Wednesday, March 23rd 2022

AMD Ryzen 7 5800X3D Geekbenched, About 9% Faster Than 5800X
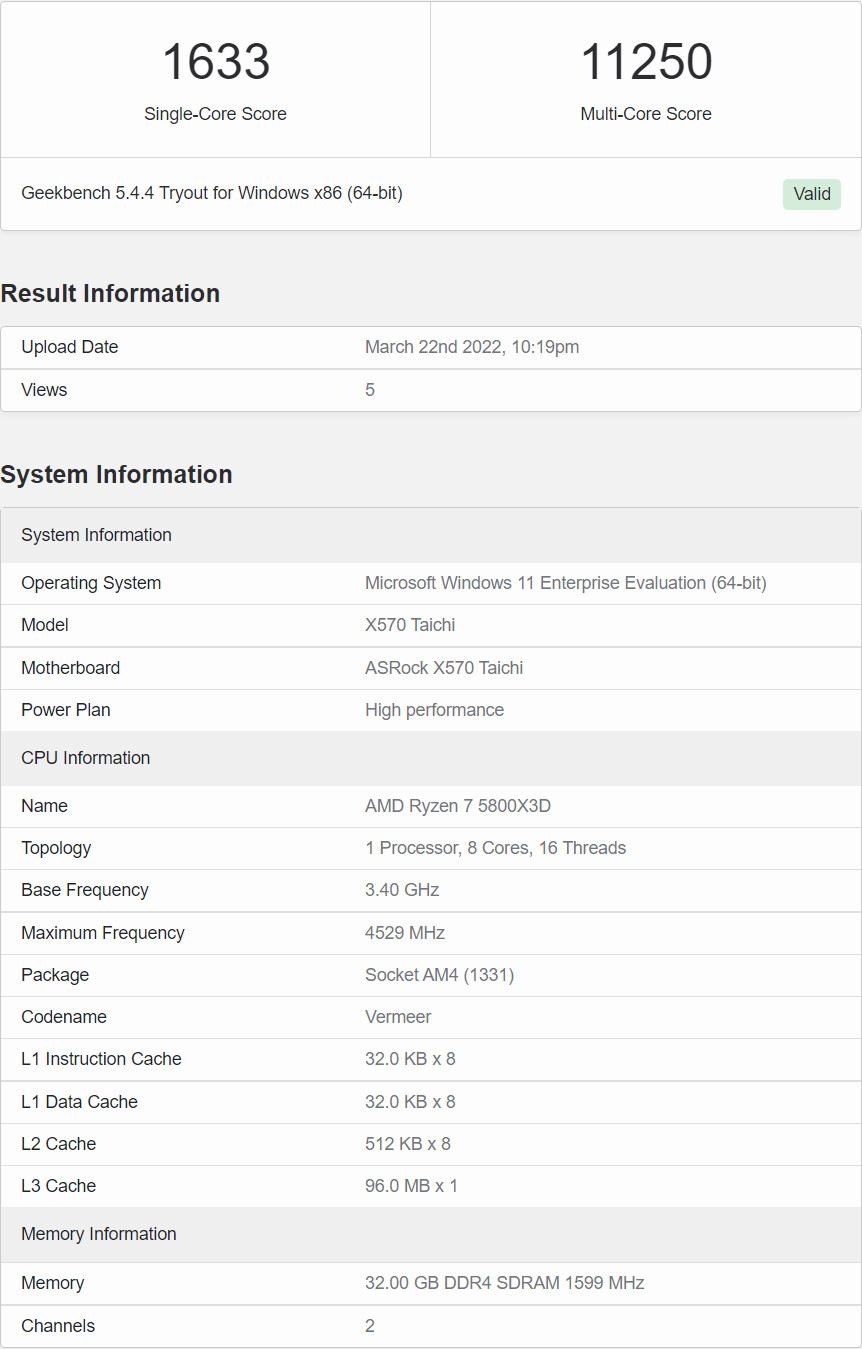
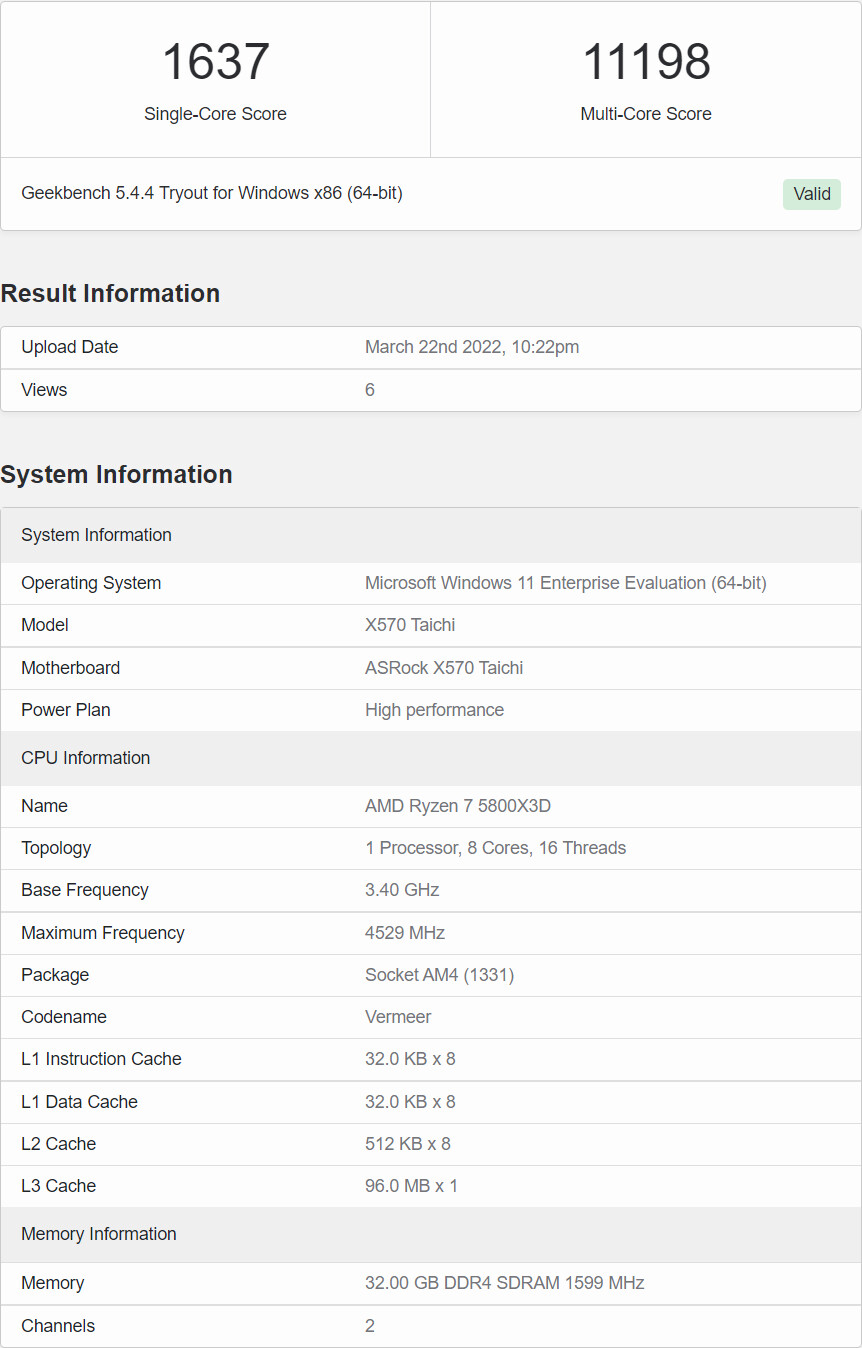
Someone with access to an AMD Ryzen 7 5800X3D processor sample posted some of the first Geekbench 5 performance numbers for the chip, where it ends up 9% faster than the Ryzen 7 5800X, on average. AMD claimed that the 5800X3D is "the world's fastest gaming processor," with the 3D Vertical Cache (3D V-cache) technology offering gaming performance uplifts over the 5800X akin to a new generation, despite being based on the same "Zen 3" microarchitecture, and lower clock speeds. The Ryzen 7 5800X3D is shown posting scores of 1633 points 1T and 11250 points nT in one run; and 1637/11198 points in the other; when paired with 32 GB of dual-channel DDR4-3200 memory.
These are 9% faster than a typical 5800X score on this benchmark. AMD's own gaming performance claims see the 5800X3D score a performance uplift above 20% over the 5800X, closing the gap with the Intel Core i9-12900K. The 3D V-cache technology debuted earlier this week with the EPYC "Milan-X" processors, where the additional cache provides huge performance gains for applications with large data-sets. AMD isn't boasting too much about the multi-threaded productivity performance of the 5800X3D because this is ultimately an 8-core/16-thread processor that's bound to lose to the Ryzen 9 5900X/5950X, and the i9-12900K, on account of its lower core-count.

Source:
Wccftech
These are 9% faster than a typical 5800X score on this benchmark. AMD's own gaming performance claims see the 5800X3D score a performance uplift above 20% over the 5800X, closing the gap with the Intel Core i9-12900K. The 3D V-cache technology debuted earlier this week with the EPYC "Milan-X" processors, where the additional cache provides huge performance gains for applications with large data-sets. AMD isn't boasting too much about the multi-threaded productivity performance of the 5800X3D because this is ultimately an 8-core/16-thread processor that's bound to lose to the Ryzen 9 5900X/5950X, and the i9-12900K, on account of its lower core-count.
105 Comments on AMD Ryzen 7 5800X3D Geekbenched, About 9% Faster Than 5800X
We know that there is a inter-CCD penalty in the 5950X, however milder that may be against its predecessor, but in real-world scenarios, I never really needed to be mindful of core affinity to get the best out of my system.
Either way, it's not really skepticism as much as it is just having quite tempered expectations. I find this technology exciting, even if I am not expecting it to be revolutionary in this first iteration (i.e. I do not think this will dethrone Golden Cove). Regarding silicon changes, Vermeer B2, like AMD stated, brought no changes to the experience (they do not seem to clock better, or have any difference in how they function), and this is the only one that has any actual tangible difference in its design. For a long time I associated the unusually good performance of my old 18-core Xeon Haswell CPU to its (at the time) vast 45 MB L3, even though it has the clock speed of molasses (2.9 linear and 2.4 in AVX) and a relative penalty from the dual ring bus and signaling (semaphore) bit, so it would be less overestimating silicon changes over just curiosity about how would the microarchitecture respond to such changes in topology, and how that would generate any practical benefit to the end user.
The definitive answer to that we will see when reviews land in mid-April, I suppose.
:toast:
They can use more threads, but very few truly do, or not for long periods.