue is that the "small cores" cannot execute AVX512. AVX512 is still not commonly used, and when it is it is typically used in high performance Apps anyway.
Seeing how Intel / MicroShaft / Linux gets round these issues will be interesting as will be the whole operation of the scheduler. From what I have heard, MS has/is putting a lot of effort into this (with Intel) and could give us clues as to how AMD goes about this.
Interesting times ahead, especially for those who will want to use (or just test) how Alder Lake performs on W10 vs W11, and whether MS / Intel make Rocket Lake's big.LITTLE CPU's work properly at all on W10, we shall find out in a few months.