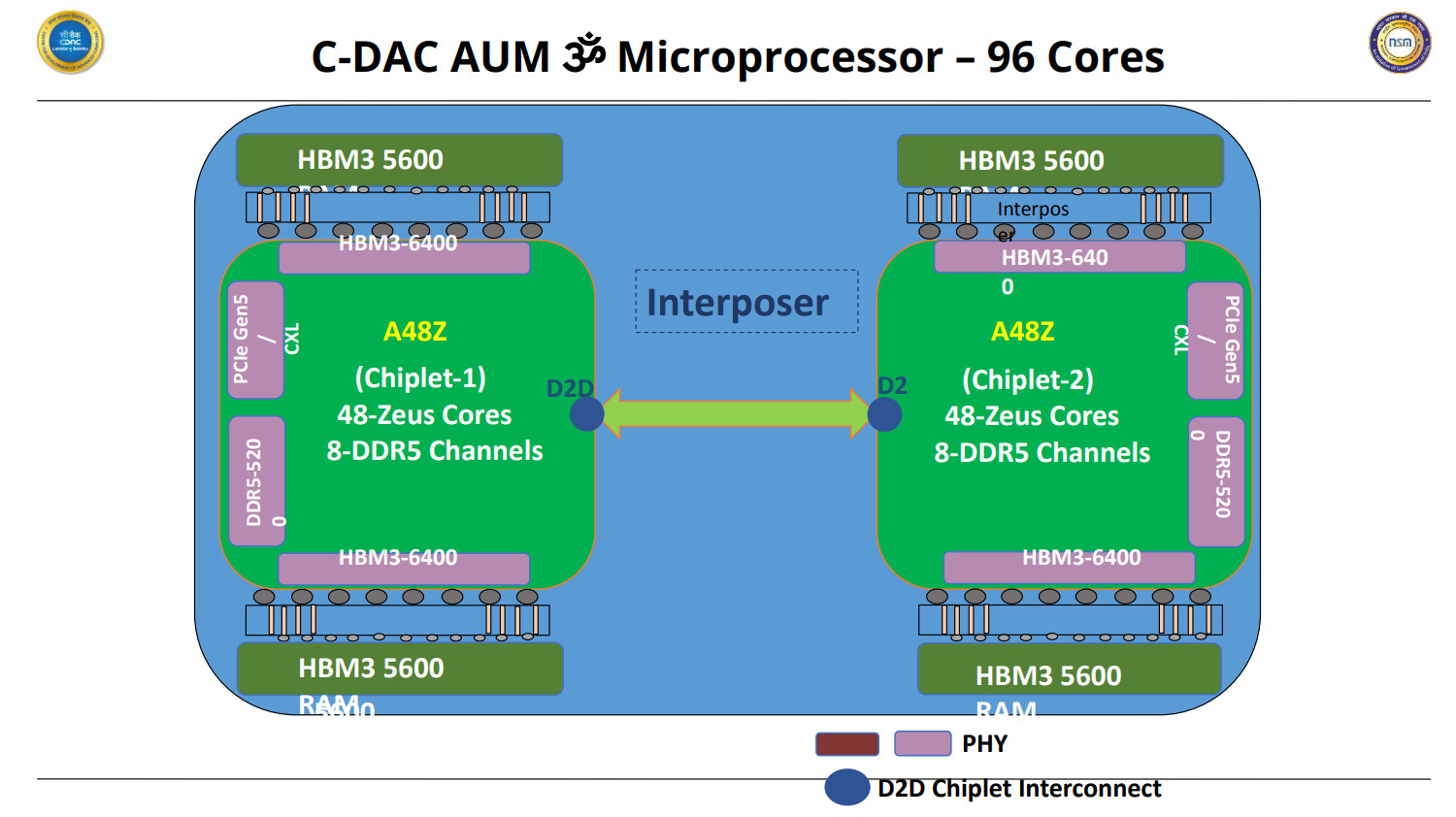
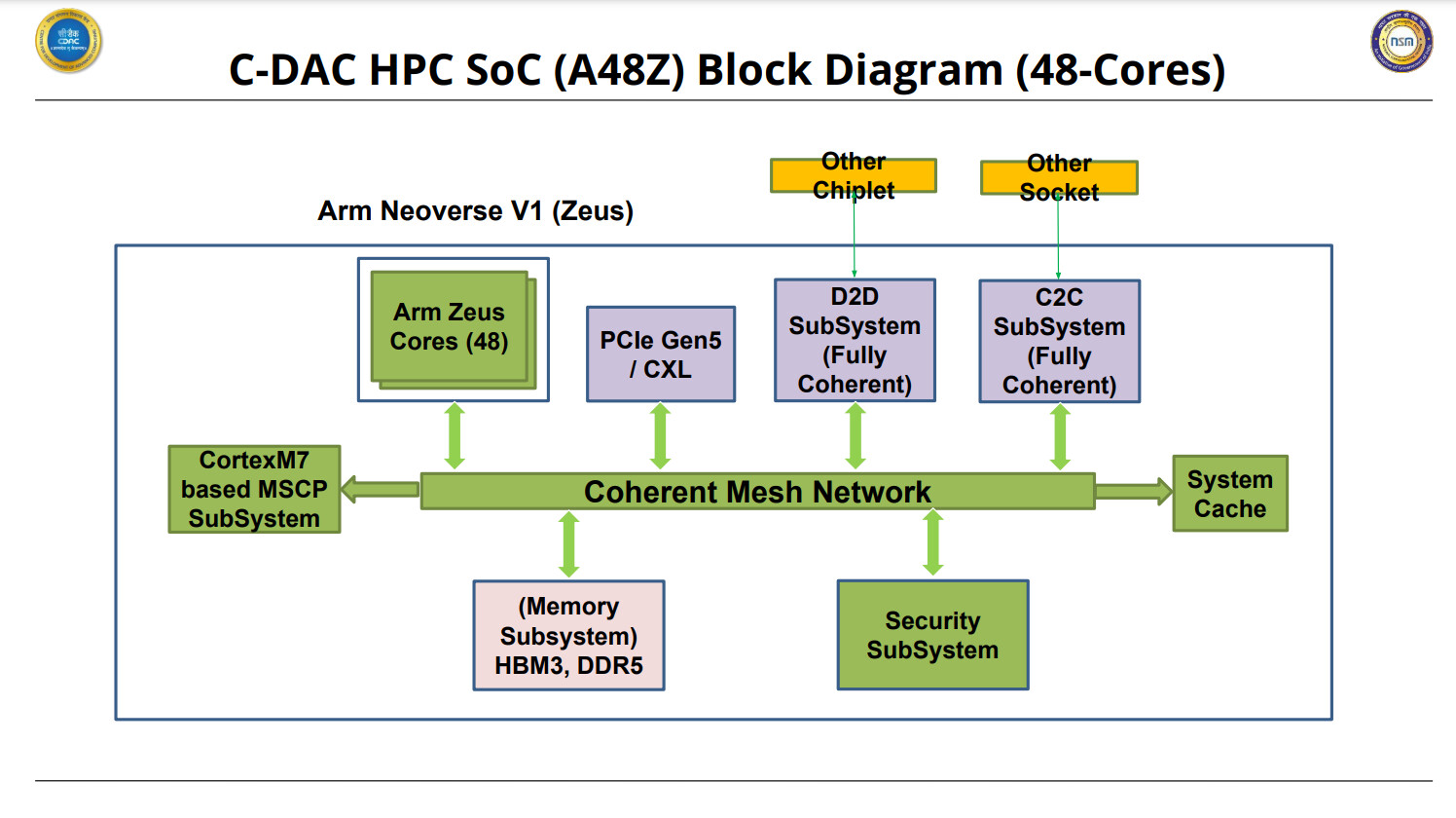
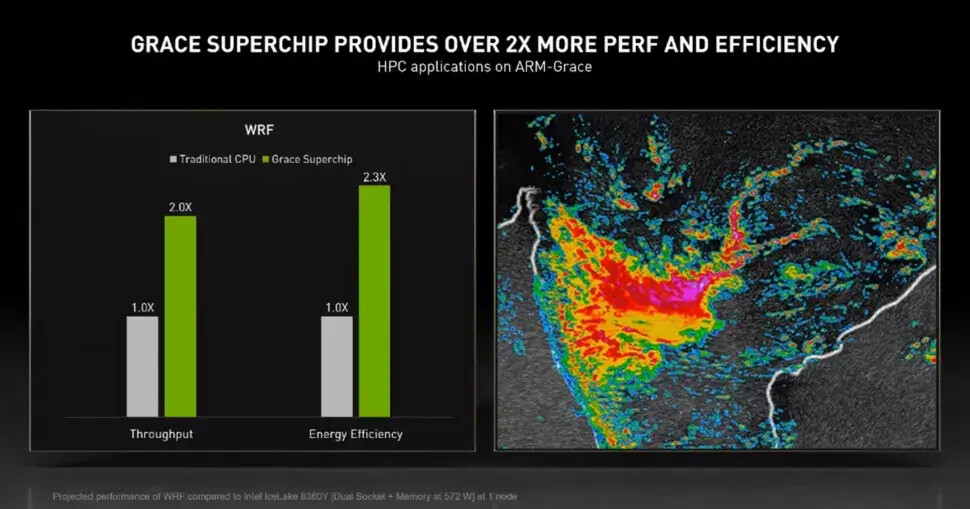
Xsight Labs Announced Availability of Its Arm-Based E1-SoC for Cloud and Edge AI Data Centers
Xsight Labs, a leading fabless semiconductor company providing end-to-end connectivity for next-generation hyperscale, edge and AI data center networks, today announced availability of its Arm -based E1-SoC for cloud and edge AI data centers. The E-Series is the only product of its kind to provide full control plane and data path programmability and is the industry's highest performance software-defined DPU (Data Processing Unit). Xsight Labs is taking orders now for its E1-SoC and the E1-Server, the first-to-market 800G DPU.
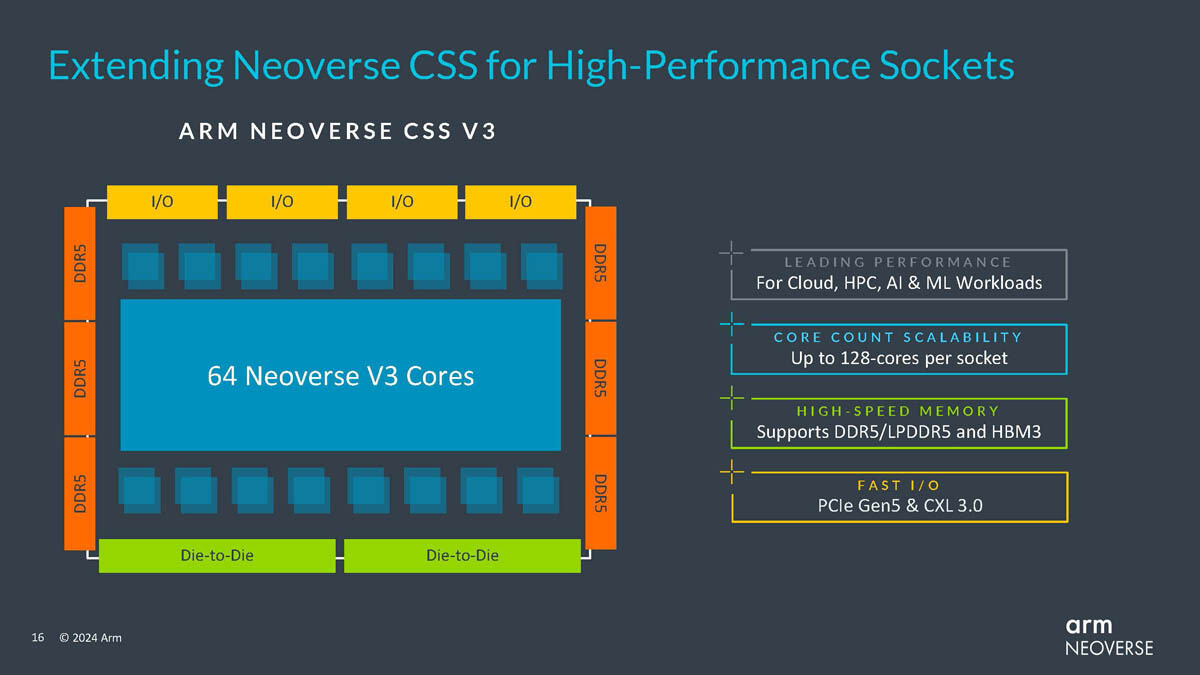
E1 is the first SoC in the E-Series, Xsight Labs' SDN (Software Defined Network) Infrastructure Processor product family of fully programmable network accelerators. Built on TSMC's advanced 5 nm process technology, the E1-SoC will begin shipping to customers and ecosystem partners.

E1 is the first SoC in the E-Series, Xsight Labs' SDN (Software Defined Network) Infrastructure Processor product family of fully programmable network accelerators. Built on TSMC's advanced 5 nm process technology, the E1-SoC will begin shipping to customers and ecosystem partners.