Monday, October 7th 2019

AMD Zen 3 Could Bid the CCX Farewell, Feature Updated SMT
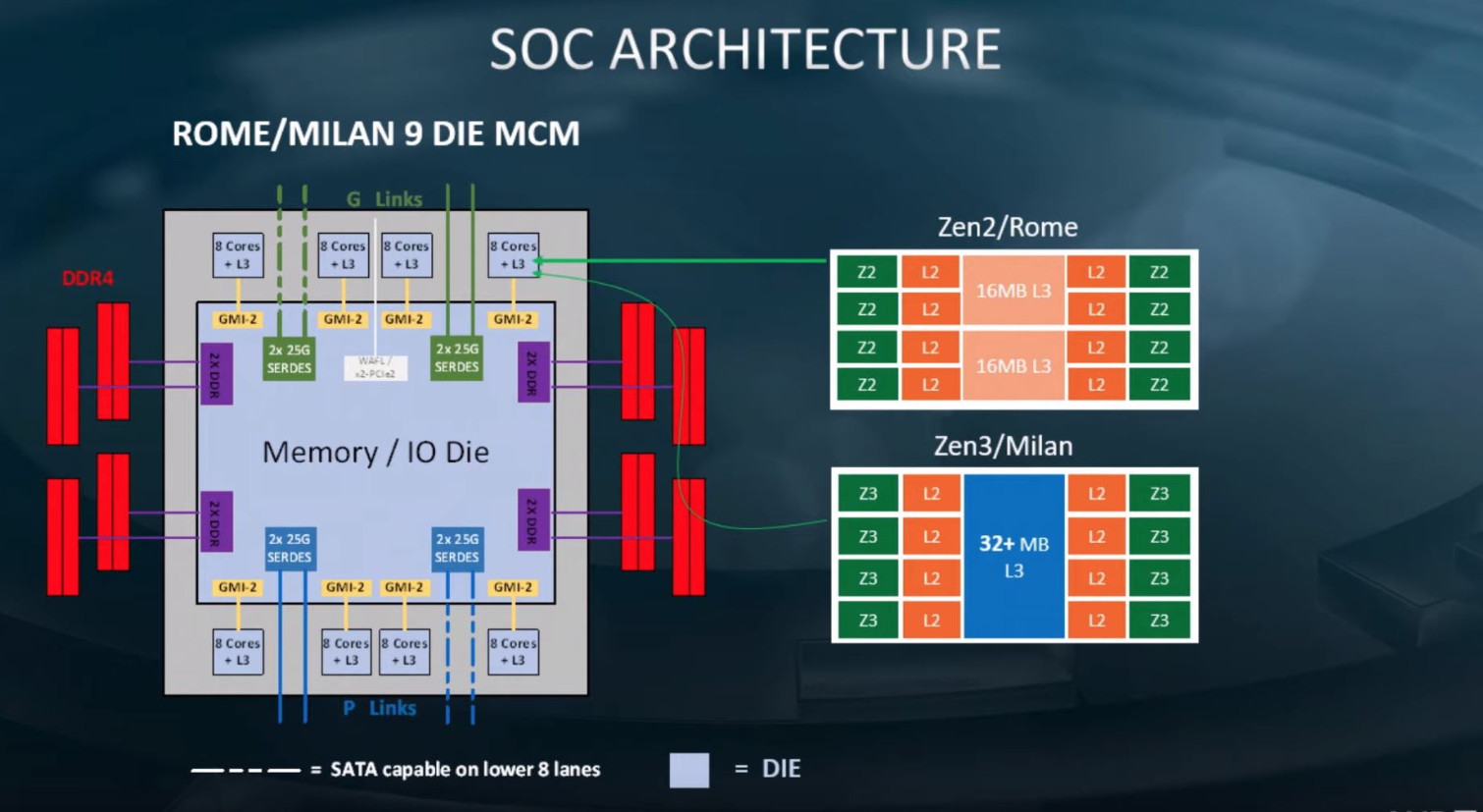
With its next-generation "Zen 3" CPU microarchitecture designed for the 7 nm EUV silicon fabrication process, AMD could bid the "Zen" compute complex or CCX farewell, heralding chiplets with monolithic last-level caches (L3 caches) that are shared across all cores on the chiplet. AMD embraced a quad-core compute complex approach to building multi-core processors with "Zen." At the time, the 8-core "Zeppelin" die featured two CCX with four cores, each. With "Zen 2," AMD reduced the CPU chiplet to only containing CPU cores, L3 cache, and an Infinity Fabric interface, talking to an I/O controller die elsewhere on the processor package. This reduces the economic or technical utility in retaining the CCX topology, which limits the amount of L3 cache individual cores can access.
This and more juicy details about "Zen 3" were put out by a leaked (later deleted) technical presentation by company CTO Mark Papermaster. On the EPYC side of things, AMD's design efforts will be spearheaded by the "Milan" multi-chip module, featuring up to 64 cores spread across eight 8-core chiplets. Papermaster talked about how the individual chiplets will feature "unified" 32 MB of last-level cache, which means a deprecation of the CCX topology. He also detailed an updated SMT implementation that doubles the number of logical processors per physical core. The I/O interface of "Milan" will retain PCI-Express gen 4.0 and eight-channel DDR4 memory interface.
 "Milan" is expected to see a Q3-2020 debut with EPYC. Around the same time, AMD tapes out "Genoa," the company's next-generation processor that heralds an all new enterprise socket dubbed SP5. A new socket gives AMD the opportunity to update and expand I/O such as increasing the memory interface width, add even more PCIe lanes, etc. The SP5 platform along with "Genoa" could see the light by 2021-22.
"Milan" is expected to see a Q3-2020 debut with EPYC. Around the same time, AMD tapes out "Genoa," the company's next-generation processor that heralds an all new enterprise socket dubbed SP5. A new socket gives AMD the opportunity to update and expand I/O such as increasing the memory interface width, add even more PCIe lanes, etc. The SP5 platform along with "Genoa" could see the light by 2021-22.
Source:
Tom's Hardware
This and more juicy details about "Zen 3" were put out by a leaked (later deleted) technical presentation by company CTO Mark Papermaster. On the EPYC side of things, AMD's design efforts will be spearheaded by the "Milan" multi-chip module, featuring up to 64 cores spread across eight 8-core chiplets. Papermaster talked about how the individual chiplets will feature "unified" 32 MB of last-level cache, which means a deprecation of the CCX topology. He also detailed an updated SMT implementation that doubles the number of logical processors per physical core. The I/O interface of "Milan" will retain PCI-Express gen 4.0 and eight-channel DDR4 memory interface.

26 Comments on AMD Zen 3 Could Bid the CCX Farewell, Feature Updated SMT
I wonder if all of this is hoax just to keep AMD in the spotlight, not by AMD of course.
3to get cheap enough so that they can make a killer APU, the same could be used for regular L4 as well :pimp:So that seems promising for zen 3 or 7 nm+ when it comes to games.
Maybe the internal testing showed that it can be done with achieved or better than projected yeld's.
This , still sleepy degree-less in computer engineer armchair general.
Exciting times :)
I dont know if ryzen has the same problem though, I assume AMD is still using larger, slower caches to be able to ship 32MB so cheaply.
my version lol
i like doing these custom designs for fun