Industry's First-to-Market Supermicro NVIDIA HGX B200 Systems Demonstrate AI Performance Leadership
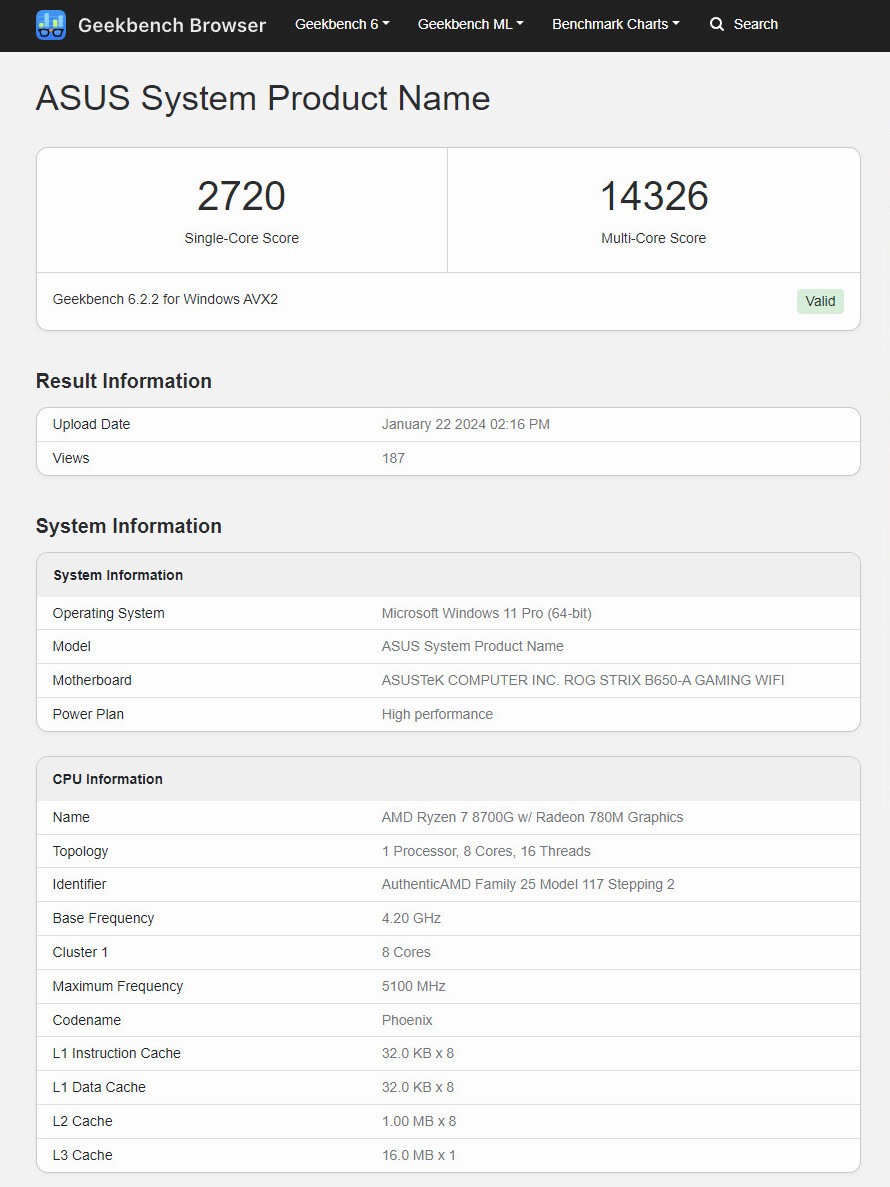
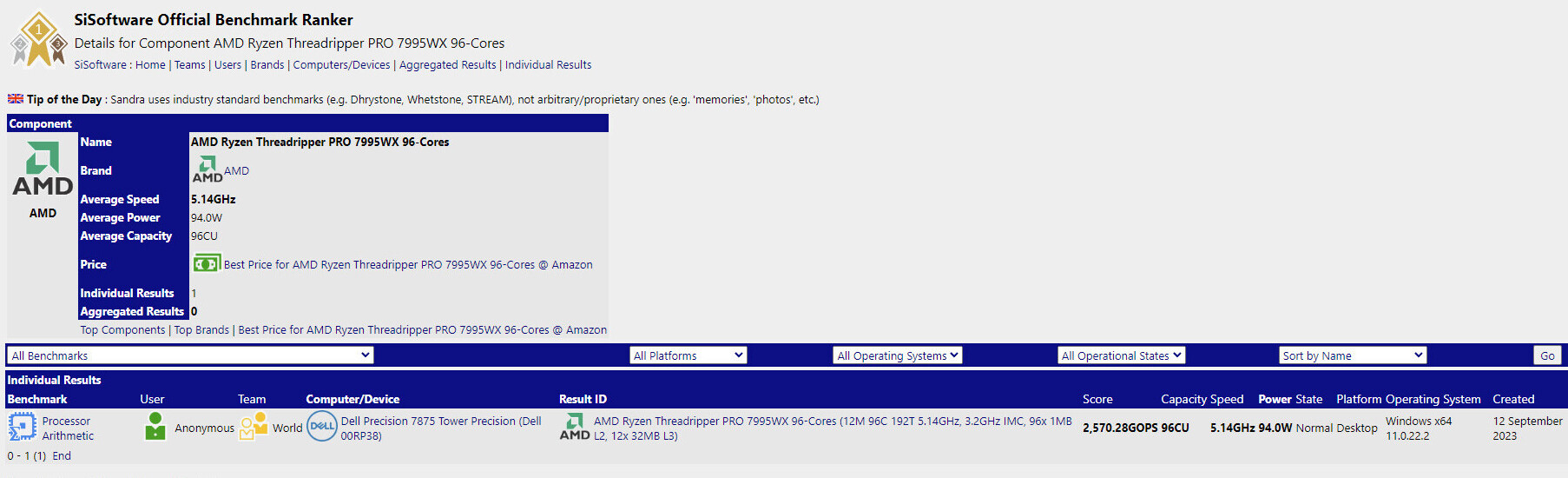
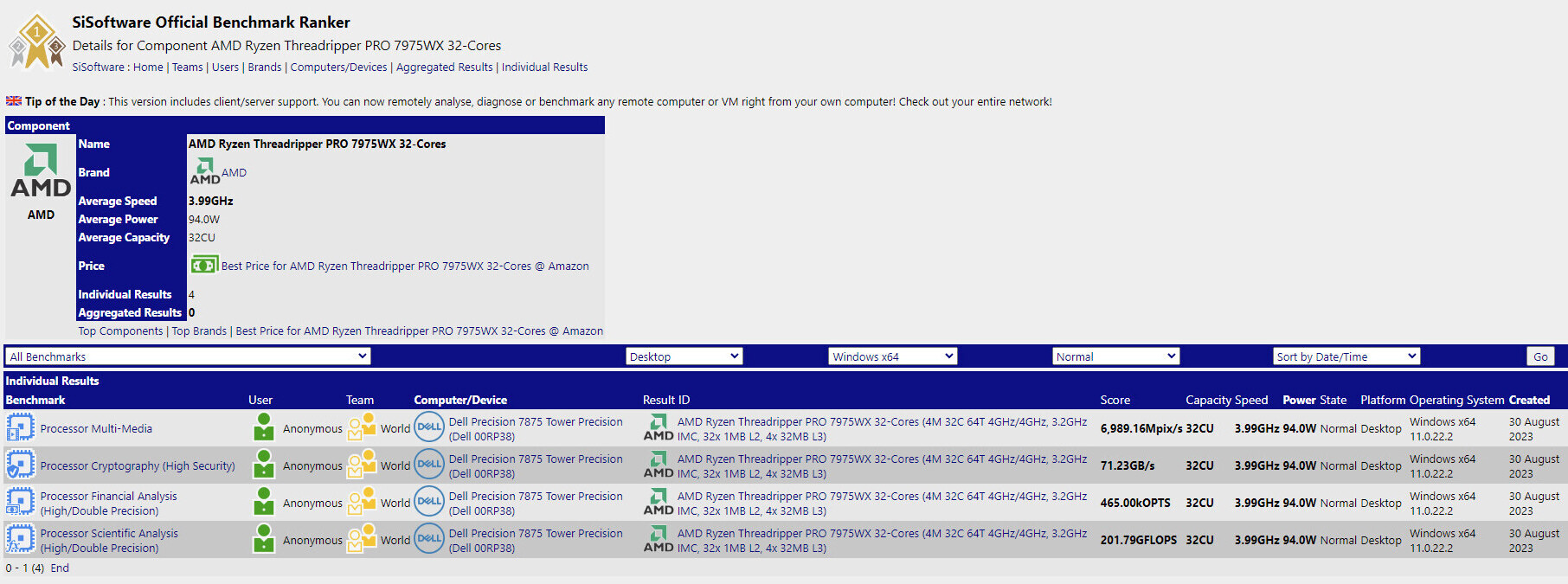
Super Micro Computer, Inc. (SMCI), a Total IT Solution Provider for AI/ML, HPC, Cloud, Storage, and 5G/Edge, has announced first-to-market industry leading performance on several MLPerf Inference v5.0 benchmarks, using the 8-GPU. The 4U liquid-cooled and 10U air-cooled systems achieved the best performance in select benchmarks. Supermicro demonstrated more than 3 times the tokens per second (Token/s) generation for Llama2-70B and Llama3.1-405B benchmarks compared to H200 8-GPU systems. "Supermicro remains a leader in the AI industry, as evidenced by the first new benchmarks released by MLCommons in 2025," said Charles Liang, president and CEO of Supermicro. "Our building block architecture enables us to be first-to-market with a diverse range of systems optimized for various workloads. We continue to collaborate closely with NVIDIA to fine-tune our systems and secure a leadership position in AI workloads." Learn more about the new MLPerf v5.0 Inference benchmarks here.
Supermicro is the only system vendor publishing record MLPerf inference performance (on select benchmarks) for both the air-cooled and liquid-cooled NVIDIA HGX B200 8-GPU systems. Both air-cooled and liquid-cooled systems were operational before the MLCommons benchmark start date. Supermicro engineers optimized the systems and software to showcase the impressive performance. Within the operating margin, the Supermicro air-cooled B200 system exhibited the same level of performance as the liquid-cooled B200 system. Supermicro has been delivering these systems to customers while we conducted the benchmarks. MLCommons emphasizes that all results be reproducible, that the products are available and that the results can be audited by other MLCommons members. Supermicro engineers optimized the systems and software, as allowed by the MLCommons rules.

Supermicro is the only system vendor publishing record MLPerf inference performance (on select benchmarks) for both the air-cooled and liquid-cooled NVIDIA HGX B200 8-GPU systems. Both air-cooled and liquid-cooled systems were operational before the MLCommons benchmark start date. Supermicro engineers optimized the systems and software to showcase the impressive performance. Within the operating margin, the Supermicro air-cooled B200 system exhibited the same level of performance as the liquid-cooled B200 system. Supermicro has been delivering these systems to customers while we conducted the benchmarks. MLCommons emphasizes that all results be reproducible, that the products are available and that the results can be audited by other MLCommons members. Supermicro engineers optimized the systems and software, as allowed by the MLCommons rules.