Tuesday, August 23rd 2022

AMD Zen 4 EPYC CPU Benchmarked Showing a 17% Single Thread Performance Increase from Zen 3
The next-generation flagship AMD GENOA EPYC CPU has recently appeared on Geekbench 5 in a dual-socket configuration for a total of 192 cores and 384 threads. The processors were installed in an unknown Suma 65GA24 motherboard running at 3.51 GHz and paired with 768 GB of DDR5 memory. This setup achieved a single-core score of 1460 and multi-core result of 96535 which places the processor approximately 17% ahead of an equivalently clocked 128 core EPYC 7763 in single-threaded performance. The Geekbench listing also includes an OPN code of 100-000000997-01 which most likely corresponds to the flagship AMD EPYC 9664 with a max TDP of 400 W according to existing leaks.

Sources:
Geekbench (via @moe_v_moe), Wccftech
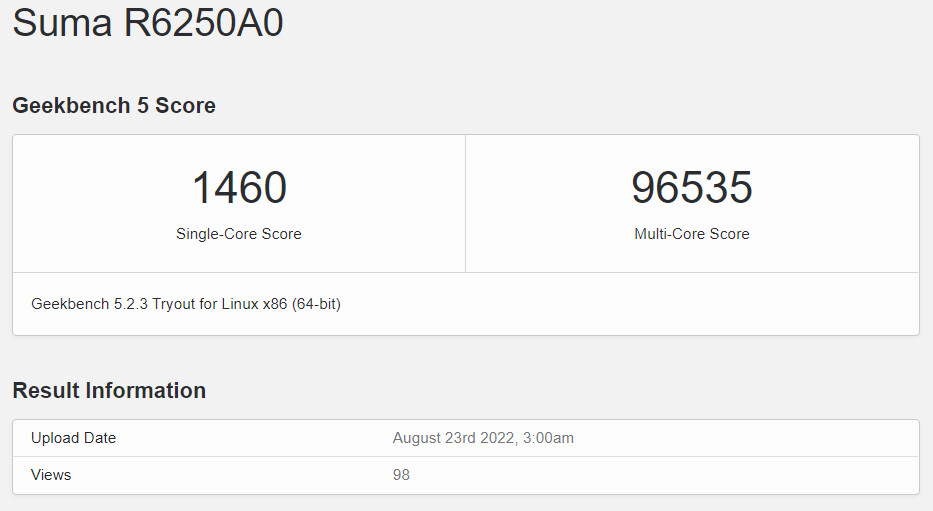
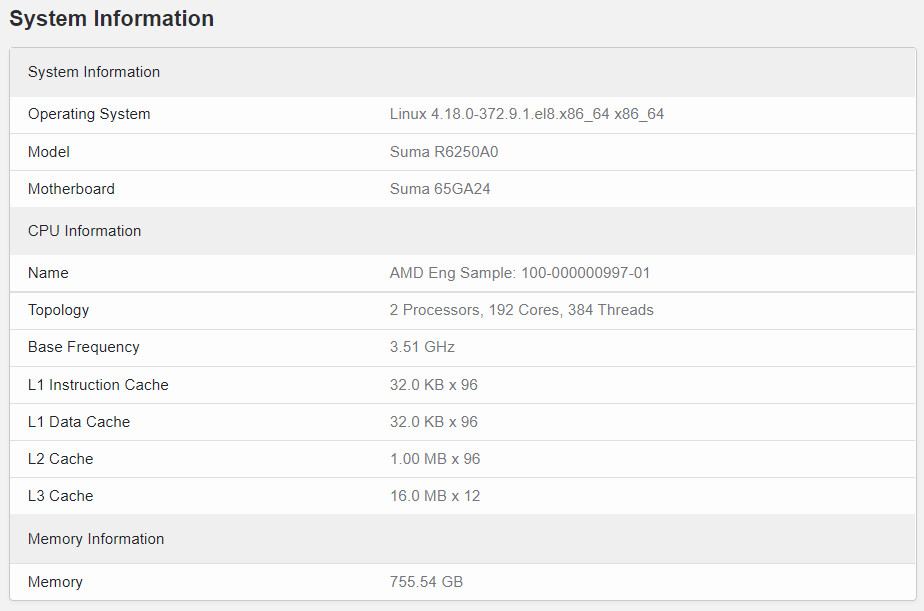
37 Comments on AMD Zen 4 EPYC CPU Benchmarked Showing a 17% Single Thread Performance Increase from Zen 3
I meant that there is a fair chance that AMD will launch Zen 4 EPYC CPU with V-Cache "at the same time" as the non V-Cache EPYC CPU's as they are (as far as I know) expected to launch sometime in Q1-Q2, and the of course use the same compute dies as the desktop CPU's, so the V-Cache compute dies should be ready at the same time as the EPYC Zen 4 launch. I will edit my original post for clarification.
Having watched all of the above video that I posted, it seems that AMD will (paper) launch Zen 4 with V-Cache when Intel launches (mostly on paper) Raptor Lake. Zen 4 (desktop) with V-Cache CPU's are expected to be on shelves in the first quarter.
:D Exciting times for us tech nerds.
There are instances where the cache could also be of more importance in a game than the core count as well which 5800X3D kind of already illustrates it beats the same Zen 3 chip cores with fewer of them. We saw a similar scenario with Intel and Broadwell with eDRAM in terms of the cache doing really well in certain tasks gaming in particular can saturate lots of cache access.
The cache dies that are put on the top of the compute dies are only made in one size right now, it is possible to stack them, and it is likely that will happen to increase the L3 cache even further. However, it is very unlikely that AMD will make different cache dies for their SoC's as the manufacturing complexity would be even higher due to their integrated layer and the extra processing needed to fit the cache dies, as these are CPU's that are aimed at a lower (and cheaper) market segment, one where they already have HALF the amount of L3, this is IMHO very unlikely to happen.
Yes it would be nice to see it happen (just to see the test results, AMD already knows as it would have accurately simulated all of these possibilities), but it's all down to cost vs benefit when it comes to actually manufacturing and selling CPU's. Also remember that AMD doesn't have an unlimited amount of silicon production, so it has to chose wisely what that production is used for.!
Here is something to chew on, (mostly confirmed) rumours are that Zen 5 has quite a "quite changed" cache arrangement, they will be drop in compatible (with BIOS update) with this generation of AM5 motherboards, which likely means that the I/O die will be either the same, or a tweaked / updated version of the 7000 Series, and the compute die(s) will have that "quite changed" cache arrangement. I have no idea what that means right now, we will find out in leaks over the next few months. IMHO, "if" AMD can, they will put the cache dies on the bottom of the compute dies for better thermals, but I have no idea if that is possible, and is not actually required. I am guessing that the changes will be to the L1, L2 and L3 all at once, and likely L3 sharing between dies (essentially pseudo L4 as IBM uses on it's Power CPU's).
Enjoy postulating :D
Also, here is the latest Zen 4 X3D (3D V-Cache) leak +
Enjoy.
Addendum: This video answers some of your questions about extra cache on certain models, 3D V-Cache will be coming to Zen 4 desktop replacement types of laptops "Dragon Range" code name, now to watch the 2nd half of this video...
Is this faster than going out to system RAM? Yes
Can this cause more Cache misses etc? Yes!
Its why I have sort of been surprised this 2nd Gen I/O die hasnt had HBM provisions to act as a large L4 cache. Maybe for the 4th Gen Threadripper pro/Epyc.
HBM as L4 might not be the best since it's not really a low latency memory. It's a high bandwdith. And to get your high bandwidth, you need a lot of concurrent access to get the maximum bandwidth. This is why it's more looked at in high core counts cpu servers or GPU.
Would a L4 cache in the I/O die would really be useful, that depend, it would be complicated. If the goal is to save a roundtrip to memory when there is data on the other CCD chips, that would means that the L4 would be inclusive with L3. So when you write data into L3, you would have to also write it at the same time on L4. This could slow down L3 quite a lot. It will be a matter of tradeoff.
The other thing is the I/O die is made on a older node, adding a large amount of sram would increase the die size. It could be added as 3d-vcache maybe. but that would be a significant increase in cost too.
But for Datacenter uses and feeding 96 Cores I can see HBM being beneficial on top of the 3DVcache. Being able to have multiple Gb of L4 cache would be beneficial for database/mathematical simulations etc especially with HBM2e and theoretically HMB3
I suspect the I/O die would have to be completely redesigned to take advantage of it as HBM is extremtley Pin dense to get the advantages of the bandwidth.