Samsung Electronics Announces First Quarter 2023 Results, Profits Lowest in 14 Years
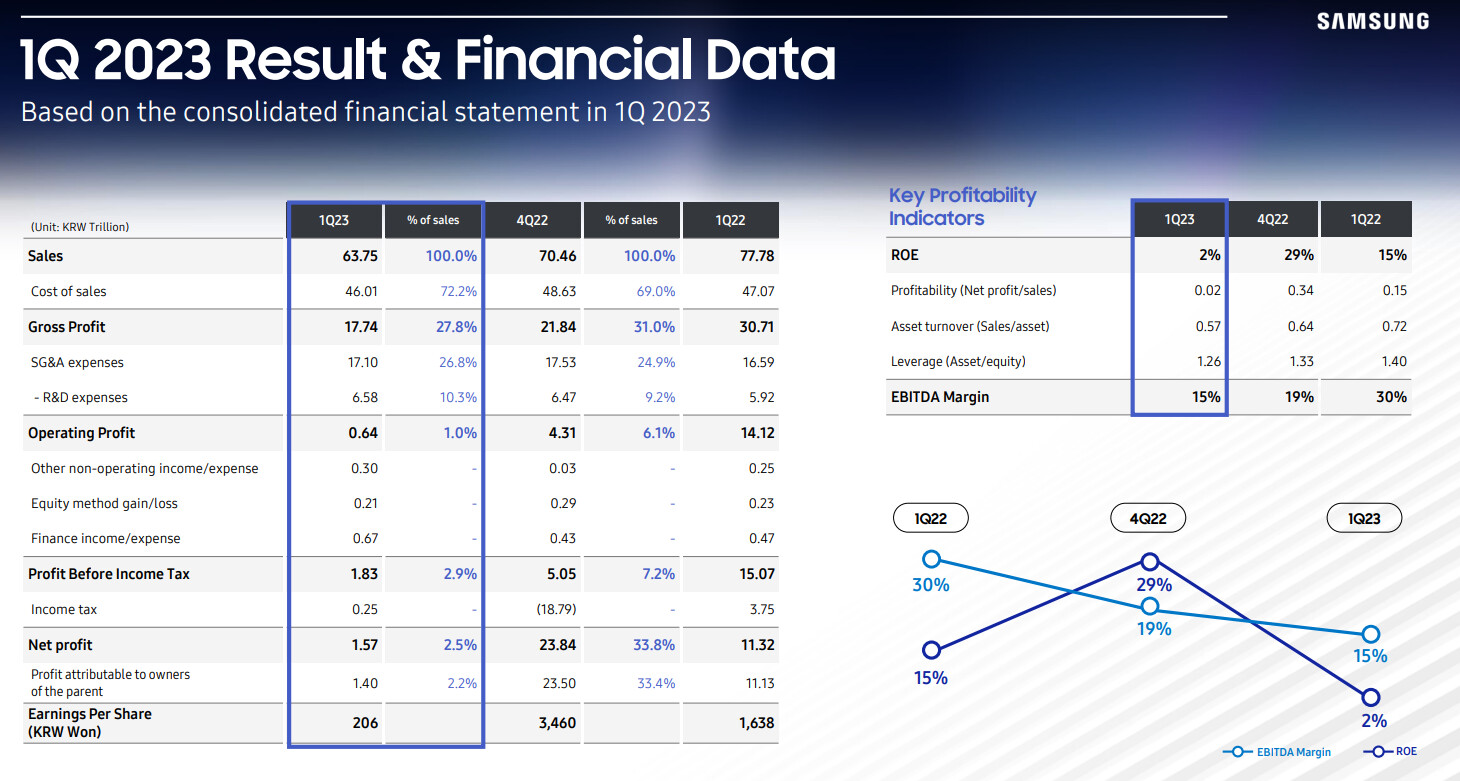
Samsung Electronics today reported financial results for the first quarter ended March 31, 2023. The Company posted KRW 63.75 trillion in consolidated revenue, a 10% decline from the previous quarter, as overall consumer spending slowed amid the uncertain global macroeconomic environment. Operating profit was KRW 0.64 trillion as the DS (Device Solutions) Division faced decreased demand, while profit in the DX (Device eXperience) Division increased.
The DS Division's profit declined from the previous quarter due to weak demand in the Memory Business, a decline in utilization rates in the Foundry Business and continued weak demand and inventory adjustments from customers. Samsung Display Corporation (SDC) saw earnings in the mobile panel business decline quarter-on-quarter amid a market contraction, while the large panel business slightly narrowed its losses. The DX Division's results improved on the back of strong sales of the premium Galaxy S23 series as well as an enhanced sales mix focusing on premium TVs.

The DS Division's profit declined from the previous quarter due to weak demand in the Memory Business, a decline in utilization rates in the Foundry Business and continued weak demand and inventory adjustments from customers. Samsung Display Corporation (SDC) saw earnings in the mobile panel business decline quarter-on-quarter amid a market contraction, while the large panel business slightly narrowed its losses. The DX Division's results improved on the back of strong sales of the premium Galaxy S23 series as well as an enhanced sales mix focusing on premium TVs.