Friday, November 6th 2015

AMD Dragged to Court over Core Count on "Bulldozer"
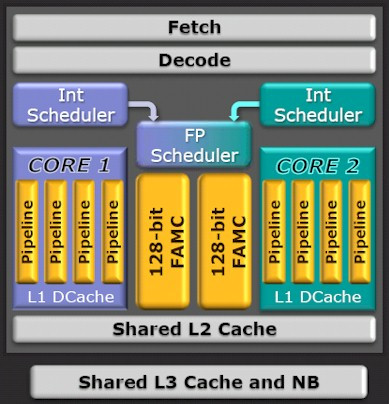
This had to happen eventually. AMD has been dragged to court over misrepresentation of its CPU core count in its "Bulldozer" architecture. Tony Dickey, representing himself in the U.S. District Court for the Northern District of California, accused AMD of falsely advertising the core count in its latest CPUs, and contended that because of they way they're physically structured, AMD's 8-core "Bulldozer" chips really only have four cores.
The lawsuit alleges that Bulldozer processors were designed by stripping away components from two cores and combining what was left to make a single "module." In doing so, however, the cores no longer work independently. Due to this, AMD Bulldozer cannot perform eight instructions simultaneously and independently as claimed, or the way a true 8-core CPU would. Dickey is suing for damages, including statutory and punitive damages, litigation expenses, pre- and post-judgment interest, as well as other injunctive and declaratory relief as is deemed reasonable.
Source:
LegalNewsOnline
The lawsuit alleges that Bulldozer processors were designed by stripping away components from two cores and combining what was left to make a single "module." In doing so, however, the cores no longer work independently. Due to this, AMD Bulldozer cannot perform eight instructions simultaneously and independently as claimed, or the way a true 8-core CPU would. Dickey is suing for damages, including statutory and punitive damages, litigation expenses, pre- and post-judgment interest, as well as other injunctive and declaratory relief as is deemed reasonable.
511 Comments on AMD Dragged to Court over Core Count on "Bulldozer"
Seagate did not counter sue Microsoft for not correctly labeling hard drive capacity (using math for GiB but showing a GB label). AMD could certainly try to sue Microsoft but where Seagate had a strong case against Microsoft (and still does), AMD really doesn't against Microsoft. What AMD wants to call a "core," no one else does. Microsoft would have to make an exception for Bulldozer and how can Microsoft adequately explain to the public what is weird about Bulldozer in two words? They can't. AMD really brought this on itself by not making it clear to the public the product is different and it will have to pay the price for it.
There is no "minus" for a core. It either is a complete processor or it isn't.
Pretty much everything is shared except the integer clusters. We're talking about 20% of a CPU that isn't shared. 20% a processor does not make. One core: two integer clusters and two threads.
This is a FX-8320 piledriver 8c/8t.
Now compare an Ivy bridge 4c/8t.
It looks like based on what i've seen, each module was designed as one core with extra hardware for multithreading under most workloads. Somewhere along the way they decided to market it as each module was two cores. I think this was a mistake; bulldozer would have looked like a much faster chip if the FX-8150 was marketed as a 4c/8t chip. Instead we got an 8c/8t chip that marginally hurt the performance when 2 threads were scheduled to the same module compared to spreading them out between modules before doubling them up.
I take it Dhrystone sees HTT and limits itself to 4 cores?
Second is the parallelism of the workflow you have to input in processor. Not everything can be parallelized infinitely. Codes nowadays are not well designed to be on so many cores, and you'll see on other 8 cores and 12 cores Intel processors, you'll begin to see the same exact behaviour.
If you want to read some good text, written by Intel, you can purchase this one : www.computer.org/csdl/mags/so/2011/01/mso2011010023-abs.html
Without talking of hyperthread or anything, after 4 cores, the current way we compile and program stuff, don't take all advantage of being parallelized. Graphic is also from Intel, on how they see cores behave, it's part of the article above.
It's funny though seeing you trying to analyse data and interpret them to suit your point of view on something.
I'll show you yet another example of a program i personally worked on. compression.ca/pbzip2/
Nothing in real life have an infinite linear curve. There's always a limit to which an application can be parallelized. Every processor, every software and every instructions show that kind of behaviour.
It is a law, it is calculated, it is calculable. research.cs.wisc.edu/multifacet/amdahl/
Get your science right.
EDIT : You remained blind to all proof presented to you so far. Don't say there's no proof, everything converge as a proof. If you had an once of honesty i can prove you are wrong. I made the test myself some times ago, as i worked on the ondemand governor, which made the core clock fluctuate depending on the workflow. I made the test to be 100% sure if one core is at 1600MHz and the other is at 3900MHz, that the virtual machine bound to one of the module core won't get affected by the other at lower speed. Both integers and FPU are slower on the 1600MHz core, and both are faster on the 3900MHz core. Both work independently. Until i throw an AVX instruction, then the entire FPU clock is getting at the speed of the core asking for the unification, until the instruction is done. You can even try it yourself with QEMU/KVM, while putting a core affinity to the VMs, one on the first module core, other on the second module core. Very easy to replicate. When i don't use AVX, i have 100% of the time 2 cores in a module. But you continue putting your head in sand, playing blind.
EDIT 2 : I am also surprised on how inaccurate your point of views are. It's actually the opposite, AMD have a semi SMT, because it can't have another thread on a core in a module. It's one of the bottleneck of the cores in the module. with the fact it is not ordering well. Hyperthreading is a much much better SMT implementation, and takes a lot more space on the die. Complete opposite. For that you seem to talk about, you're claiming it's transparent to the OS, when it's not, at all. 95% of the thread management is made my the kernel, the threads library and the kernel, all software. The processor only order them to the right core/module and then to the right thread. The processor don't decide what core will take what thread, the kernel do. What the processor decide is what it will do with the thread. The Intel SMT is better too because it don't have 2 cores to supply, the hyperthreaded one don't have to be on time and constantly supplied like the AMD Bulldozer have to.
Microsoft is very very bad at handling threads, unlike Linux. Because Linux was used with SPARC and other servers to have like 8 chips, with 16 cores, 128 threads. But before hyperthreading, Windows kernel never had a proper threading library. It's normal for a SPARC to have so many threads, as it's a RISC, not a CISC. In Linux they just have to modify some point of the kernel to make it recognize the module as a core with multiple threads. It doesn't change anything, except it will address threads like it should be. If the big SMT would be detrimental for the design, you can be sure a SPARC or ALPHA processor would be bottleneck like there's no tomorrow. But it's not. Pretty much everything composing your logic is opposite to what is established in computer engineering.
When people complain about Bulldozer, what is the #1 complaint? I'll give you a hint: It's not multi-core performance. The biggest complaint is single-threaded performance so, even without another task trying to utilize the FPU, performance still sucks and that isn't because BD doesn't have "real cores." The fact that the FPU is shared is beside the point but you seem to be incredibly intent on making it an upfront issue. The simple fact is that BD's performance blows because the number of uOps BD can execute at any given time was seriously reduced over K12. Since dispatch width per core is significantly reduced, it's completely possible that instructions before that might take 3 or 4 clock cycles now might take 5 or 6 because of the reduced width of even integer operations because AMD slimmed down the core, they didn't just share some parts like the FPU and dispatch/decode hardware as opposed to beefing up each core which would take up more die space and would reduce how many cores you could cram in for a given size. AMD's mistake was that multi-core performance didn't make up for the loss in single-threaded performance. Pair that up with poor hit rates for cache and pipeline stalls due to a very long pipeline and you have a recipe for a disaster.
People need to stop being obsessed with reducing this problem to something as simple as "it doesn't have real cores," because the problems with Bulldozer are much greater and larger in number than merely a shared FPU but that's all everyone seems to be focused on because honestly, if you need so much floating point bandwidth that a single SIMD unit is too slow, you should be using something optimized for massively parallel SIMD operations like GPUs.
Lets say for a minute Bulldozer didn't have the second integer core, okay? Would you still be pissed off because performance is crap because the FPU has half of the floating point capability as both K12 and SB and later Intel CPUs? The FPU literally can do twice as much on K12 and SB+ because it's twice as wide as Bulldozer's.
So if you want to get pissed off about something, get pissed off about that because a second integer core doesn't change the fact that the FPU already is seriously under-powered, even if it wasn't shared, which will continue to plague AMD if they don't change that in Zen.You mean how you can still buy a 1TB drive and find that 92.7GB is "missing" because people don't realize that HDD manufactures state SI prefixed bytes and not binary prefixed bytes?
The class wanted a 7% refund on the drives they bought which as you can see below nearly matches the difference when referring to gigabytes. Also notice how the difference increases as harddrives get larger and use larger prefixes.
The argument falls apart when you consider what would happen if AMD had doubled the width of the single FPU (not add a second one,) per module and it's impact it would have had on floating point performance and I'm willing to bet that you would instantly make up the difference but, that still doesn't fix the integer cores which is where a lot of performance is lost. Once again, the class action makes it sound like bulldozer sucks because it has a shared FPU when it's really because it has gimped FPUs. Sharing it was smart, slimming it out was not. A similarly clocked Intel quad core will have double the floating point performance than an "8 core" BD chip at the same clock. It also happens to be the case (as I said before,) that the FPU per module is half of the width of the FPU on K12 and SB through at least Haswell. If BD had FPUs that were twice as wide, it would still be shared but, if you consider the clocks that BD runs at, you make up some of that difference and floating point performance would line up more with a 6c Intel CPU if that were the case instead of somewhere between a dual-core and quad-core Intel chip at the same clock.
Simply put, you could still have a FPU on every core but, if they make the FPU half as wide than it is now per every module, you're still stuck with the same crappy performance because your ability to dispatch hasn't been improved. When using any streaming SIMD task with floating point data, the wider FPU at any given clock speed will always be faster than a narrower one because half the width means twice as many cycles to do the same thing and fewer cycles to complete a task means better IPC. So despite having twice as many FPUs, the reduced width of each unit harms overall throughput.
tl;dr: Increasing the width of the already shared FPU by double would have the same performance characteristics as doubling the number of FPUs with the current width which is reason alone to reject the "it's not 8 cores," claim based strictly on the FPU itself. Simply put, caveat emptor.
Except it sounds exactly like people are going to expect. Once again, people keep equating bad performance to "not really being cores."
I'm pretty sure you need to read #374 again and not just the beginning about Seagate.