Monday, July 11th 2011

AMD FX-8130P Processor Benchmarks Surface
Here is a tasty scoop of benchmark results purported to be those of the AMD FX-8130P, the next high-end processor from the green team. The FX-8130P was paired with Gigabyte 990FXA-UD5 motherboard and 4 GB of dual-channel Kingston HyperX DDR3-2000 MHz memory running at DDR3-1866 MHz. A GeForce GTX 580 handled the graphics department. The chip was clocked at 3.20 GHz (16 x 200 MHz). Testing began with benchmarks that aren't very multi-core intensive, such as Super Pi 1M, where the chip clocked in at 19.5 seconds; AIDA64 Cache and Memory benchmark, where L1 cache seems to be extremely fast, while L2, L3, and memory performance is a slight improvement over the last generation of Phenom II processors.


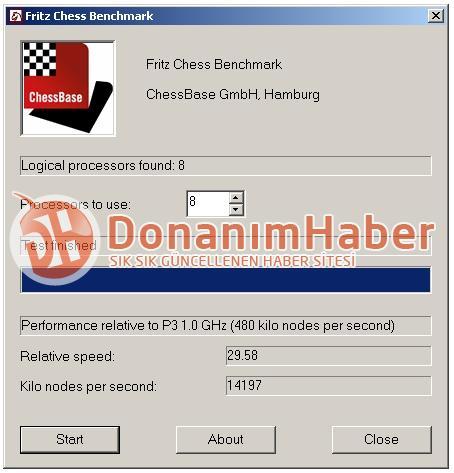
 Moving on to multi-threaded tests, Fritz Chess yielded a speed-up of over 29.5X over the set standard, with 14,197 kilonodes per second. x264 benchmark encoded first pass at roughly 136 fps, with roughly 45 fps in the second pass. The system scored 3045 points in PCMark7, and P6265 in 3DMark11 (performance preset). The results show that this chip will be highly competitive with Intel's LGA1155 Sandy Bridge quad-core chips, but as usual, we ask you to take the data with a pinch of salt.
Moving on to multi-threaded tests, Fritz Chess yielded a speed-up of over 29.5X over the set standard, with 14,197 kilonodes per second. x264 benchmark encoded first pass at roughly 136 fps, with roughly 45 fps in the second pass. The system scored 3045 points in PCMark7, and P6265 in 3DMark11 (performance preset). The results show that this chip will be highly competitive with Intel's LGA1155 Sandy Bridge quad-core chips, but as usual, we ask you to take the data with a pinch of salt.




Source:
DonanimHaber








317 Comments on AMD FX-8130P Processor Benchmarks Surface
I 110% understand the point you are trying to make. I am simply refusing to go down that road, because it serves no importance to the discussion at hand. You simply want to try to refute my postings, and slide in some doubt, but sorry, I'm not gonna fall for it. I never claimed SuperPi was only impacted by memory performance.
3.6GHz is the max turbo core with all cores in use
3.2GHz is the stock clock
Today was June 1st
July 31st -> August 31st
AIDA64 is a memory subsystem benchmark
SuperPi is a x87 benchmark and only really stresses L1 <-> L3 memory
the rest are basically media benchmarks
3dmark 07/11 are both gaming class benchmarks
The reason the engineer sample is not a valid way to show off Zambezi is because it isn't at spec
Zambezi 8130P ES 3.2GHz/3.6GHz/4.2GHz @ 185wTDP
Zambezi 8130P RS 3.8GHz/4.2GHz/4.8GHz @ 125wTDP
FPU would be the same even if one integer cluster was removed don't you think? It would do the same, because if it was just 128b then BD wouldn't be able to work with AVX.
devguy
I know that quote, I saw it some time ago. Its down to what is a core, for most people it's probably an Integer cluster, but for me not.
Then every core diagram from AMD is wrong because they are not showing just the integer part what is a "core for most people" but also decoder, FPU, L2 cache, prediction, prefetch and so on which are not in integer cluster so they shouldn't be shown in a core diagram but in a cpu diagram with L3 cache, HTt, IMC.
You're the one that defined the importance of this. You scoffed at the poor super pi results and then went on about how it told you so much about the memory and in-turn the gaming performance. Only given the 775 comparison it would seem that it didn't really correspond.
All this speculation and trolling is worth less than the benchies from the eng sample.:nutkick::shadedshu
SuperPi is not good benchmark to evaluate relative everyday performance of different CPUs but it is good benchmark to see if AMD made any progress on it's decoding and real-time optimization units.
SSSE3, SSE4.1, SSE4.2, XOP, CVT16, FMA4, LWP all increase the performance of the FPU SSEs capabilities
Bulldozer is a generation leap in light speed
I'm not saying Zambezi that time because I'm talking about the architecture not the CPU
I mean really, going by SuperPi times alone there, my SB @ 4.9 GHz would be near 3x faster than the BD in the OP. Do I think my SB is 3x faster?
Uh, no?!?
:laugh:
It's merely one in a long list of examples where memory performance matters. Again, F1 2010 is example of a game (ie real-world) that can be impacted quite largely by memory performance...is it ONLY impacted by memory performance? NO! Are there ways to overcome that problem? You Bet!
So, I still fail to see your point, which is why I called you a troll. It's not just about cache. It's not just about memory bandwidth. It's not just about CPU core frequency. Each and every one is important when it comes to performance, and each has it's own implications and impacts on performance.
You, on the other hand, are centering on one aspect of how I have formed my opinion on what's important, while ignoring the rest.
So, now that's all said, what was your point again? Maybe your right, and I fail to understand, so why don't you just spell it out for me, please?
To reiterate my example, why is the IMC allowed to be shared without people questioning whether it is a "core" or not? Forcing each "core" to be queued up to communicate with main memory rather than having its own direct link could marginally impact performance. Forcing each "core" in a module to share a branch predictor could marginally impact performance. Why is the first okay, and not the second?
what you quoted was JF saying core for most people is integer cluster(ALU, AGU, INTeger scheduler and some L1D cache) yet in a core diagram regardless if architecture is BD, Phenom or Athlon they are showing not just these parts but also decoder, FPU dispatch, L2 cache, prefetch and some other parts so can you tell me how is it right and not wrong? based on this I would say these are also parts of a core and not just a small portion what JF mentioned.
I don't know why you are so hung up on IMC not being dedicated for every single core, what do you say about this, because if every core had his own IMC that would mean in a 4 core CPU every core would have just 32b bus instead of a shared IMC where if not all cores are active, one core can have 128b width and not just 1/4 and its impossible to have 128b for every single core in a 4 core cpu, that would mean 512b width memory access, look at SB-E it has just 256b memory access and they had to place two memory slots on both sides, just so it wouldn't be too complicated or expensive to manufacture.
All CPU architectures are based on Von Nemann's design which specified, a CPU, main memory and i/o module. The 3 are separate things, whether they are included in the same package or not.
Now CPUs have an integrated memory controler, but that does not make it part of the CPU really, it makes them part of the CPU die. We can say the same about high level caches actually, they are on die, but they are NOT the CPU, nor are they part of the CPU.
Or what's next? We will call a core to every GPU shader processor on die, because they have an ALU? pff ridiculous.
P.S. forget my comment except my thanks:), I am just too sleepy so I didn't grasp right the meaning of some words.
Performance increase from here on but some people want to know how much and some of us can help with that
I shot out a number
10% to 30% very modest to me
As the Engineer Sample is already good enough for me*cough*Fermi*cough* *cough*16 cores*cough* *cough*512 ALUs*cough*
*cough*Northern Islands*cough* *cough*384 cores*cough* *cough*1536 ALUs*cough*
More or so the AMD GPU than the Nvidia GPU
It's already happening oh noes
Yes it's more than memory performance. It's the architecture overall. You act like because Intel's architecture favors super pi it favors all games. It does not. There are games that favor AMDs architecture as well. Because of this you shouldn't be focusing on super pi as any sort of performance indicator across platforms. A far better question at this point is just wth was your point supposed to be? You start by saying "Wake me up when AMD can reach these." Putting the utmost emphasis on a test that as it turns out has no bearing on the overall gaming performance you care so much about. Then you proceed to gradually back track and down play that initial stance increasingly as we move on through the thread, while expertly misunderstanding what I was saying. Now you get what I mean and you decide to move on to talking about the IPC. It's not even about what you're arguing as much as it is about not appearing to be wrong is it? Arguing with you has been like looking at a funhouse mirror. Doesn't matter what the input is everything you get back is all wonky.
Let me try to explain what’s happening here. I feel you have trouble expression your very rigidly held opinions. A lot of the things you say come off as confusing and poorly defined. These are things I don’t respond well too. Then you laugh at people and call them trolls when your confusing statements are challenged. Jackassery is something I don’t respond well to either. Both of those together make me very unpleasant. Frankly I don’t think anyone should be expected to be pleasant in the face of that. So like with the SB overclocking thread I think I’ll just stop visiting this.
The first rule of the internet is
1. Don't annoy someone who has more spare time than you do.
AMD hasn't inflated any numbers
They have only said CMT is a more efficient way of what SMT tries to achieve
SMT = more threads on the die without increasing the amount of cores
CMT = more cores on the die with a 50% die increase from Phenom II
4 x 150 = 600%
6 x 100 = 600%
So, Bulldozer is about the same die size as Thuban while achieving relatively the same performance per core while having more cores
Why do you rely so heavily game results / benchmarks determine your chosen platform?
The hilarious part is, over half the gaming reviews / benchmarks published are pure BS.
Heres how it breaks down in the end:
Intel - sure, you get amazing fps on lower resolution settings, you get good fps on more normal resolution and maybe a bit of eyecandy turned on. But when it comes down to the actual meat of what matters in a game (min fps)...AMD and Intel are VERY VERY close. Sure, intel still outreaches AMD in some games, in min fps at decent settings....but in the end. Intel vs AMD - gaming....um...pretty much even when you take into account whats important (min fps).
All these benches showing highest fps or even avg fps, to a lesser extent, are nearly meaning less...because highest fps and avg fps are most likely ALWAYS at a decent playable fps. Whereas min fps may not always be so playable. So who does best when shit hits the fan is the winner...the problem is, there is hardly any best in this case. They are nearly tied in most cases.
The only time where it may mean otherwise is if your GPU is so powerful that any resolution and any hardcore graphics settings, peg your CPU @ 100% - therefore bottlenecking your GPU (especially if the GPU show significant usage less than 100%).
So, really when it comes down to it...AMD vs Intel... both fast enough to handle nearly any amount of GPU power available today, now stop arguing over it!
A GPU core is not the same as a CPU core, so it's pointless to make any argument from that. When it comes to functionality, yes GF100/110 (and not Fermi*) has 16 cores (looking at it from a compute perspective) with 32 ALU each. In reality it has 2 SIMD ALUs each. And this is good BTW. Why on earth would you say that GF110 has 16 cores and 512 ALUs, when in fact each "core" has two parallel and totally independen execution units (SIMDs)? Why not say that it has 32 "cores", 16 modules? Because Nvidia chose not to claim that?
And Cayman has 24 "cores" not 384.
* Fermi can have 16, 8, 4... of so called "cores" (GF100, GF104, GF106...). I never call them cores anyway. Not even Nvidia calls them cores, as in GPU cores. They call them CUDA cores, and when it comes to CUDA execution, they are CUDA cores in many ways. In that each one can take care of 1 cuda thread.
Zambezi is a(n) native 4/6/8 core processor because it has the basic components to be called a(n) 4/6/8 core processor
My point is that most companies base the "core" amount on how much ALUs they have or how many executions possible the ALU can fart out
if so happen AMD ditched x87 and made it slow in favor of SSE then SSE versions of SuperPi floating around the net should show than difference amd vs intel should be lower. Is it any lower? Or SSE performance of Intel CPUs is also "pretty high"? :laugh:Lacking such obvious extension like SSSE3 in 2011 AMD CPU is quite troubling and Bulldozer will fix that which is good for Intel CPU also :p
24 x 16= 384
384 x 4 = 1536No they don't and if they did, they shouldn't. Each CPU core since the superscalar desing was implemented a loooooooooong time ago has more than 1 ALU per core. So 1 ALU could never be a core.