Monday, April 11th 2022

NVIDIA Claims Grace CPU Superchip is 2X Faster Than Intel Ice Lake
When NVIDIA announced its Grace CPU Superchip, the company officially showed its efforts of creating an HPC-oriented processor to compete with Intel and AMD. The Grace CPU Superchip combines two Grace CPU modules that use the NVLink-C2C technology to deliver 144 Arm v9 cores and 1 TB/s of memory bandwidth. Each core is Arm Neoverse N2 Perseus design, configured to achieve the highest throughput and bandwidth. As far as performance is concerned, the only detail NVIDIA provides on its website is the estimated SPECrate 2017_int_base score of over 740. Thanks to the colleges over at Tom's Hardware, we have another performance figure to look at.
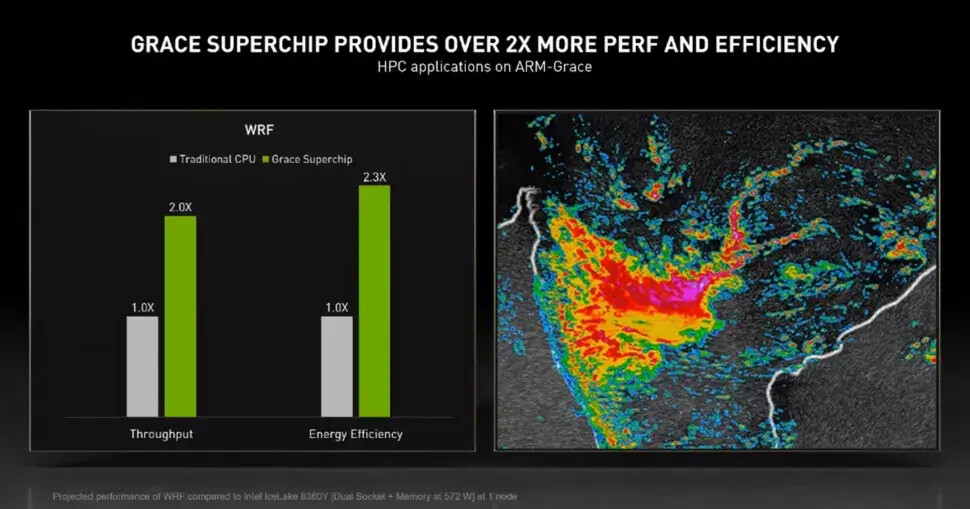
NVIDIA has made a slide about comparison with Intel's Ice Lake server processors. One Grace CPU Superchip was compared to two Xeon Platinum 8360Y Ice Lake CPUs configured in a dual-socket server node. The Grace CPU Superchip outperformed the Ice Lake configuration by two times and provided 2.3 times the efficiency in WRF simulation. This HPC application is CPU-bound, allowing the new Grace CPU to show off. This is all thanks to the Arm v9 Neoverse N2 cores pairing efficiently with outstanding performance. NVIDIA made a graph showcasing all HPC applications running on Arm today, with many more to come, which you can see below. Remember that NVIDIA provides this information, so we have to wait for the 2023 launch to see it in action.


Source:
Tom's Hardware
NVIDIA has made a slide about comparison with Intel's Ice Lake server processors. One Grace CPU Superchip was compared to two Xeon Platinum 8360Y Ice Lake CPUs configured in a dual-socket server node. The Grace CPU Superchip outperformed the Ice Lake configuration by two times and provided 2.3 times the efficiency in WRF simulation. This HPC application is CPU-bound, allowing the new Grace CPU to show off. This is all thanks to the Arm v9 Neoverse N2 cores pairing efficiently with outstanding performance. NVIDIA made a graph showcasing all HPC applications running on Arm today, with many more to come, which you can see below. Remember that NVIDIA provides this information, so we have to wait for the 2023 launch to see it in action.


30 Comments on NVIDIA Claims Grace CPU Superchip is 2X Faster Than Intel Ice Lake
For CPU that have the same goal, the uArch have minimal impact and it's really the design of the CPU that matter. People have compared High performance CPU efficiency with Cellphone CPU and declared that Arm was more efficient. But when Arm design look at high performance, they already start to be way less power efficient. The M1 by example had to run on a more advanced node than Intel and AMD to stay barely ahead. We will see how comparable Architecture on the same nodes or similar nodes (raptor lake, Zen4) will do against M1.
Like Jim Keller said, The uArch do not really matter a lot these days as CPU are so complex. Once the instruction get decoded, it's a flat field for everyone and arm have no specific advantage after that. The overhead to decode x86-64 vs arm is not significant for a complex CPU like what we have today.
Also Nvidia is joining the trend of comparing old thing with things not even released yet. If That get release in a year from now, icelake xeons will be 2 years old at that point. So i hope that it will be better. (and it's convenient that they don't compare it against EPYC, the actual performance leader right now.)
Oh yeah, they haven't announced shit
Best-case, Sapphire will arrive at the end of the year (mass-availability halfway through 2023!)
those guys/gals in marketing get paychecks to earn and simulators to play with. :p
They compare unreleased and not even taped out chip with things that are already available on the market for quite some time.
Company that does that (Not only Nvidia, Intel and AMD did too in the past) are generally company that know they will fall behind and try to get some hype before competitors get released. Company that get huge lead try to get a huge launch day that have impact to get as much as possible mind share.
And that do not resolve the main issue, they are comparing with a year old second place CPU, the lead is currently taken by Milan and Milan-X and at that time, we will have Genoa (Zen-4) available.The thing is there are very few real RISC cpu. If you look at how large Arm instruction set grow, it's hard to declare that still a reduced instruction set.
Probably the slight advantages Arm could have for simplicity over x86-64 is the fixed instruction length versus variable instruction length of x86. This allow a bit simpler front end instruction decoding. But again, this have a marginal impact on the overall CPU these days because CPU are huge, massive and complex. If things were much simpler, like in the 90s and early 2000, that could actually made a significant difference. Things were much simpler.
Until nvidia produces working chips that can be bought and verified by third parties I'mma call this a big fat LIE.
Intel vs AMD vs Via/Centaur CPUs shows just how much you can vary CPU-performance and CPU-power-usage.
Similarly: ARM N1-core vs Apple M1 vs Fujitsu a64fx are all different CPU-performance vs CPU-power-usage. Fujitsu A64fx is a freaking GPU-like design of all things (heavily focused on 512-bit SVE instructions) and is the #1 beast in the world for supercomputers currently, but has strict RAM-limitations because its stuck on HBM2 RAM (so ~64GBs of RAM per chip), while other DDR4 or LPDDR5 CPU chips have access to more RAM.
-----
The 10% that matters comes down to memory-model details that almost all programmers are ignorant of. If you know about load-acquire and store-release, maybe you'll like the ARM-instruction set over the x86 instruction set. But this is extremely, extremely niche and irrelevant in the vast, vast, vast majority of programs. In fact, x86's slightly better designed AES/Crypto functions are probably more important in practice. "AESENC" single-instruction to encrypt on x86, while on ARM you gotta "AESE + AESMC" (2-instructions per AES-loop).
-------
ARM N1 / N2 / V1 even don't seem to be as good as current-generation AMD-EPYC or Intel designs IMO. Apple's M1 is the only outstanding design, but even then the M1 has a lot of tradeoffs (absolutely HUGE core, bigger than anyone else's. Apple's M1 is so physically huge it won't scale to higher core counts very easily)
Well... okay. Fujitsu A64fx is an incredible ARM-based design for supercomputers. But almost nobody wants an ARM-chip grafted onto HBM2e RAM. That's just too niche.
I guess this is why Intel wanted or is still in design stage of a brand new x86 architecture which will delete all those legacy modes and make the transistors work on modern apps.
The great thing about RISC is that it's very efficient when the compiled code is properly optimized. When it's not, instructions not properly coded/optimized have to be completed in software instead of hardware, which is MUCH slower. CISC is not as efficient, but most compiled code can run on hardware instead of in software. It's FAR more complicated than this brief explanation, but you get the general idea.
Which ISA standard you choose will depend greatly on what you want your code to do and how fast.That would not be correct. Yes, RISC SOCs are more complex than they were in the past, but so too is CISC. RISC CPU hardware instructions have about doubled in last 20 years. CISC(X86/X64) has increased at least quadruple in the same amount of time.
So while ARM designs and instructions have become more complex, they are still very much "reduced" in comparison to X86/X64 and even PowerPC.
EDIT: There's a reason why its called "ARMv8" (as well as ARMv8.1, ARMv8.2, ARMv8.3...), because there was ARMv1, ARMv2, ARMv3... ARMv7. And we have to also ignore all the death paths, like Jazelle instructions (aka: Java-instructions for ARM), Thumb-v1, Thumb-v2, etc. etc.
Even the SSE / AVX mistake is being repeated by ARM yet again, because ARM made NEON-instructions (128-bit) when Intel/AMD were working on 256-bit AVX. These NEON instructions are now obsolete as ARM is working on SVE.
Do you even work with ARM instructions? ARM is a CISC processor at this point. Do you know what the ARM "fjcvtzs" instruction does? Do you know the history of this?
--------
RISC vs CISC has played out. CISC won. All RISC-instruction sets are glorified CISC processors with macro-op fusion (ex: aese + aesmc instructions in ARM, merging two instructions to make a macro-op), SIMD-instructions (NEON and its various incarnations), multiple memory models (lol, ARMv7 started with load-consume / store-release, turned out to be an awful memory model so ARMv8 had to introduce a whole slew of new load/store commands called load-acquire / store-release), etc. etc.
CPUs are very hard. They have to constantly change their instruction sets. ARM, x86, etc. etc. The only CPUs that don't change are dead ones (ex: MIPS, may it rest in peace). CPUs are all turd piled up on more turd being used as lipsticks on very ugly pigs. ARM tried to be RISC but has effectively turned into a giant mess of a core, much like x86 has. Everything turns into CISC as time goes on, that's just the nature of this industry.
--------
EDIT: Instruction sets become complicated over time because its really easy to decode instructions compared to everything else the CPU does. CPUs today are super-scalar (multiple-instructions simultaneously executing per clock cycle, as much as 8x instructions per clock on Apple's M1 chip), hyperthreaded (each core works with 2, 4, 8 threads at a time), pipelined (each instruction gets split up into 30+ steps for other bits of the processor to handle), out-of-order (literally executing "later" instructions before "earlier" instructions), cache-coherent snooping (spies on other CPU cores to see their memory reads/writes to automatically adjust their understanding of memory) complicated beasts.
This whole RISC vs CISC thing is a question of how complicated of a decoder you wanna make. But decoders aren't even that big on today's CPUs, because everything else the CPU does is far more complicated, and costly in terms of area/power/RAM/price/silicon. I think I can safely declare RISC vs CISC to be a dead discussion. Today's debate is really CPU vs GPU (or really: single-threaded with a bit of SIMD like x86/ARM/POWER... vs SIMD-primarily like Turing/RDNA2)
Qualcomm Snapdragon 855 - Benchmark, Test and specs (cpu-monkey.com)
Qualcomm Snapdragon 855 SoC - Benchmarks and Specs - NotebookCheck.net Tech
Benchmarks are surprisingly inconsistent these days. There's a lot of conflicting reports and conflicting information. My opinion of stock-ARM is pretty low actually. Neoverse looks like they're decent cores, but they're still a bit out of date. ARM from Apple / Fujitsu are world-class processors though.
I'm all for good competition. But there's a reason why the computer industry has continued to use Intel Xeon / AMD EPYC in power-constrained datacenter workloads. Because in practice, AMD EPYC is the most power-efficient system in practice (followed by Intel Xeons as the #2. Very close competition, but AMD has the lead this year).
But in any case, the process difference (12nm vs 7nm) is pretty big, that's a 50% cut in power IIRC, so that's a valuable point to bring up. Manufacturing differences is the big reason why we techies are talking about nanometers so much...
-------
IIRC, there was something about cell-phones disabling their power-limiters when they detected Geekbench (!!!!), so there's also the lack of apples-to-apples when it comes to benchmarking. Don't trust the specs, something can be a 5W CPU but will disable its power-limiter to draw 10 or 15 watts during a benchmark temporarily. This leads to grossly different performance characteristics when different people run different benchmarks on their own systems.
The only way to get the truth is to hook up wires and measure the power-usage of the CPU (or system) during a benchmark, like what's done here on TPU (or also on Anandtech and other online testing sites). I don't really trust random benchmark numbers on the internet anymore.
Power10 120C = 1700 / 2170 (base / peak)
EPYC 7773X 128C = 864 / 928
Xeon 8380H 224C = 1570 / 1620
Ampere Altra 160C = 596