Friday, December 16th 2011

Radeon HD 7970 Tessellation Performance Figures Surface
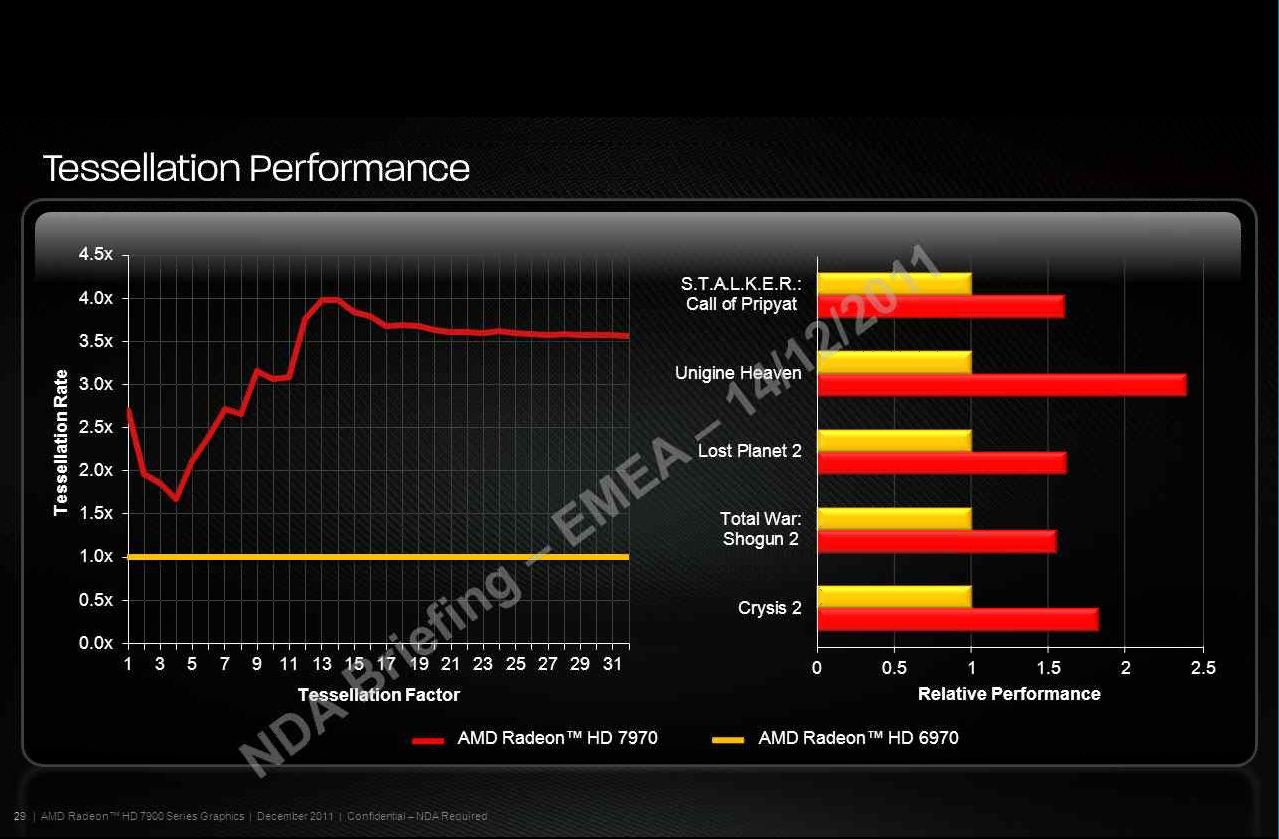
Among the bits and pieces (read: slides) of AMD's press presentation that we're getting, a slide that's definitely missing is performance against competitive or previous generation graphics cards across a range of applications/games. Instead, there's a slide detailing tessellation performance improvements of the Radeon HD 7970 over the previous-generation HD 6970. On average, AMD is looking at about 1.5x (50%) improvements in the tests that it run. One has to also take in to account that the HD 7970 is a faster GPU overall, compared to HD 6970, and of course, that these are AMD's figures.
Source:
ComputerBase.de
53 Comments on Radeon HD 7970 Tessellation Performance Figures Surface
I am not sure how well nVidia did in Tessellations but normally only the stuff that AMD want to get leaked actually gets leaked, from this i would read that the Tess improvement is 7970's biggest improvement.
I hope i am wrong.
Summary - this is bad news: AMD PR slides tell that this is only 50% faster in tessellation nothing else PR has to say to us? considering that this is one of AMD famous PR slideis - it is way less then what they say.
So the "selective leak" focusses on raw tessellation performance only for the WOW factor, because fps performance is lackluster.
Well, if they get similar real world games performance as the 6xxx series but at half the power consumption on the new fab, then it's still a major improvement.
That's current gen cards.
So what is it really mate? And besides mate, if you further check on Tech Report's revisions on their methodology, FPS isn't exactly the ultimate factor, mate.
Also, I'd rather wait for the reviews next week than argue these performance numbers...
* In Cayman 16 shaders (4d VLIW) were directly inside a single SIMD unit and the SIMD unit was directly connected to the uncore.
Now it's shaders (1d) inside a SIMD, inside a CU, connected to uncore. One more step that could or not degrade performance a few percents. The closest example of such an arrangement is Fermi, and it did suffer a substantial performance degradation from the new modular aproach, compared to the old arrangement. The benefits are very predictable performance increase and that scaling will never suffer as you increase the number of SMs (Nvidia) or CUs (AMD).
The pattern is similar this time, so I'm afraid that it could actually be true. This time is the reverse tho, I've known the architecture for a long time, but without knowing the specs I could not make any assuption regarding final performance, then the specs came in, then his performance numbers, but the effect is the same.
With 2048 SPs you really need them SPs to be a lot faster/efficient than they were if you want the card to be significantly faster. It is fairly posible to have much faster SPs, but like with BD we again depend on a net "IPC" increase in order to get a significant performance gain. Since I don't want to believe in fairies again, I'm counting on SPs being fairly equal hence with 30% more SPs and 30% more TMUs and similar clocks, 30% performance increase is kinda the maximum I would expect. According to OBR numbers, net "IPC" or perf-per-shader might actually be slightly down and wihle it was not something I would have expected, it's not really something completely imposible.
Again I don't expect shaders themselves to be very different from what they were.Yeah, but I wouldn't count on that. I'd rather be surprised than dissapointed. Again.
And the complete lack of any performance slides other than tesselation performance is not good really.