Wednesday, August 24th 2022

NVIDIA Hopper Features "SM-to-SM" Comms Within GPC That Minimize Cache Roundtrips and Boost Multi-Instance Performance
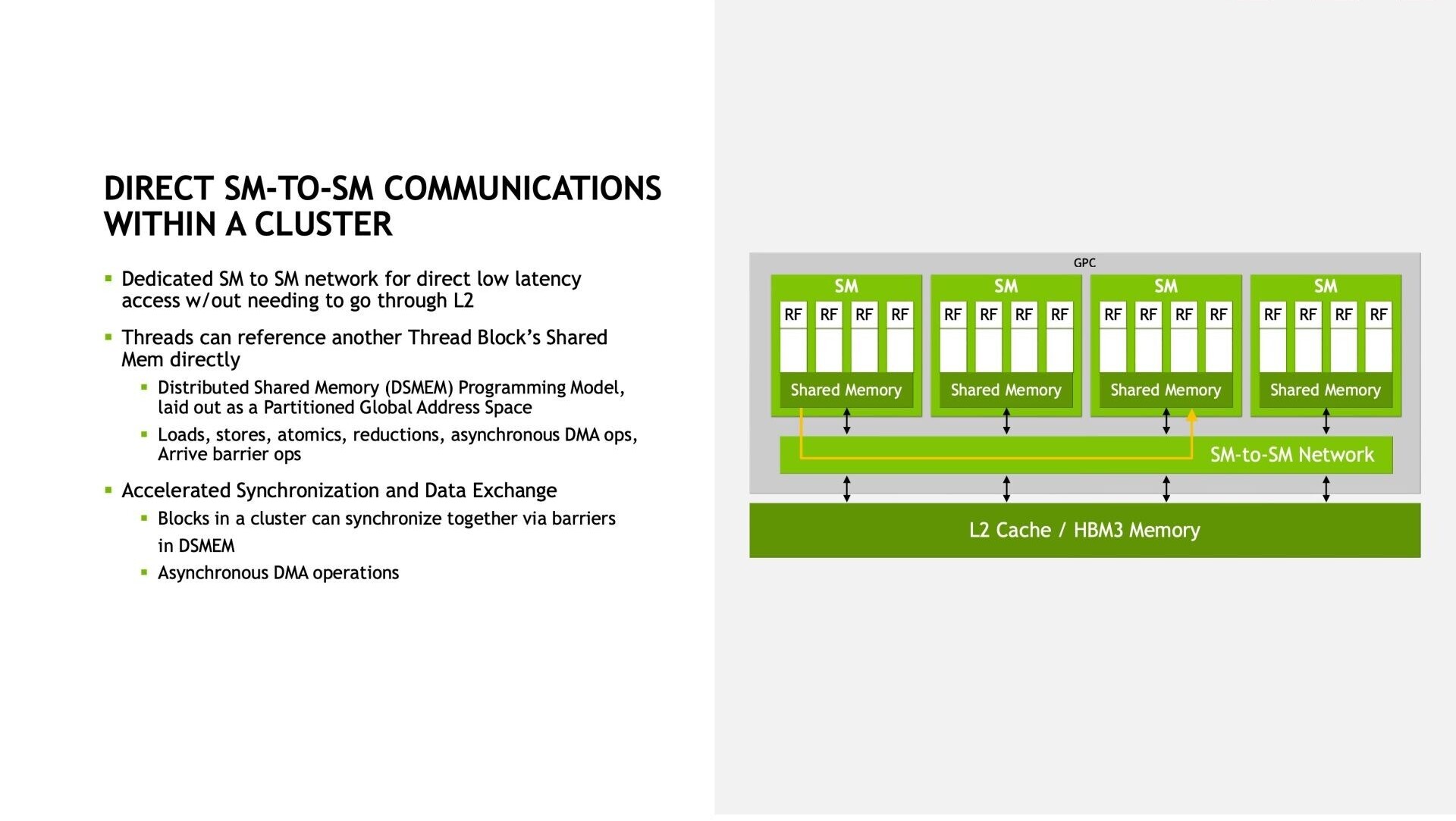
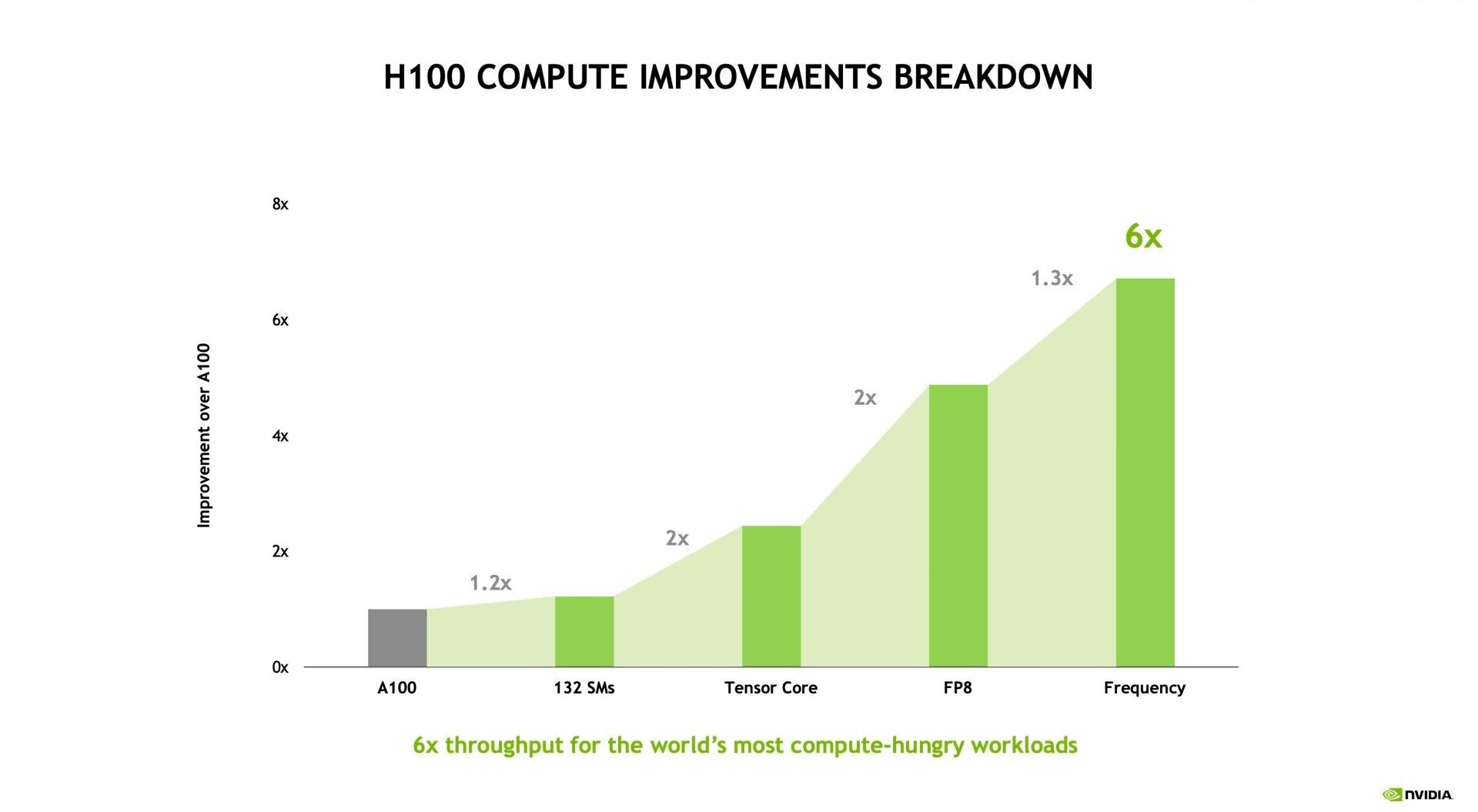
NVIDIA in its HotChips 34 presentation revealed a defining feature of its "Hopper" compute architecture that works to increase parallelism and help the H100 processor better perform in a multi-instance environment. The hardware component hierarchy of "Hopper" is typical of NVIDIA architectures, with GPCs, SMs, and CUDA cores forming a hierarchy. The company is introducing a new component it calls "SM to SM Network." This is a high-bandwidth communications fabric inside the Graphics Processing Cluster (GPC), which facilitates direct communication among the SMs without making round-trips to the cache or memory hierarchy, play a significant role in NVIDIA's overarching claim of "6x throughput gain over the A100."
Direct SM-to-SM communication not just impacts latency, but also unburdens the L2 cache, letting NVIDIA's memory-management free up the cache of "cooler" (infrequently accessed) data. CUDA sees every GPU as a "grid," every GPC as a "Cluster," every SM as a "thread block," and every lane of SIMD units as a "lane." Each lane has a 64 KB of shared memory, which makes up 256 KB of shared local storage per SM as there are four lanes. The GPCs interface with 50 MB of L2 cache, which is the last-level on-die cache before the 80 GB of HBM3 serves as main memory.


Source:
HardwareLuxx.de
Direct SM-to-SM communication not just impacts latency, but also unburdens the L2 cache, letting NVIDIA's memory-management free up the cache of "cooler" (infrequently accessed) data. CUDA sees every GPU as a "grid," every GPC as a "Cluster," every SM as a "thread block," and every lane of SIMD units as a "lane." Each lane has a 64 KB of shared memory, which makes up 256 KB of shared local storage per SM as there are four lanes. The GPCs interface with 50 MB of L2 cache, which is the last-level on-die cache before the 80 GB of HBM3 serves as main memory.

2 Comments on NVIDIA Hopper Features "SM-to-SM" Comms Within GPC That Minimize Cache Roundtrips and Boost Multi-Instance Performance