Arteris Accelerates AI-Driven Silicon Innovation with Expanded Multi-Die Solution
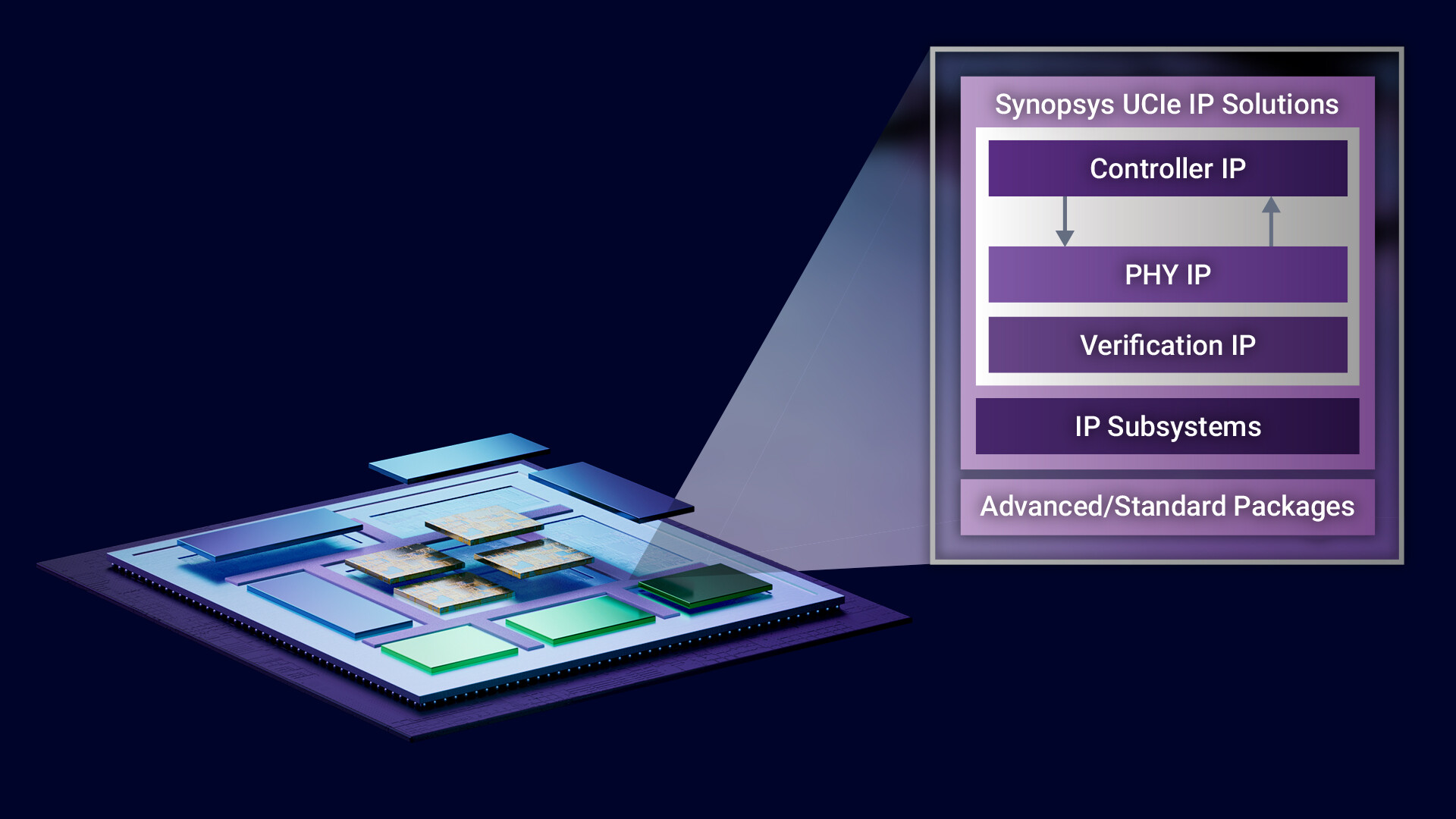
In a market reshaped by the compute demands of AI, Arteris, Inc. (Nasdaq: AIP), a leading provider of system IP for accelerating semiconductor creation, today announced an expansion of its multi-die solution, delivering a foundational technology for rapid chiplet-based innovation. "In the chiplet era, the need for computational power increasingly exceeds what is available by traditional monolithic die designs," said K. Charles Janac, president and CEO of Arteris. "Arteris is leading the transition into the chiplet era with standards-based, automated and silicon-proven solutions that enable seamless integration across IP cores, chiplets, and SoCs."
Moore's Law, predicting the doubling of transistor count on a chip every two years, is slowing down. As the semiconductor industry accelerates efforts to increase performance and efficiency, especially driven by AI workloads, architectural innovation through multi-die systems has become critical. Arteris' expanded multi-die solution addresses this shift with a suite of enhanced technologies that are purpose-built for scalable and faster time-to-silicon, high-performance computing, and automotive-grade mission-critical designs.


Moore's Law, predicting the doubling of transistor count on a chip every two years, is slowing down. As the semiconductor industry accelerates efforts to increase performance and efficiency, especially driven by AI workloads, architectural innovation through multi-die systems has become critical. Arteris' expanded multi-die solution addresses this shift with a suite of enhanced technologies that are purpose-built for scalable and faster time-to-silicon, high-performance computing, and automotive-grade mission-critical designs.