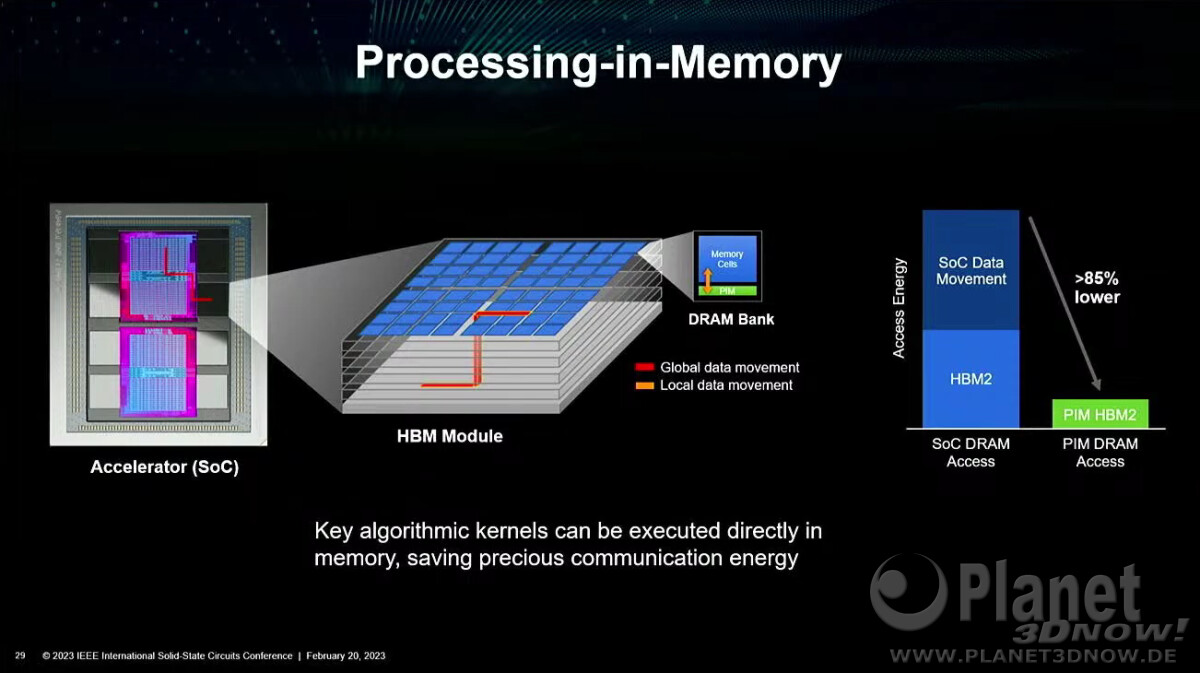
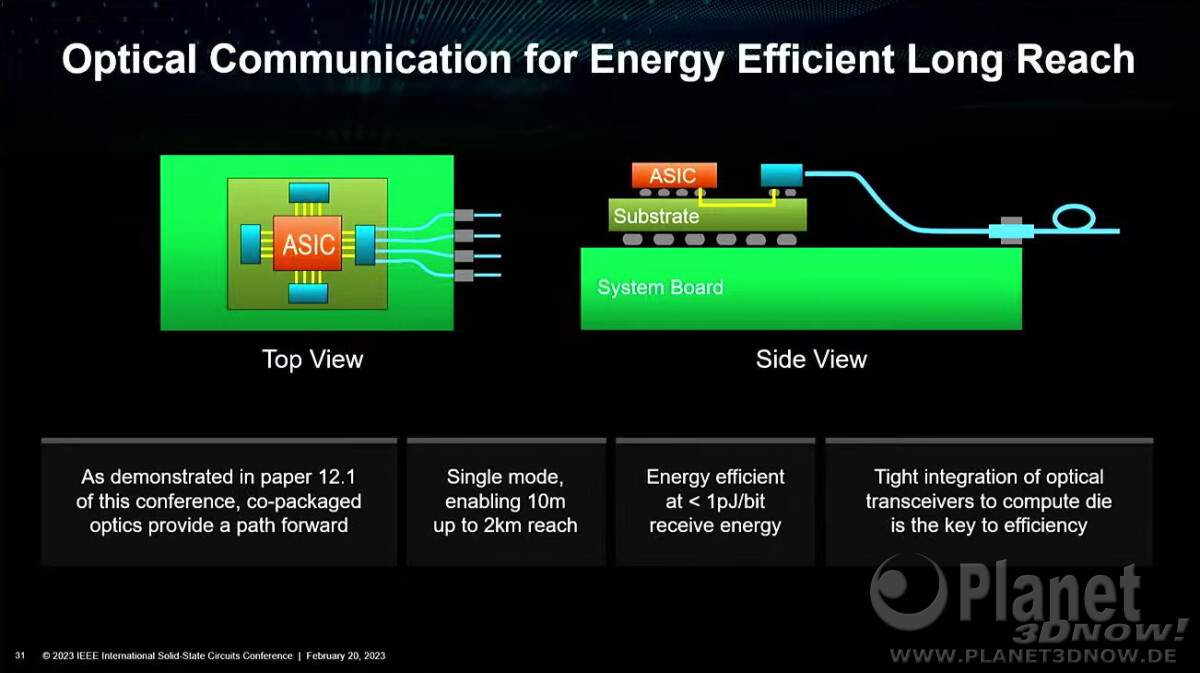
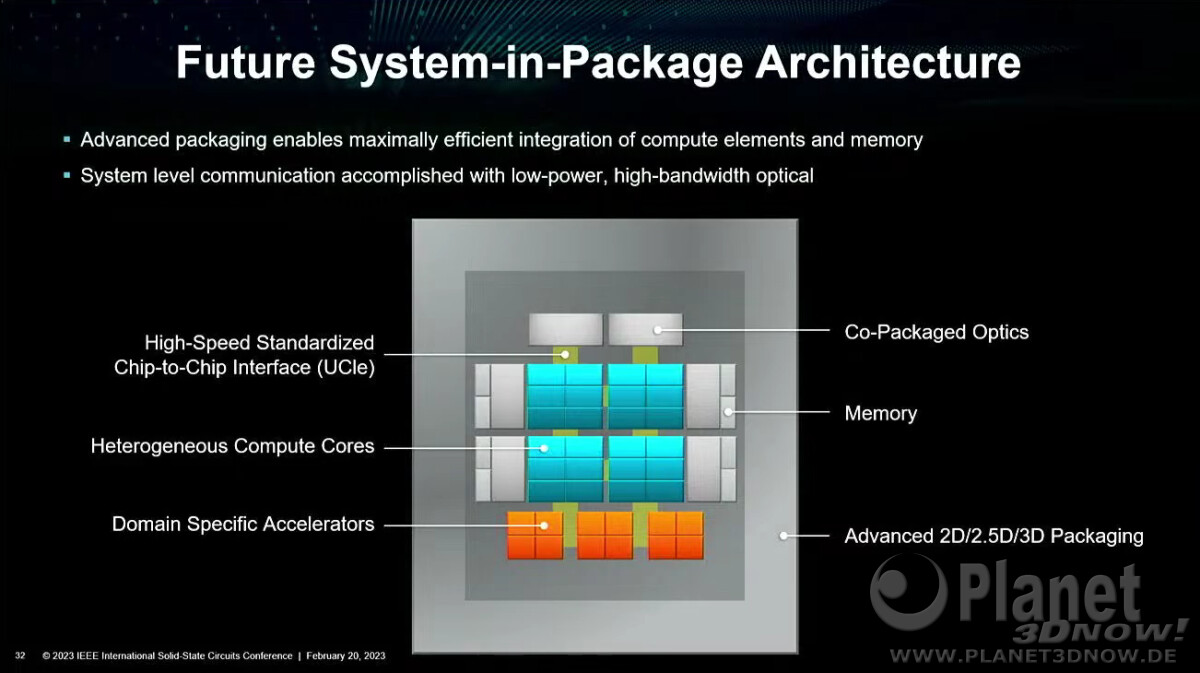
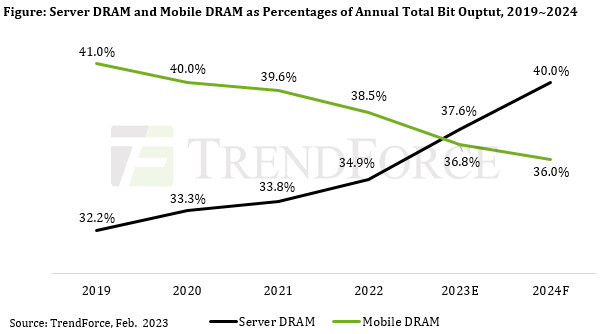
SK hynix Develops Industry's First 12-Layer HBM3, Provides Samples To Customers
SK hynix announced today it has become the industry's first to develop 12-layer HBM3 product with a 24 gigabyte (GB) memory capacity, currently the largest in the industry, and said customers' performance evaluation of samples is underway. HBM (High Bandwidth Memory): A high-value, high-performance memory that vertically interconnects multiple DRAM chips and dramatically increases data processing speed in comparison to traditional DRAM products. HBM3 is the 4th generation product, succeeding the previous generations HBM, HBM2 and HBM2E
"The company succeeded in developing the 24 GB package product that increased the memory capacity by 50% from the previous product, following the mass production of the world's first HBM3 in June last year," SK hynix said. "We will be able to supply the new products to the market from the second half of the year, in line with growing demand for premium memory products driven by the AI-powered chatbot industry." SK hynix engineers improved process efficiency and performance stability by applying Advanced Mass Reflow Molded Underfill (MR-MUF)# technology to the latest product, while Through Silicon Via (TSV)## technology reduced the thickness of a single DRAM chip by 40%, achieving the same stack height level as the 16 GB product.
"The company succeeded in developing the 24 GB package product that increased the memory capacity by 50% from the previous product, following the mass production of the world's first HBM3 in June last year," SK hynix said. "We will be able to supply the new products to the market from the second half of the year, in line with growing demand for premium memory products driven by the AI-powered chatbot industry." SK hynix engineers improved process efficiency and performance stability by applying Advanced Mass Reflow Molded Underfill (MR-MUF)# technology to the latest product, while Through Silicon Via (TSV)## technology reduced the thickness of a single DRAM chip by 40%, achieving the same stack height level as the 16 GB product.