Tuesday, March 1st 2022

NVIDIA "Ada Lovelace" Streaming Multiprocessor Counts Surface
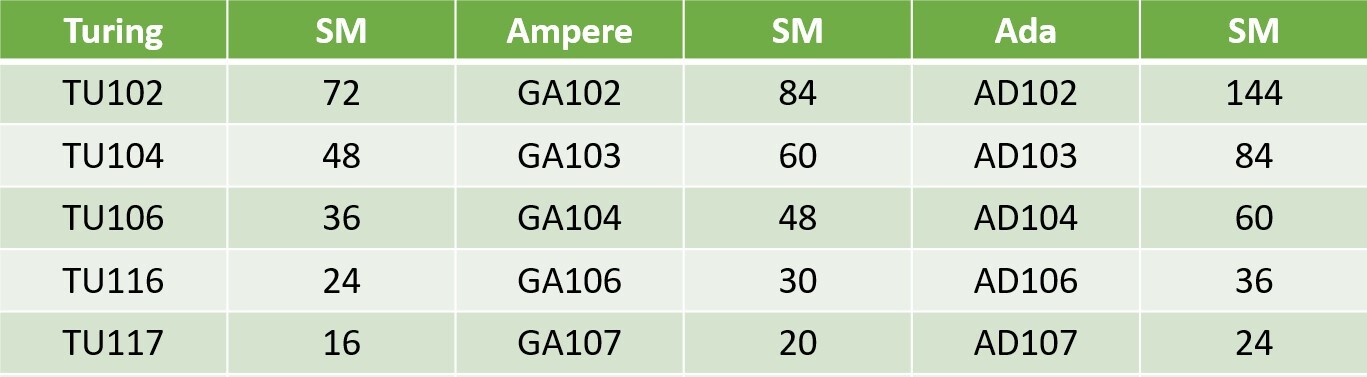
Possible streaming multiprocessor (SM) counts of the various NVIDIA "Ada Lovelace" client-graphics GPUs surfaced, allegedly pieced together from code seen in the recent NVIDIA cyberattack data-leak. According to this, the top-dog "AD102" silicon has 144 SM, the next-best "AD103" has 84. The third-largest "AD104" silicon has 60. The performance-segment "AD106" has 36, and the mainstream "AD107" has 24. Assuming the number of CUDA cores per SM in the "Ada Lovelace" graphics architecture is unchanged from that of "Ampere," we're looking at 18,432 CUDA cores for the "AD102," an impressive 10,752 for the "AD103," 7,680 cores for the "AD104," 4,608 for the "AD106," and 3,072 for the "AD107."
Source:
David Eneco (Twitter)
40 Comments on NVIDIA "Ada Lovelace" Streaming Multiprocessor Counts Surface
All rest seem right.
Hopefully endowed with a normal stack of VRAM this time. And under a normal TDP... please 104, don't exceed 250W.
If the last two years and launches have shown anything is that MSRP is a figment of the imagination.
Those still sitting on the 10 Series cards definitely will have something worthwhile for upgrading.
I will be interested in how they far at 1080p and 1440p.
On a different note, I'm hoping we'll see more improvements in power consumption. I have no desire to buy and feed a 300+ W GPU.
I would still expect the top end 80/90 tier 4000 series cards to be pushed hard to keep parity with RDNA3 though in rasterized performance.
A Turing CUDA core is a pair of execution units - one for INT32 and one for FP32. The two are counted as one CORE on paper.
Ampere's CUDA core pair is still INT32 and FP32, but the INT32 can also run FP32 with the downside that you now have two FP32 units competing for the same Registers, cache, LD/ST etc compared to Turing's one, and FP32 performance is halved if INT32 calculations need to be run.
Ampere does have more logic but performance didn't double like the core count implied as many of the things that previously constituted a CUDA core weren't doubled at all.
I'm wondering if the same thing has happened here with Lovelace, or whether they're just squeezing way more transistors in with TSMC's denser process. If that's true, we're going to see some astronomical costs and TDPs!