Thursday, August 10th 2023

AMD "Strix Point" Company's First Hybrid Processor, 4P+8E ES Surfaces
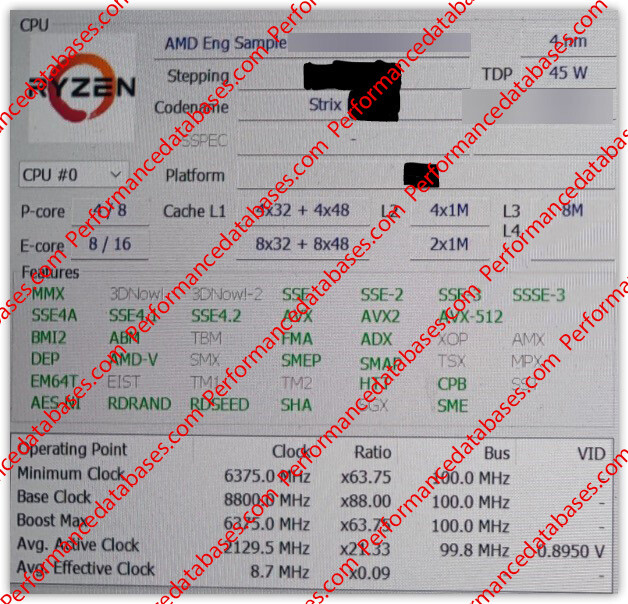
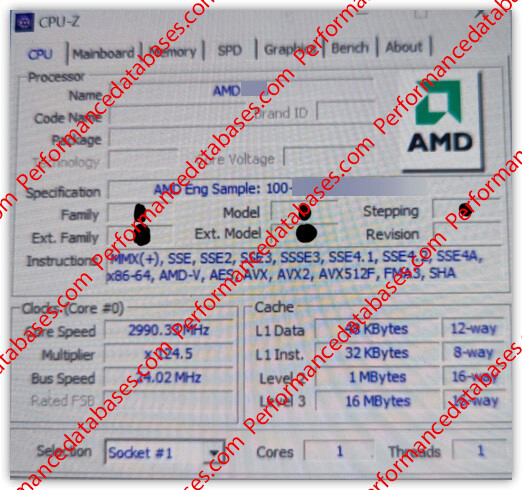
Beating previous reports that AMD is increasing the CPU core count of its mobile monolithic processors from the present 8-core/16-thread to 12-core/24-thread; we are learning that the next-gen processor from the company, codenamed "Strix Point," will in fact be the company's first hybrid processor. The chip is expected to feature two kinds of CPU cores, with "Zen 5" being the microarchitecture behind the performance cores, and "Zen 5c" behind the efficiency cores. An engineering sample featuring 4 P-cores, and 8 E-cores, surfaced on the web, thanks to Performancedatabases. A HWiNFO screenshot reveals the engineering sample's core-configuration of 4x P-cores and 8x E-cores, with identical L1 cache sizes. Things get a little fuzzy with the L2 cache size detection, and L3 cache.
We know from the current "Zen 4c" core design that it is essentially a compacted version of "Zen 4" designed for higher-density chiplets that have 16 cores; and that it has both the same ISA and IPC as "Zen 4," with the only difference being that "Zen 4c" is designed with lower amounts of shared L3 caches at their disposal, are generally configured with lower clock speeds, and have higher energy efficiency than "Zen 4." "Zen 4c" cores also 35% smaller in die-area than "Zen 4." The company could develop "Zen 5c" CPU cores with similar design goals.
 The "Strix Point" silicon could hence have two CCX (CPU core complexes); one of which has the larger "Zen 5" P-cores and certain amount of L3 cache, and another CCX with the smaller "Zen 5c" cores, and their own L3 caches. This would essentially be similar to "Renoir," which has two 4-core CCXs of "Zen 2" cores. The L1 cache sizes for both kinds of cores is identical—48 KB L1D and 32 KB L1I, and it's likely that both core types have 1 MB of dedicated L2 caches per core. The L3 cache sizes could vary between the two CCXs, with the P-core CCX having 16 MB (4 MB per core), and the E-core CCX 8 MB (512 KB per core).
The "Strix Point" silicon could hence have two CCX (CPU core complexes); one of which has the larger "Zen 5" P-cores and certain amount of L3 cache, and another CCX with the smaller "Zen 5c" cores, and their own L3 caches. This would essentially be similar to "Renoir," which has two 4-core CCXs of "Zen 2" cores. The L1 cache sizes for both kinds of cores is identical—48 KB L1D and 32 KB L1I, and it's likely that both core types have 1 MB of dedicated L2 caches per core. The L3 cache sizes could vary between the two CCXs, with the P-core CCX having 16 MB (4 MB per core), and the E-core CCX 8 MB (512 KB per core).
It would be interesting to imagine how AMD handles the hybrid architecture from a software standpoint. Intel uses Thread Director, a hardware-based solution that's designed to send the right kind of compute workload to the right kind of CPU core. AMD could either try to develop its own version of Thread Director, or use a less sophisticated OS-based solution such as what it's doing with its multi-CCD client processors.
Sources:
Performancedatabases, IThome, VideoCardz
We know from the current "Zen 4c" core design that it is essentially a compacted version of "Zen 4" designed for higher-density chiplets that have 16 cores; and that it has both the same ISA and IPC as "Zen 4," with the only difference being that "Zen 4c" is designed with lower amounts of shared L3 caches at their disposal, are generally configured with lower clock speeds, and have higher energy efficiency than "Zen 4." "Zen 4c" cores also 35% smaller in die-area than "Zen 4." The company could develop "Zen 5c" CPU cores with similar design goals.
It would be interesting to imagine how AMD handles the hybrid architecture from a software standpoint. Intel uses Thread Director, a hardware-based solution that's designed to send the right kind of compute workload to the right kind of CPU core. AMD could either try to develop its own version of Thread Director, or use a less sophisticated OS-based solution such as what it's doing with its multi-CCD client processors.
86 Comments on AMD "Strix Point" Company's First Hybrid Processor, 4P+8E ES Surfaces
chipsandcheese.com/2022/11/08/amds-zen-4-part-2-memory-subsystem-and-conclusion/
chipsandcheese.com/2022/11/08/amds-zen-4-part-2-memory-subsystem-and-conclusion/
chipsandcheese.com/2023/07/17/genoa-x-server-v-cache-round-2/
Compare the top rows, keeping core counts in mind
You can clearly see that while AMD suffers an inter-CCX penalty, cores within each CCX can communicate with each other a lot easier and faster than anything on the intel side - most inter-core communication is half the latency.
Intel has that little narrow chance of getting things done faster with cores side by side, but outside that the latency is massively higher
12900K for comparison, too
HECK LETS GET EM ALL IN ONE POST
Now thats a generational leap in improvements - halving the values in the same CCX
What stands out is that as soon as E-cores are introduced, is when the latency penalty hits - the 10600K manages lower values all around up until CPU8
Can i interpret this stuff?
not yet. Some of it's pretty obvious, like ryzen tending to be faster within a CCX, and slower inter-CCX (Which we already knew single CCX designs were better for latency sensitive stuff like gaming)
Current gen 4 SKU types (7600x 7700x and 7800X3d, and distantly rocket lake with a ring OC and e cores off) that have good latency - and all of those are basically going away unless AMD pushes 8800X3D (with hopefully a 12 core CCD, but even 8 core will be good) -- Intel is only going to make tile chips from now on, and AMD is moving in that same direction for most of the product stack.
10900k and 10600k with ringbus were MUCH lower (their worst core to core latency is 24ns). Plus older motherboards had simpler bioses, and older OSes much lighter and weren't trying to nanny the kernel inside a virtual machine while trying to play hide-and-seek with high entropy memory etc, and nvidia's drivers were'nt gigantic bloated packages.
TLDR - zen5 will have probably 3 SKUs, with x3d being the best for latency but literally every other facet in the system is adding overall latency (and my guess is strix point will have terrible latency bc of + ccd of hybrid cores + software scheduler).
3950x has 8 cores (+SMT) then another CCX of the same
Latency matches that, with 8 cores having consistent latency between each other.
Zero argument the 13900k is better overall - but the latency creeps up once you pass two threads, and just keeps climbing.
Something hits them hard when multiple cores are active, it's a very large regression and if people don't make a fuss about it, it wont be something they fix.
You compare either to the 10600K, and things look really weird
The 10900K made it weirder again, because just two of the threads have crazy latency and the rest are lower - performance would be erratic as heck if things got scheduled onto those by the OS.
Different architectures are not apple to apples comparisons for sure, but the 10600k and 10900k are the same architecture and its from then on that things got weird and started going backwards, and some tasks definitely show it.
It's like they have low latency only for 1-2 threads, then the latency gets trashed in exchange for bandwidth - it's a hard shift and not a smooth curve or consistent result.
Either way the extra e core clusters and the ring of rings adds latency, but not nearly as much as a CCD cluster via infinity fabric.
Intel: All the P-cores have higher latency
AMD: Cores between CCX have higher latency
An AMD setup with 8 cores per CCX still has 8 cores that can talk faster to each other, than the intel setups
trying to crop these down so nothing relevant is missing, but still enough to explain what i'm meaning
These values are main cores and SMT, so 0-1 is core1 and it's SMT, then going on in pairs until you hit another CCX or E-core.
P-cores only vs two 8 core CCX's (Story doesn't change with three orfour CCXs)
Intel has a latency gain above 2 threads, not 2 cores but two threads. - and it's far worse than what AMD has there.
On AMD, 2 threads (0+1) is 6.6ns vs 4.0ns on intel - win for intel for sure.
But a 3 thread task using 2 physical cores (core 0 to core 2) breaks massively the other way with AMD being at 16.2ns and intel at 26.6ns - and intel stays being worse with latency until another CCX is involved.
When it comes to low latency tasks like gaming, you dont buy a CPU with E-cores or extra CCX's - we've known that for a while and this is the reason why.
TL;DR: Any task under 16 threads/ 8 cores has lower latency on AMD now. Intel's advantage is now only for 1-2 cores.
Following the values we've found in these fancy charts, they match up with gaming performance fairly well - intel would have a large boost when games stick with the typical 1-2 threads that was common for a long time, then fall down if they need to sync with other cores
AMD Ryzen 9 7950X3D Review - Best of Both Worlds - Minimum FPS / RTX 4090 | TechPowerUp
Heavily single-threaded engine:
cache sensitive engine
heavily multi threaded engine known for 100% CPU usage on 4c/8t CPUs
Am i saying these latency values are the most important value at all? nope!
Just that they are important and we need to know and care if things slip backwards.
as an example of why it matters, is that you need high clock speeds and brute force power to compensate for things like this so we end up with insane differences like this
5800x3D to 13900K:
275% more power for 1.7% higher FPS minimums?
Why? Because it needs to clock insanely high to brute force things, it's like the pentium 4 all over again.
Oh i suppose this chart explains it: It's dominated by single CCX hardware (And P-core only intels), with the exception of the 7000 series 3D parts where you can lock a game to use them exclusively and it becomes single CCX as far as that games concerned
I dont want EITHER company to go down the road of throwing us the scraps from enterprise customers designs to help recover R&D costs, in ways that are actually regressions.
Gamers don't need more performance in R23, they just need 6+ cores in the same CPU without latency issues.
Phoenix2's x-ray picture has been published, showing very clearly 2x Zen4 and 4x Zen4c cores.
zhuanlan.zhihu.com/p/653961282
www.tomshardware.com/news/amd-phoenix-2-review-evaluates-zen-4-zen-4c-performanceThis chip is a smaller and lower power version of the Phoenix APU, with 2x Zen4 and 4x Zen4c cores, and only 2x WGP RDNA3.
Phoenix (7840U, Z1 Extreme) was aimed at 20-45W and it runs pretty poorly below 15W. Phoenix2 (7440U, Z1) probably does very well below 15W for its tiny GPU and lower-clocked / denser efficiency cores.
Gaming performance on the Z1 might be very similar to the Steam Deck's Van Gogh, perhaps at a lower power (especially if the Zen4 vanilla cores can be disabled somehow).
For those looking at the ROG Ally and Legion Go for emulation, the Z1 versions should be ideal, as it still gets AVX512.
Regardless, that's water under the bridge and I'm happy this has been corrected in the news post of today.