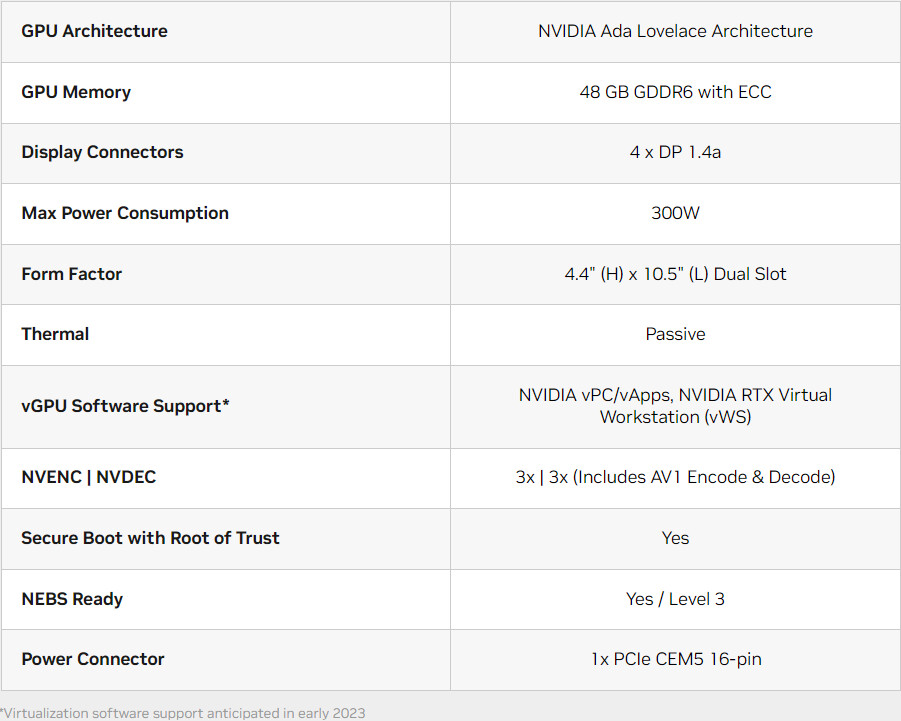
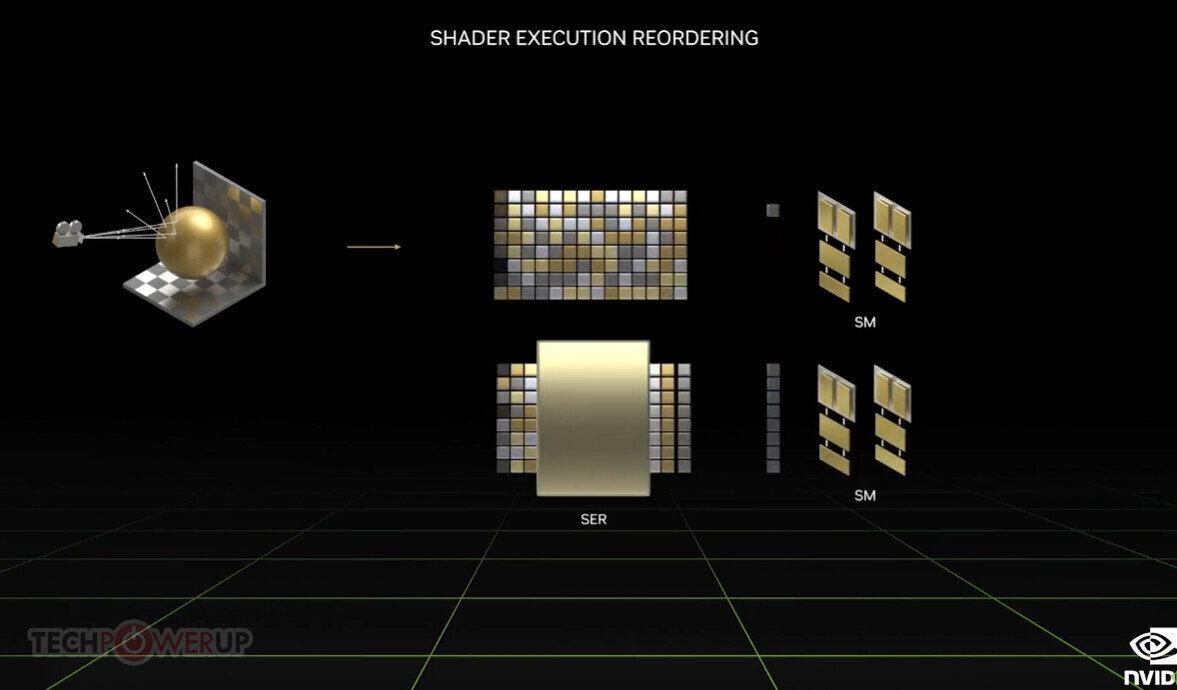
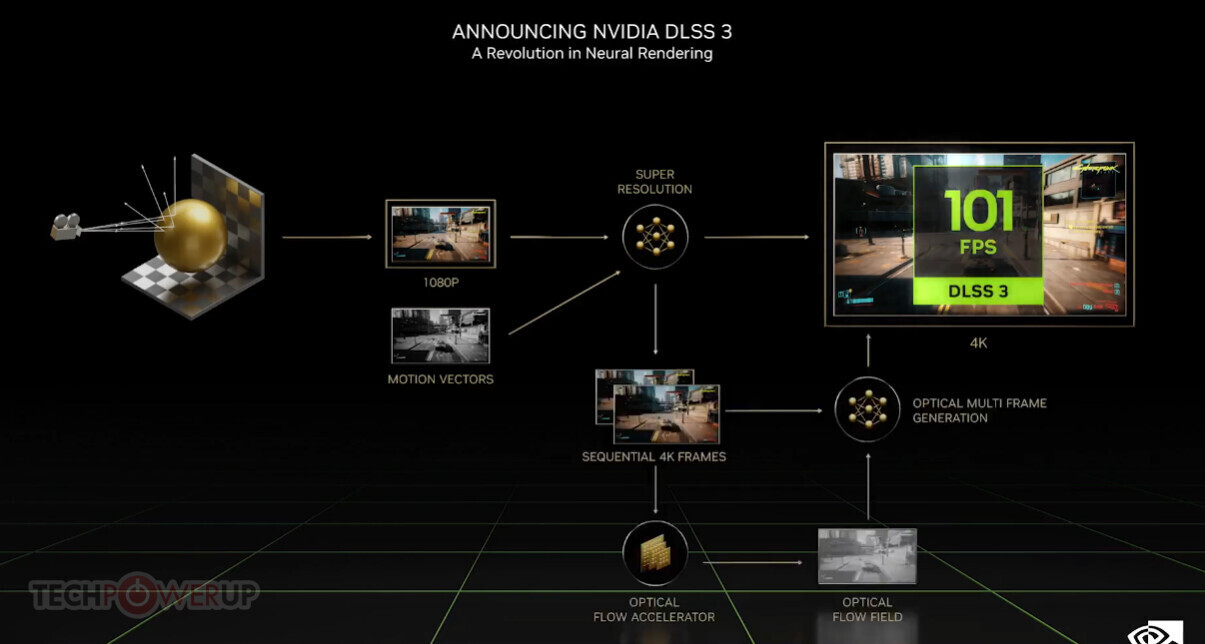
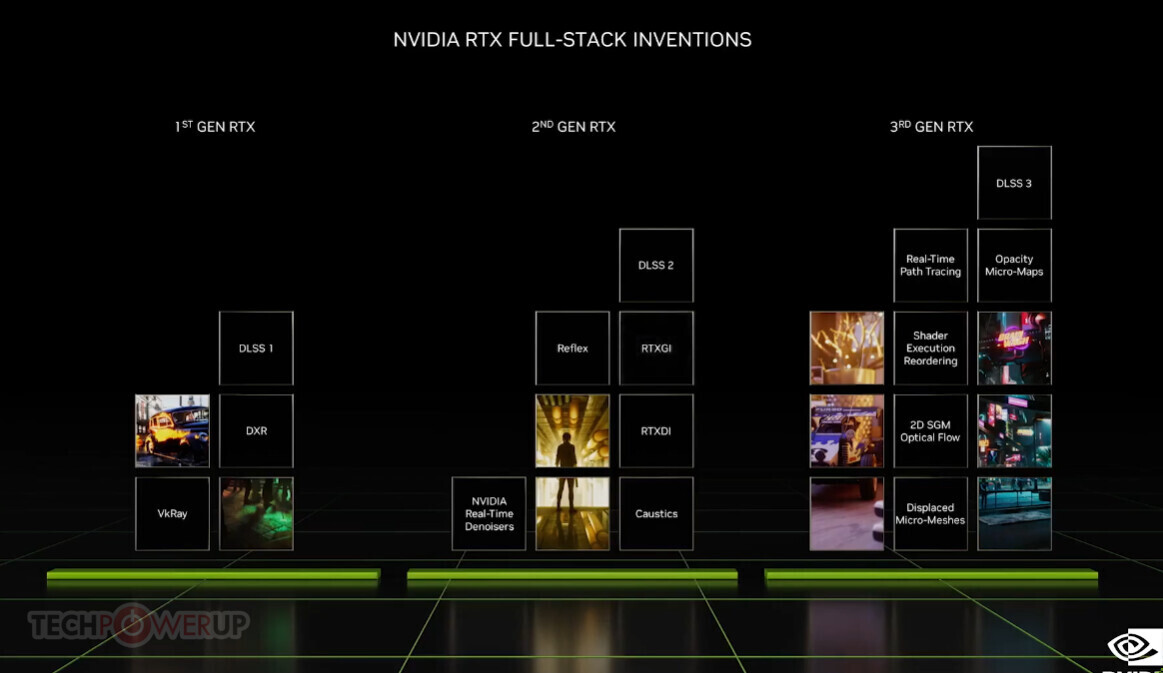
NVIDIA Announces Financial Results for Third Quarter Fiscal 2023
NVIDIA (NASDAQ: NVDA) today reported revenue for the third quarter ended October 30, 2022, of $5.93 billion, down 17% from a year ago and down 12% from the previous quarter. GAAP earnings per diluted share for the quarter were $0.27, down 72% from a year ago and up 4% from the previous quarter. Non-GAAP earnings per diluted share were $0.58, down 50% from a year ago and up 14% from the previous quarter.
"We are quickly adapting to the macro environment, correcting inventory levels and paving the way for new products," said Jensen Huang, founder and CEO of NVIDIA. "The ramp of our new platforms - Ada Lovelace RTX graphics, Hopper AI computing, BlueField and Quantum networking, Orin for autonomous vehicles and robotics, and Omniverse-is off to a great start and forms the foundation of our next phase of growth.
"We are quickly adapting to the macro environment, correcting inventory levels and paving the way for new products," said Jensen Huang, founder and CEO of NVIDIA. "The ramp of our new platforms - Ada Lovelace RTX graphics, Hopper AI computing, BlueField and Quantum networking, Orin for autonomous vehicles and robotics, and Omniverse-is off to a great start and forms the foundation of our next phase of growth.