NVIDIA Fine-Tunes Llama3.1 Model to Beat GPT-4o and Claude 3.5 Sonnet with Only 70 Billion Parameters
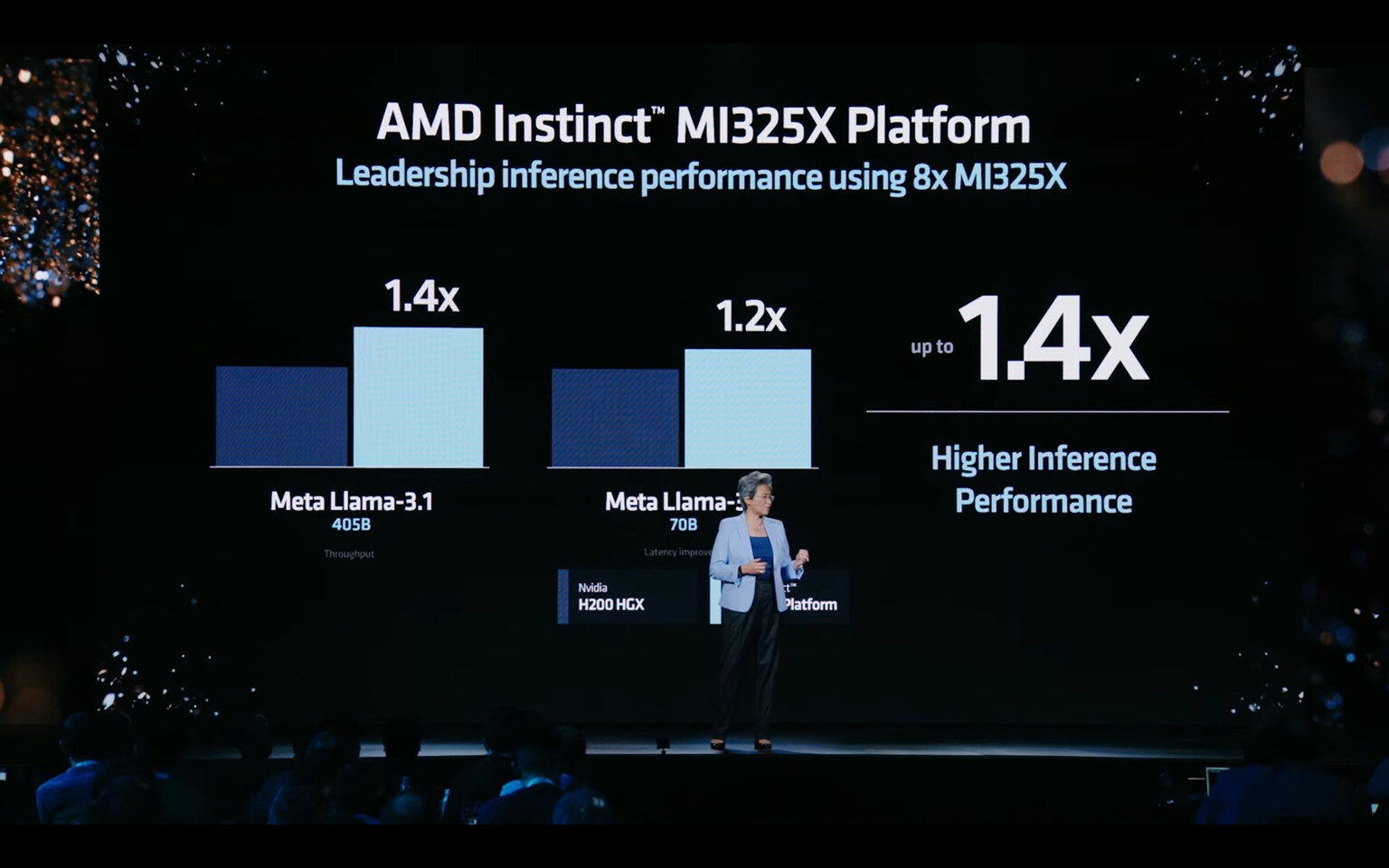
NVIDIA has officially released its Llama-3.1-Nemotron-70B-Instruct model. Based on META's Llama3.1 70B, the Nemotron model is a large language model customized by NVIDIA in order to improve the helpfulness of LLM-generated responses. NVIDIA uses fine-tuning structured data to steer the model and allow it to generate more helpful responses. With only 70 billion parameters, the model is punching far above its weight class. The company claims that the model is beating the current top models from leading labs like OpenAI's GPT-4o and Anthropic's Claude 3.5 Sonnet, which are the current leaders across AI benchmarks. In evaluations such as Arena Hard, the NVIDIA Llama3.1 Nemotron 70B is scoring 85 points, while GPT-4o and Sonnet 3.5 score 79.3 and 79.2, respectively. Other benchmarks like AlpacaEval and MT-Bench spot NVIDIA also hold the top spot, with 57.6 and 8.98 scores earned. Claude and GPT reach 52.4 / 8.81 and 57.5 / 8.74, just below Nemotron.
This language model underwent training using reinforcement learning from human feedback (RLHF), specifically employing the REINFORCE algorithm. The process involved a reward model based on a large language model architecture and custom preference prompts designed to guide the model's behavior. The training began with a pre-existing instruction-tuned language model as the starting point. It was trained on Llama-3.1-Nemotron-70B-Reward and HelpSteer2-Preference prompts on a Llama-3.1-70B-Instruct model as the initial policy. Running the model locally requires either four 40 GB or two 80 GB VRAM GPUs and 150 GB of free disk space. We managed to take it for a spin on NVIDIA's website to say hello to TechPowerUp readers. The model also passes the infamous "strawberry" test, where it has to count the number of specific letters in a word, however, it appears that it was part of the fine-tuning data as it fails the next test, shown in the image below.



This language model underwent training using reinforcement learning from human feedback (RLHF), specifically employing the REINFORCE algorithm. The process involved a reward model based on a large language model architecture and custom preference prompts designed to guide the model's behavior. The training began with a pre-existing instruction-tuned language model as the starting point. It was trained on Llama-3.1-Nemotron-70B-Reward and HelpSteer2-Preference prompts on a Llama-3.1-70B-Instruct model as the initial policy. Running the model locally requires either four 40 GB or two 80 GB VRAM GPUs and 150 GB of free disk space. We managed to take it for a spin on NVIDIA's website to say hello to TechPowerUp readers. The model also passes the infamous "strawberry" test, where it has to count the number of specific letters in a word, however, it appears that it was part of the fine-tuning data as it fails the next test, shown in the image below.