Tuesday, February 21st 2023

AMD Envisions Stacked DRAM on top of Compute Chiplets in the Near Future
AMD in its ISSCC 2023 presentation detailed how it has advanced data-center energy-efficiency and managed to keep up with Moore's Law, even as semiconductor foundry node advances have tapered. Perhaps its most striking prediction for server processors and HPC accelerators is multi-layer stacked DRAM. The company has, for some time now, made logic products, such as GPUs, with stacked HBM. These have been multi-chip modules (MCMs), in which the logic die and HBM stacks sit on top of a silicon interposer. While this conserves PCB real-estate compared to discrete memory chips/modules; it is inefficient on the substrate, and the interposer is essentially a silicon die that has microscopic wiring between the chips stacked on top of it.
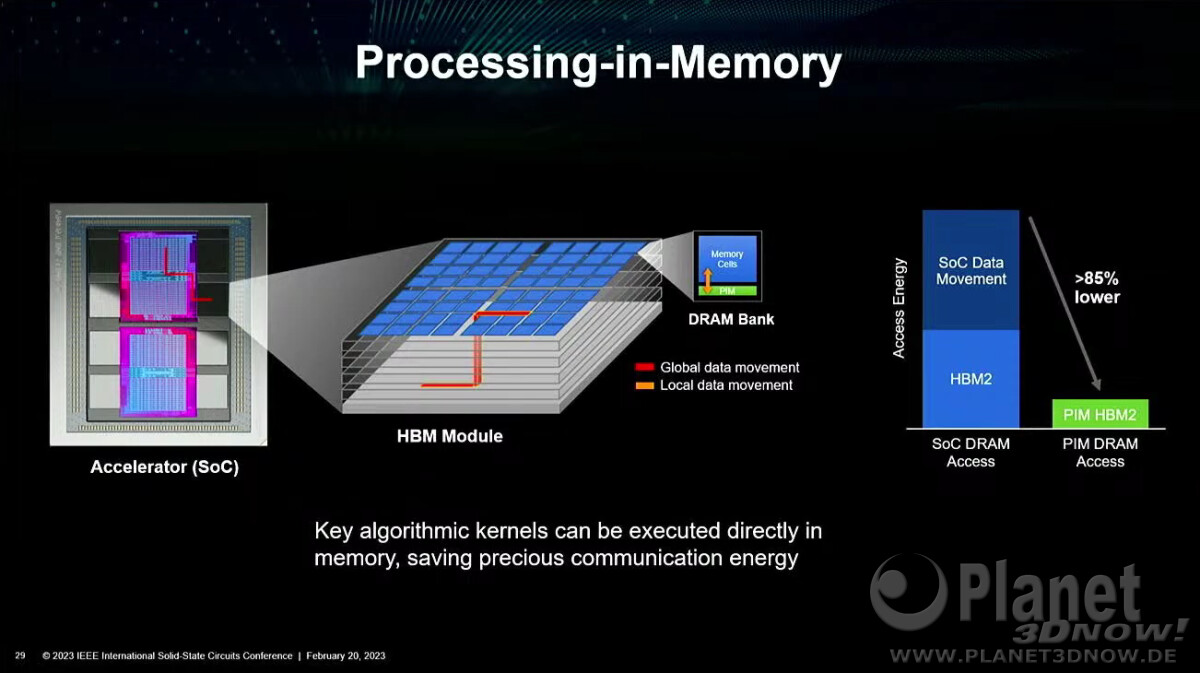
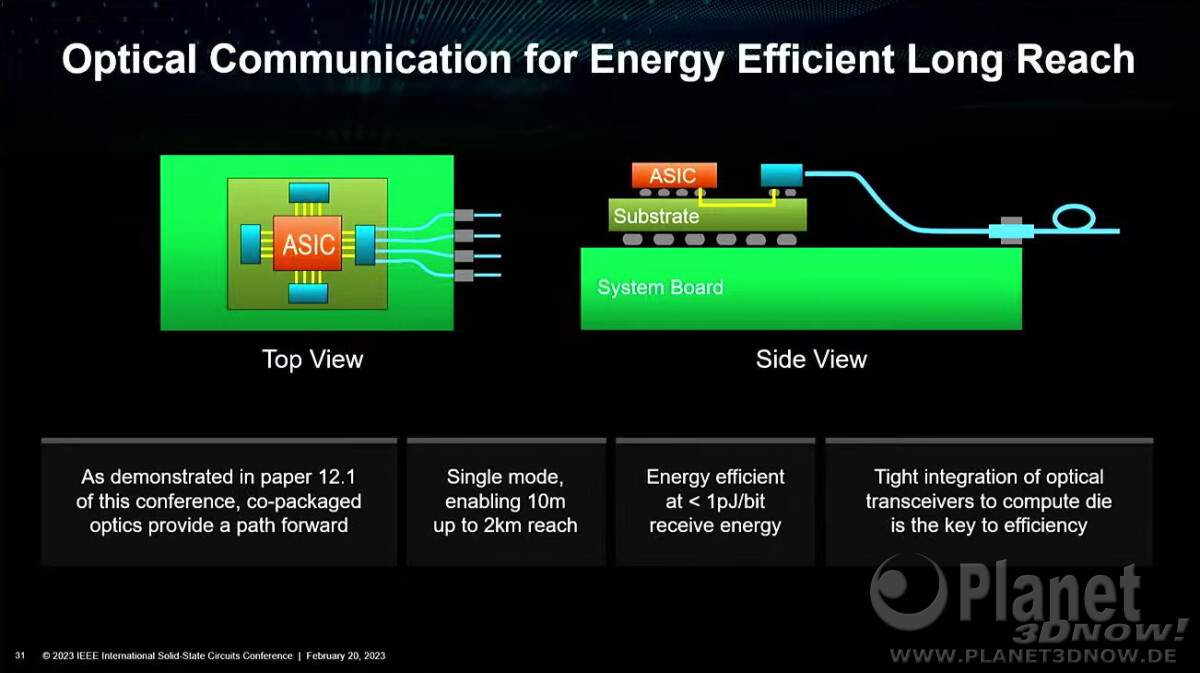
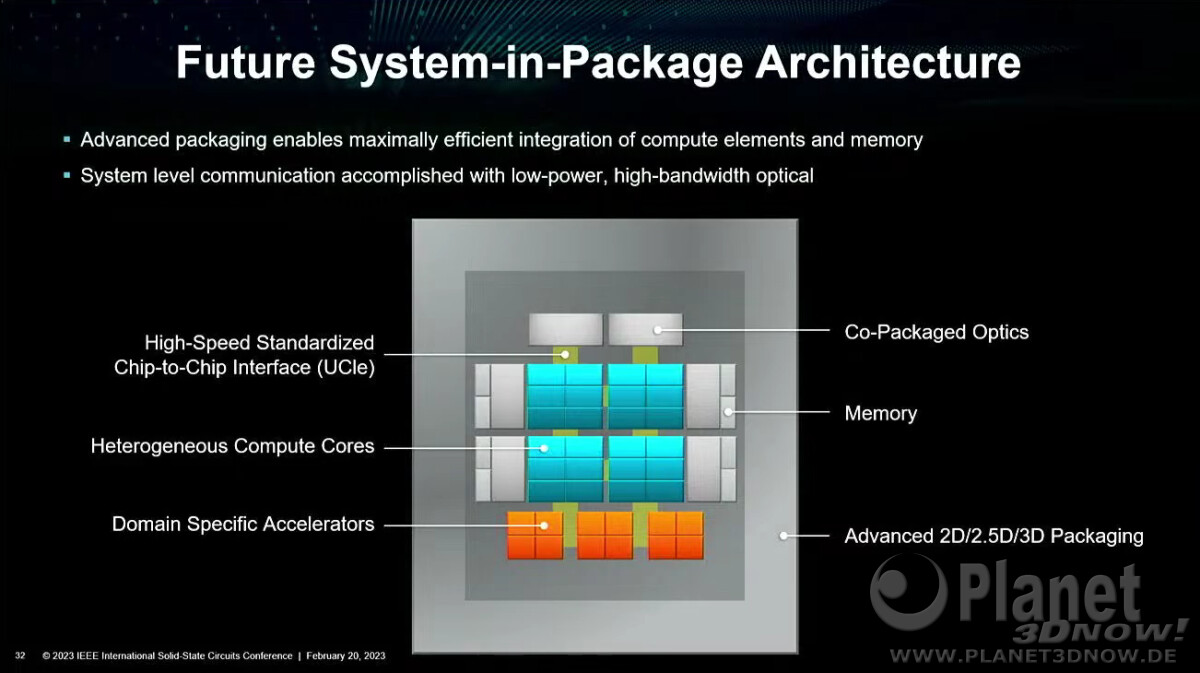
AMD envisions that the high-density server processor of the near-future will have many layers of DRAM stacked on top of logic chips. Such a method of stacking conserves both PCB and substrate real-estate, allowing chip-designers to cram even more cores and memory per socket. The company also sees a greater role of in-memory compute, where trivial simple compute and data-movement functions can be executed directly on the memory, saving round-trips to the processor. Lastly, the company talked about the possibility of an on-package optical PHY, which would simplify network infrastructure.



Source:
Planet3DNow.de
AMD envisions that the high-density server processor of the near-future will have many layers of DRAM stacked on top of logic chips. Such a method of stacking conserves both PCB and substrate real-estate, allowing chip-designers to cram even more cores and memory per socket. The company also sees a greater role of in-memory compute, where trivial simple compute and data-movement functions can be executed directly on the memory, saving round-trips to the processor. Lastly, the company talked about the possibility of an on-package optical PHY, which would simplify network infrastructure.

25 Comments on AMD Envisions Stacked DRAM on top of Compute Chiplets in the Near Future
Or this only aimed at low frequency, high core count server CPU`s?
Anyway, nice innovation.
So if AMD plans to utilize this in the future they and TSMC have to first solve the cooling and compromised clocks issue. 7800X3D loses 400-700Mhz of potential boost due to these issues. That's a significant chunk of clock speed.
The other issue is release timing. Currently it takes half a year before desktop gets X3D models. I hope in the future these will be the default on day 1 launch of a new architecture.
But stacking clearly is the future. Sockets are already enormous. Desktop sockets already approach 2000 pins and server sockets exceed 6000.
Very short read here High Bandwidth Memory - Wikipedia
I give it zero applicability though, as today CUP`s have more than "10,000 interconnects per cm2", like 10,000 time more.
www.techpowerup.com/forums/threads/nvidia-is-preparing-co-packaged-photonics-for-nvlink.276139/#post-4418550
Another thing related to optic I had mentioned was this.
"I could see a optical path potentially interconnecting them all quickly as well."
That was in regard to FPGA/CPU/GPU chiplets as well as 3Dstacking.
I spoke some about combining DIMM's with chiplets and felt it could be a good if for no other reason than for compression/decompression from those. This is neat though combining TSV and a chiplet and stacking DRAM directly on top of it. Perhaps some optical interconnects in place of TSV could work too. I think that would add another layer of complications though if you had the optical connection on substrate and then used a optical connect in place of TSV you could shave off some latency I think. I don't know maybe that's a bit of what they've already envisioned here though.
Eventually they could maybe have a I/O die in the center and 8 surrounding chiplets on a substrate and below that another substrate connected to it optically with 3D stacked cache. The way it could connect with the substrate above is each chiplet along the edge around the I/O could connect to a optical connection to the 3D stacked cache below. In fact you could even cool it a bit as well because the cache itself can be inverted and cooled on that side regardless of the optical easily enough. The only barrier I see is the cost of optics and how well it can be shrunk down in size at the same time for functionality as a interconnect.
With chiplets it could even be more feasible; one cpu core, one gpu core, one memory controller, and one or multiple HBM stacks. It would be perfect for both consoles and SFF builds.
HBM isn't universally better, it requires more exotic dense interconnects and giant memory controllers.
But, prosumer & consumer products will still need an upgradable RAM of some sort.
I mean the stacked DRAM is there for sure, but the CPU/SoC should still keep the 128/160bit IMC there for expandability. The thing will be tiered Memory Hierarchy will prioritize processes for the Stacked DRAM and/or regular RAM depending on Power/Bandwidth/Latency requirements.
Depending on how hard and costly is the stacked DRAM, AMD might have one or two options, and big OEMs might request some custom orders.
However there would nearly always be a need for DRAM connectivity as datasets are growing quicker in most areas than what is feesible with direct memory. (Currently capable of 6TB of memory per socket in the server space)
Also you are adding more power requirements to the CPU die (~30 watts) just for the HBM and would need a radically different I/O die to accomodate its integration. So you start running into packaging issues as the size of some of the server CPUs are getting into the realms of ridiculousness. (Consumer CPUs are 4x4Cm2 where as newest AMD Genoa is already pushing 7.5x7.5Cm2)
It could require some time for Windows to adapt but imagine you have 16 GB on top of your APU and then 32 GB or more of DDR5 DIMM. You play a game and the OS put the most used data into the on die memory and all the extra stuff get moved to the slower DIMM.
If you use less than 16 GB of ram, the DIMM memory could be powered down.
That makes a lot more sense than just adding HBM on an interposer, and may be simpler to manufacture (since they don't need the interposer itself). It would remove one of the big problems of using HBM and make it a lot more viable.
Strangely enough I can see the Consumer CPUs being easier to adapt to include HBM vs the Server CPUs just due to size constraints on current interposers as the extra pins on the I/O die to accomodate the HBM would be a big increase per die over current I/O dies and looking at current Genoa chips its already fairly constrained in terms of size.Actually they are on about including DRAM via 3D stacking vs HBM for the reasons I describe above. What they are trying to save/show is that by including Some/All of DRAM directly on the die of the CPU vs having it external the energy saved transferring data to and from memory is in the order of 60x
DRAM stacking is FAR easier to do due to the relative simplicity vs an HBM controller.
The memory controller is one thing, but also the location of those pin. It would probably require a special type of DRAM that AMD would either made themself or ask a third party to produce to ensure they can connect with those TSV. HBM have pin all around, you can't put TSV all around the chip right now. (Or they use an interposer between the DRAM and the Controller die but that seem costly).
I do not think the amount of silicon space is a real issue for now. They can probably package another 7 nm die or just have a bigger i/o die. We will see what they do.
They could by example have special DRAM die that have the control logic and only use the TSV between that and the i/o die or CCD. There is a lot of possibility.
Ever-increasing 'integration' has been the source of much performance uplift and reduction in latency, but all I see is less modularity.
* - Ovonic Junction compute-in-PCM looks to be a potential 'game changer' in regards to AI/MI hardware acceleration.
Tangentially related: Apparently, that's apart of the whole 'What's going on w/ Optane' situation... IP shenanigans over recognized-as potentially-game-changing tech.