NERSC Finalizes Contract for Perlmutter Supercomputer Powered by AMD Milan and NVIDIA Volta-Successor
The National Energy Research Scientific Computing Center (NERSC), the mission high-performance computing facility for the U.S. Department of Energy's Office of Science, has moved another step closer to making Perlmutter - its next-generation GPU-accelerated supercomputer - available to the science community in 2020.
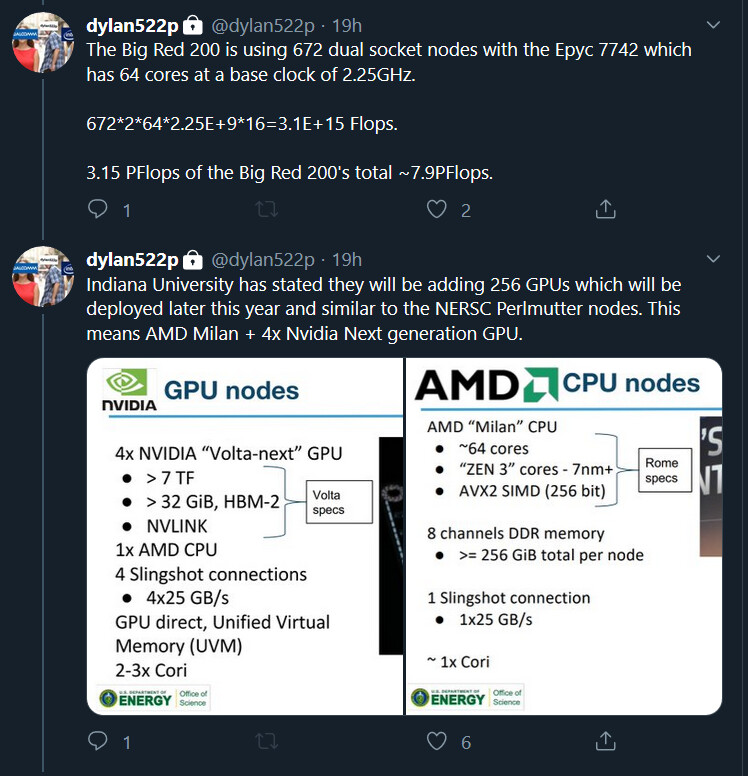
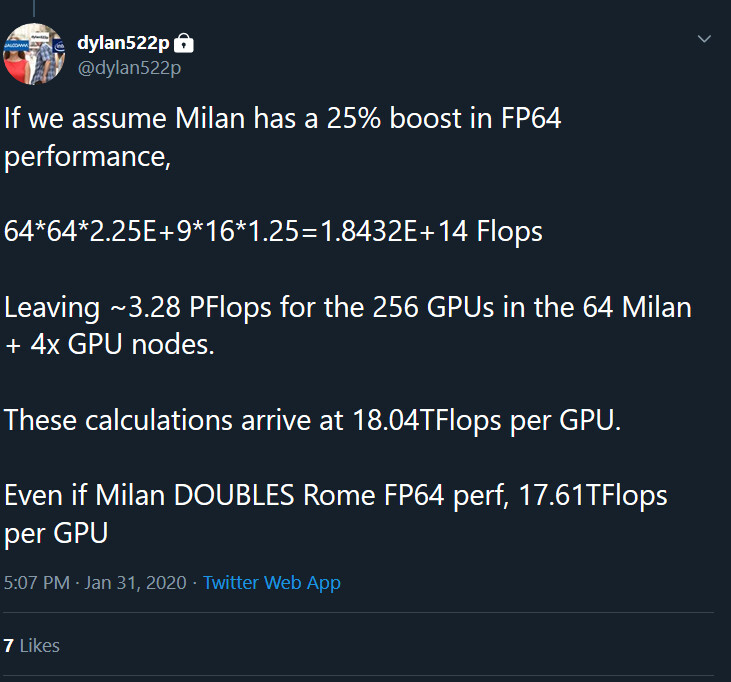
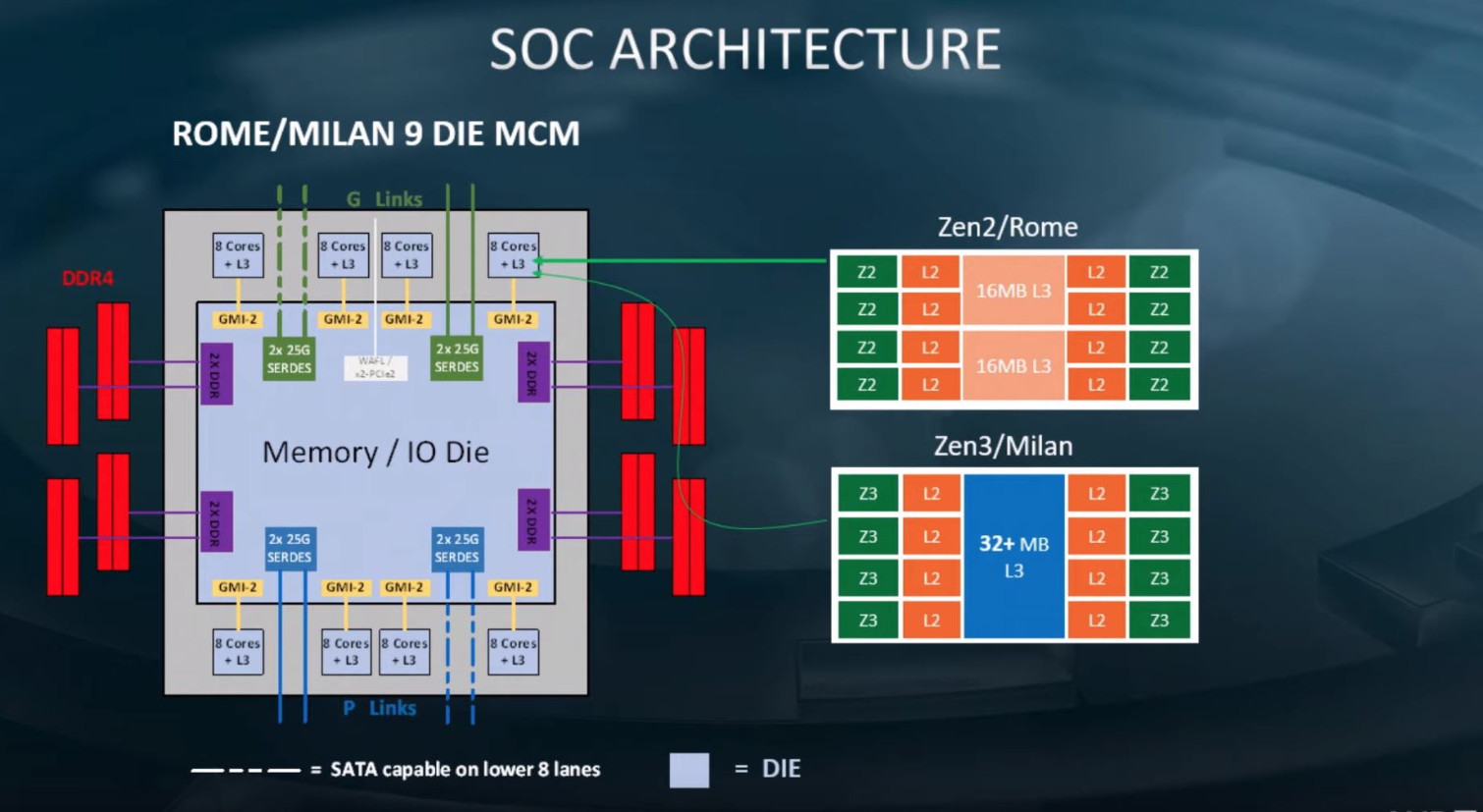
In mid-April, NERSC finalized its contract with Cray - which was acquired by Hewlett Packard Enterprise (HPE) in September 2019 - for the new system, a Cray Shasta supercomputer that will feature 24 cabinets and provide 3-4 times the capability of NERSC's current supercomputer, Cori. Perlmutter will be deployed at NERSC in two phases: the first set of 12 cabinets, featuring GPU-accelerated nodes, will arrive in late 2020; the second set, featuring CPU-only nodes, will arrive in mid-2021. A 35-petabyte all-flash Lustre-based file system using HPE's ClusterStor E1000 hardware will also be deployed in late 2020.
In mid-April, NERSC finalized its contract with Cray - which was acquired by Hewlett Packard Enterprise (HPE) in September 2019 - for the new system, a Cray Shasta supercomputer that will feature 24 cabinets and provide 3-4 times the capability of NERSC's current supercomputer, Cori. Perlmutter will be deployed at NERSC in two phases: the first set of 12 cabinets, featuring GPU-accelerated nodes, will arrive in late 2020; the second set, featuring CPU-only nodes, will arrive in mid-2021. A 35-petabyte all-flash Lustre-based file system using HPE's ClusterStor E1000 hardware will also be deployed in late 2020.