 18
18
Palit GeForce RTX 2080 Super Jetstream 8 GB Review
Packaging & Contents »Architecture
On the 14th of September, we published a comprehensive NVIDIA "Turing" architecture deep-dive article including coverage of its three new silicon implementations and the new RTX Technology. Be sure to catch that article for more technical details.
The "Turing" architecture caught many of us by surprise because it wasn't visible on GPU architecture roadmaps until a few quarters ago. NVIDIA took this roadmap detour over carving out client-segment variants of "Volta" as it realized it had achieved sufficient compute power to bring its ambitious RTX Technology to the client segment. NVIDIA RTX is an all-encompassing real-time ray-tracing model for consumer graphics that seeks to bring a semblance of real-time ray tracing to 3D games.
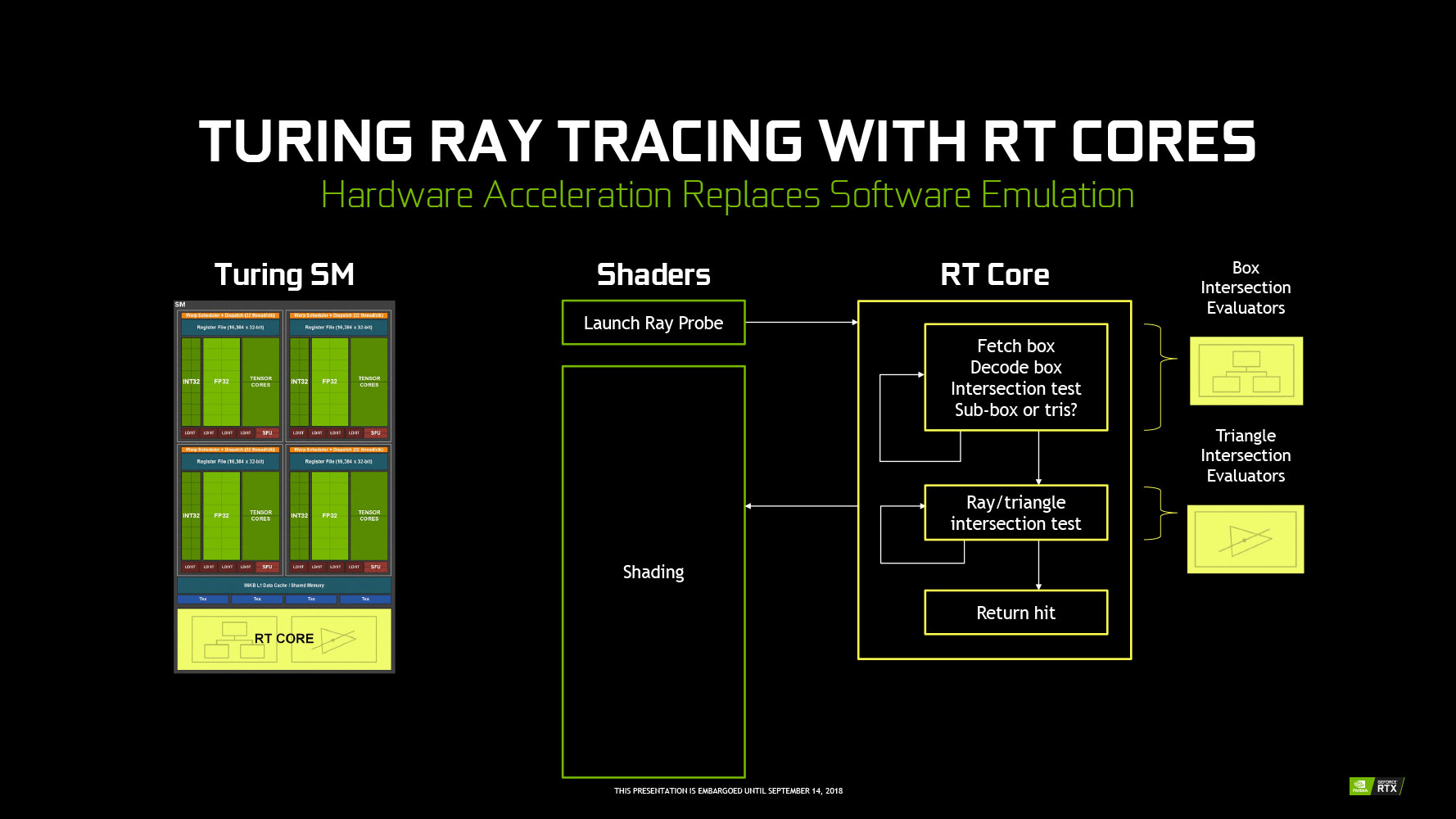

To enable RTX, NVIDIA has developed an all new hardware component that sits next to CUDA cores, called the RT core. An RT core is a fixed-function hardware that does what the spiritual ancestor of RTX, NVIDIA OptiX, did over CUDA cores. You input the mathematical representation of a ray, and it will transverse the scene to calculate the point of intersection with any triangle in the scene. This is a computationally heavy task that would have otherwise bogged down the CUDA cores.
The other major introduction is the Tensor Core, which made its debut with the "Volta" architecture. These too are specialized components tasked with 3x3x3 matrix multiplication, which speed up AI deep-learning neural net building and training. Its relevance to gaming is limited at this time, but NVIDIA is introducing a few AI-accelerated image-quality enhancements that could leverage Tensor operations.
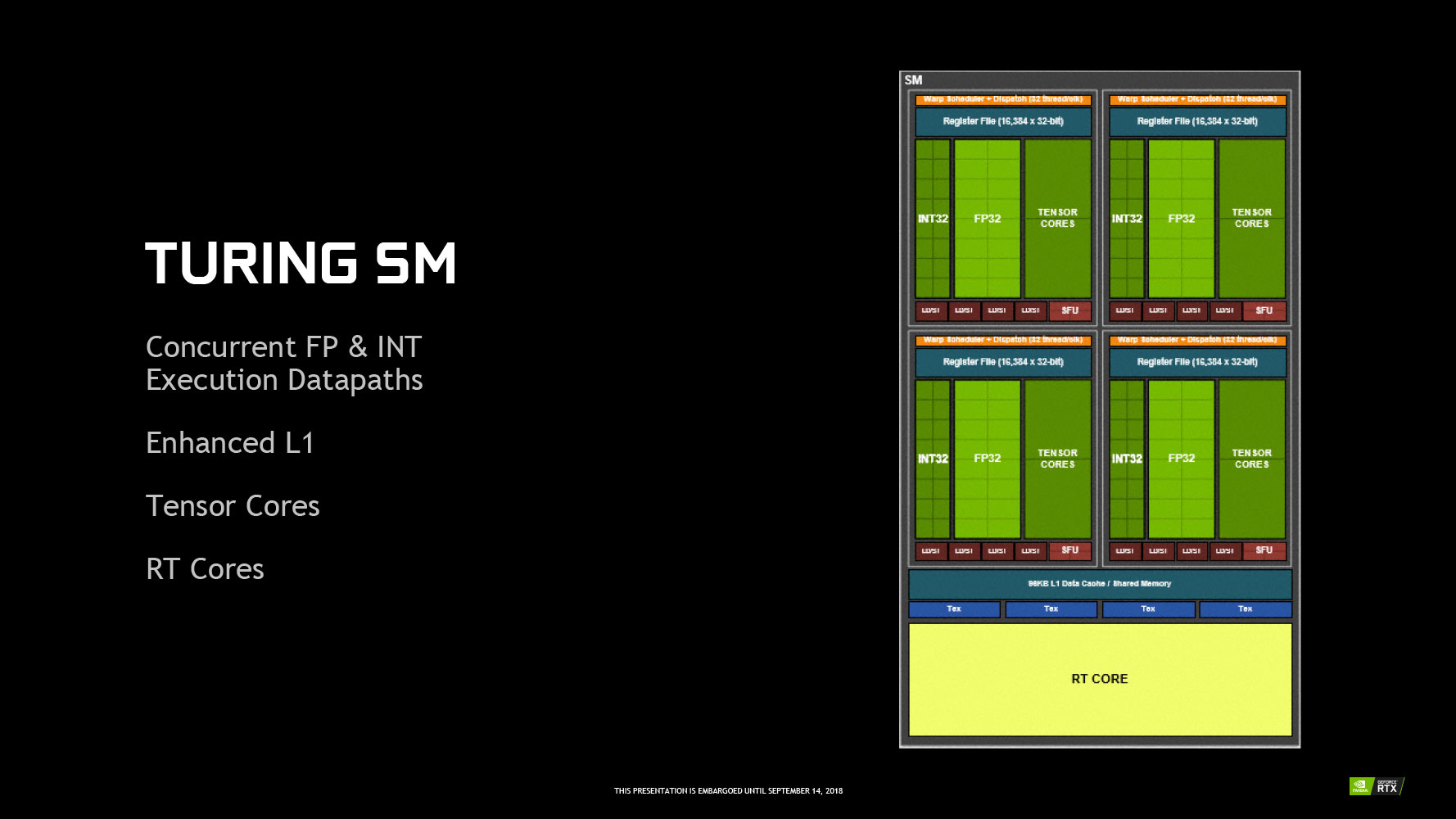
The component hierarchy of a "Turing" GPU isn't much different from its predecessors, but the new-generation Streaming Multiprocessor is significantly different. It packs 64 CUDA cores, 8 Tensor Cores, and a single RT core.
TU104 Silicon


The TU104 is the second largest silicon based on the "Turing" architecture and powers the GeForce RTX 2080. It's also significantly larger than its predecessor, holding 13.6 billion transistors.
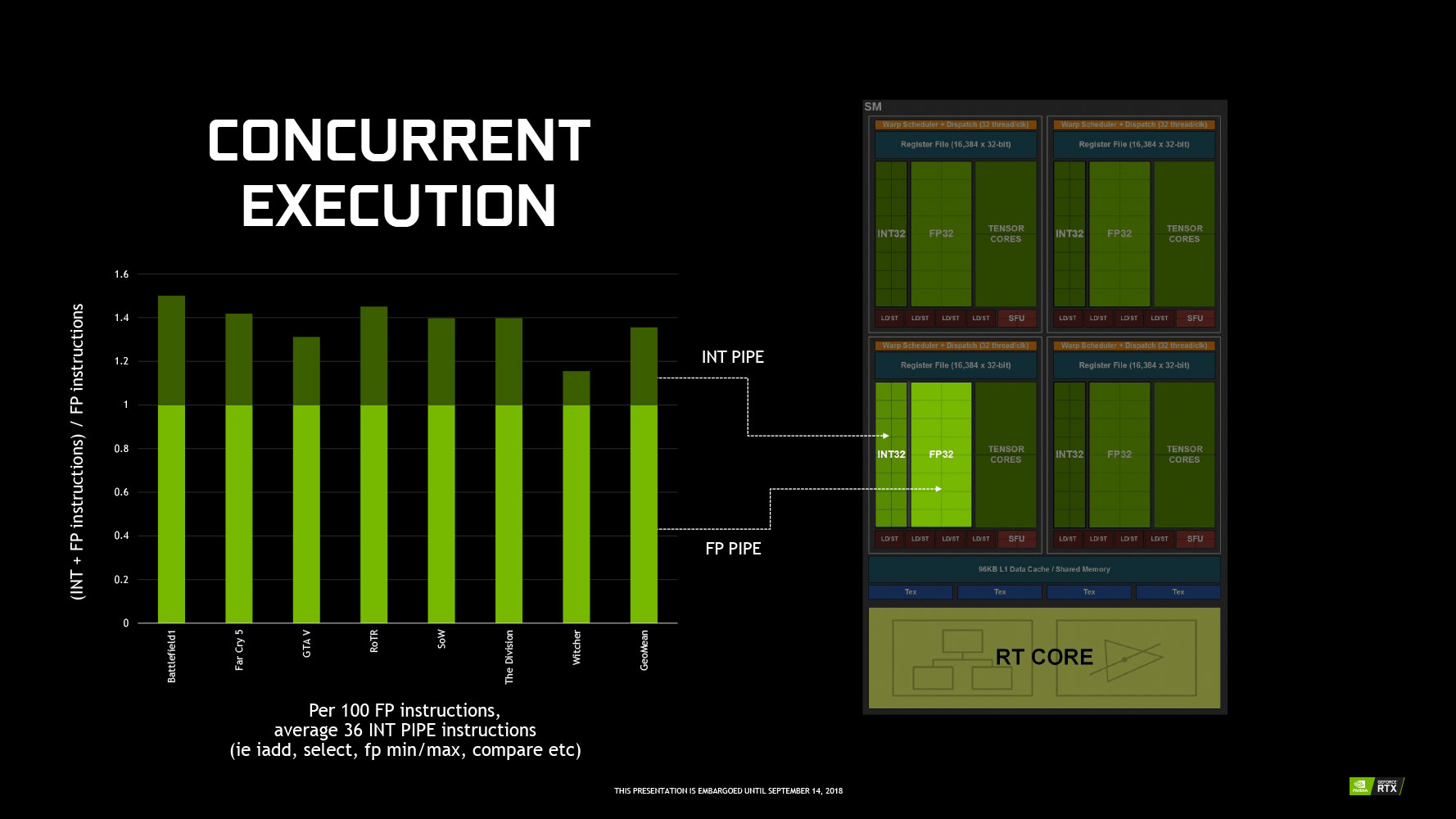
The essential component hierarchy on the "Turing" architecture hasn't changed. What has changed, however, is that the Streaming Multiprocessor (SM), the indivisible sub-unit of the GPU, now packs CUDA cores, RT cores, and Tensor cores, orchestrated by a new Warp Scheduler that supports concurrent INT and FP32 ops, which should improve the GPU's asynchronous compute performance.
At the topmost level, the GPU takes host connectivity from PCI-Express 3.0 x16, an NVLink interface, and connects to GDDR6 memory across a 256-bit wide memory bus. On the RTX 2080, this bus drives 8 GB of memory clocked at 14 Gbps. The GigaThread engine marshals load between six GPCs (graphics processing clusters), unlike predecessors of the TU104, which generally only had 4 GPCs. Each GPC has a dedicated raster engine and four TPCs (texture processing clusters). A TPC shares a PolyMorph engine between two SMs. Each SM packs 64 CUDA cores, 8 Tensor cores, and an RT core. There are hence 512 CUDA cores, 64 Tensor cores, and 8 RT cores per GPC; and a grand total of 3,072 CUDA cores, 384 Tensor cores, and 48 RT cores across the TU104 silicon.
The GeForce RTX 2080 is carved out of the TU104 by disabling two SMs or one TPC, resulting in 2,944 CUDA cores, 368 Tensor cores, and 46 RT cores. The GPU is endowed with 184 TMUs and 64 ROPs.
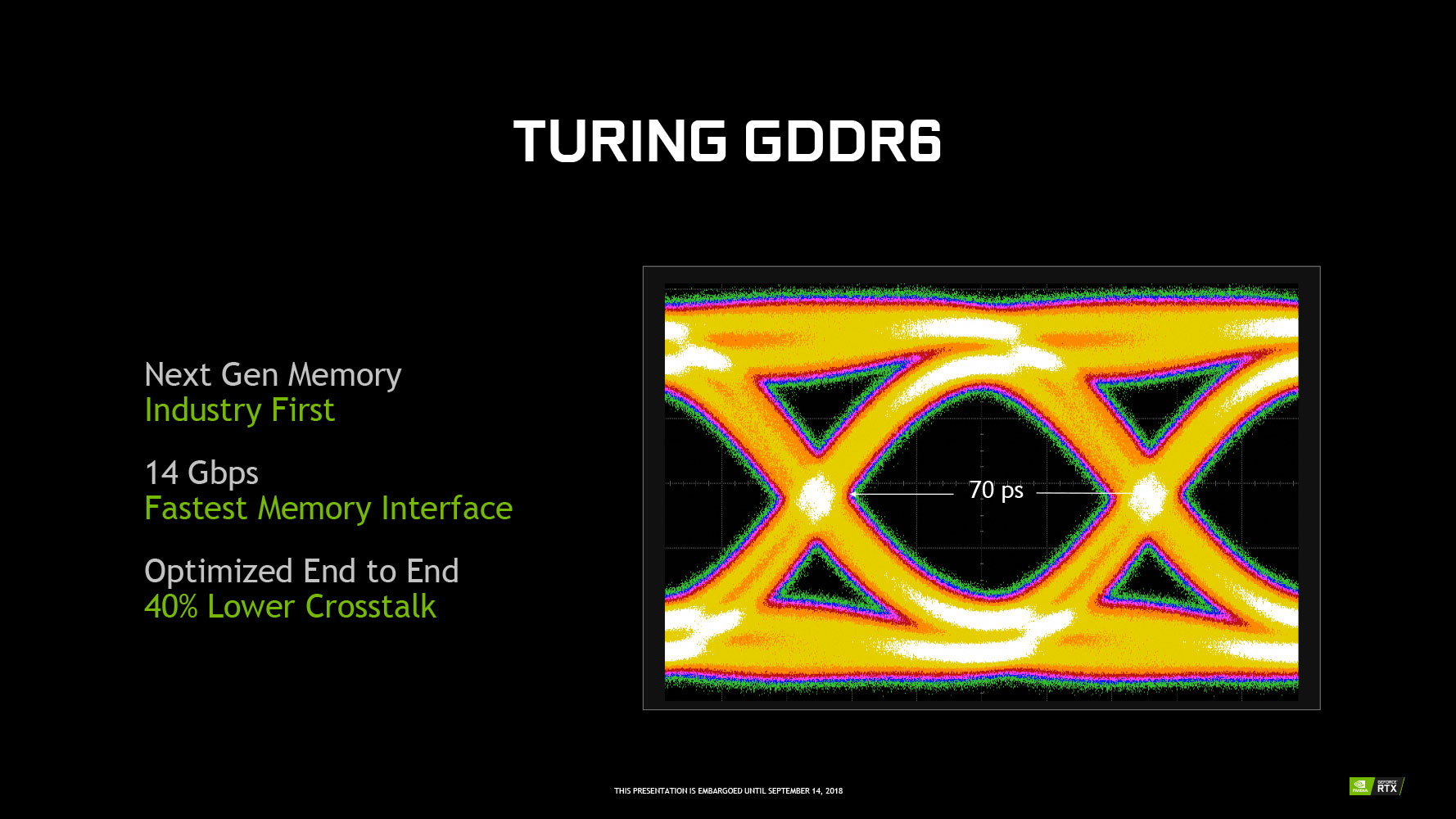
The GeForce RTX 2080 maxes out the 256-bit GDDR6 memory bus width of the TU104 silicon, wiring it to 8 GB of memory. Ticking at 14 Gbps, this setup belts out a memory bandwidth of 448 GB/s.
Features
Again, we highly recommend you to read our article from the 14th of September for intricate technical details about the "Turing" architecture feature set, which we are going to briefly summarize here.
NVIDIA RTX is a brave new feature that has triggered a leap in GPU compute power, just like other killer real-time consumer graphics features such as anti-aliasing, programmable shading, and tessellation. It provides a programming model for 3D scenes with ray-traced elements that improve realism. RTX introduces several turnkey effects that game developers can implement with specific sections of their 3D scenes, rather than ray-tracing everything on the screen (we're not quite there yet). A plethora of next-generation GameWorks effects could leverage RTX.
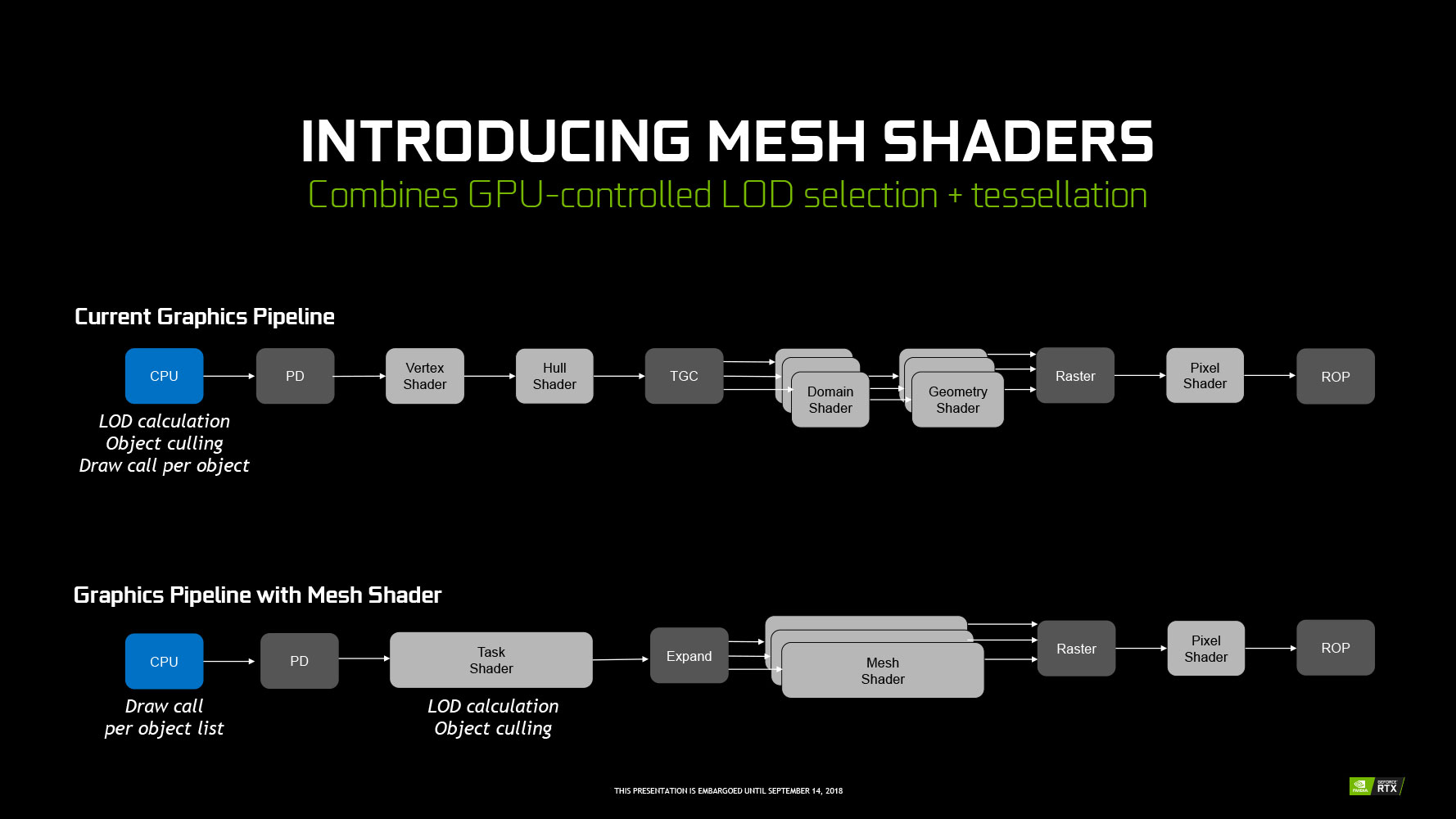



Perhaps more relevant architectural features to gamers come in the form of improvements to the GPU's shaders. In addition to concurrent INT and FP32 operations in the SM, "Turing" introduces Mesh Shading, Variable Rate Shading, Content-Adaptive Shading, Motion-Adaptive Shading, Texture-Space Shading, and Foveated Rendering.


Deep Learning Anti-Aliasing (DLSS) is an ingenious new post-processing AA method that leverages deep-neural networks built ad hoc with the purpose of guessing how an image could look upscaled. DNNs are built on-chip, accelerated by Tensor cores. Ground-truth data on how objects in most common games should ideally look upscaled are fed via driver updates, or GeForce Experience. The DNN then uses this ground-truth data to reconstruct detail in 3D objects. 2x DLSS image quality is comparable to 64x "classic" super sampling.
Apr 2nd, 2025 01:51 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Whats the Deal with the 570 nvidia drivers ? (8)
- Microprose: Falcon 5.0 - Well under development- yeay (6)
- Build complete! Any thoughts on undervolting? (22)
- RX 9000 series GPU Owners Club (97)
- RTX 3090 is still a good card? (35)
- What's your latest tech purchase? (23446)
- Nvidia culls 10bit video support on 50 series. (0)
- Help me pick a UPS (16)
- Which version of GPU-Z for Windows XP Pro 32 bit? (1)
- HIS 7870 IceQ Turbo 2GB EFI BIOS for Mac OS (0)
Popular Reviews
- DDR5 CUDIMM Explained & Benched - The New Memory Standard
- Sapphire Radeon RX 9070 XT Pulse Review
- SilverStone Lucid 04 Review
- ASRock Phantom Gaming B850 Riptide Wi-Fi Review - Amazing Price/Performance
- Palit GeForce RTX 5070 GamingPro OC Review
- Gigabyte GeForce RTX 5080 Gaming OC Review
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- Samsung 9100 Pro 2 TB Review - The Best Gen 5 SSD
- Assassin's Creed Shadows Performance Benchmark Review - 30 GPUs Compared
- be quiet! Pure Rock Pro 3 Black Review
Controversial News Posts
- MSI Doesn't Plan Radeon RX 9000 Series GPUs, Skips AMD RDNA 4 Generation Entirely (146)
- Microsoft Introduces Copilot for Gaming (124)
- AMD Radeon RX 9070 XT Reportedly Outperforms RTX 5080 Through Undervolting (119)
- NVIDIA Reportedly Prepares GeForce RTX 5060 and RTX 5060 Ti Unveil Tomorrow (115)
- Over 200,000 Sold Radeon RX 9070 and RX 9070 XT GPUs? AMD Says No Number was Given (100)
- NVIDIA GeForce RTX 5050, RTX 5060, and RTX 5060 Ti Specifications Leak (96)
- Retailers Anticipate Increased Radeon RX 9070 Series Prices, After Initial Shipments of "MSRP" Models (90)
- China Develops Domestic EUV Tool, ASML Monopoly in Trouble (88)