Tuesday, February 28th 2017

NVIDIA Announces the GeForce GTX 1080 Ti Graphics Card at $699
NVIDIA today unveiled the GeForce GTX 1080 Ti graphics card, its fastest consumer graphics card based on the "Pascal" GPU architecture, and which is positioned to be more affordable than the flagship TITAN X Pascal, at USD $699, with market availability from the first week of March, 2017. Based on the same "GP102" silicon as the TITAN X Pascal, the GTX 1080 Ti is slightly cut-down. While it features the same 3,584 CUDA cores as the TITAN X Pascal, the memory amount is now lower, at 11 GB, over a slightly narrower 352-bit wide GDDR5X memory interface. This translates to 11 memory chips on the card. On the bright side, NVIDIA is using newer memory chips than the one it deployed on the TITAN X Pascal, which run at 11 GHz (GDDR5X-effective), so the memory bandwidth is 484 GB/s.
Besides the narrower 352-bit memory bus, the ROP count is lowered to 88 (from 96 on the TITAN X Pascal), while the TMU count is unchanged from 224. The GPU core is clocked at a boost frequency of up to 1.60 GHz, with the ability to overclock beyond the 2.00 GHz mark. It gets better: the GTX 1080 Ti features certain memory advancements not found on other "Pascal" based graphics cards: a newer memory chip and optimized memory interface, that's running at 11 Gbps. NVIDIA's Tiled Rendering Technology has also been finally announced publicly; a feature NVIDIA has been hiding from its consumers since the GeForce "Maxwell" architecture, it is one of the secret sauces that enable NVIDIA's lead.



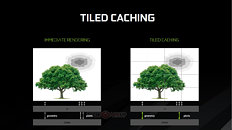
 The Tiled Rendering technology brings about huge improvements in memory bandwidth utilization by optimizing the render process to work in square sized chunks, instead of drawing the whole polygon. Thus, geometry and textures of a processed object stays on-chip (in the L2 cache), which reduces cache misses and memory bandwidth requirements.
The Tiled Rendering technology brings about huge improvements in memory bandwidth utilization by optimizing the render process to work in square sized chunks, instead of drawing the whole polygon. Thus, geometry and textures of a processed object stays on-chip (in the L2 cache), which reduces cache misses and memory bandwidth requirements.

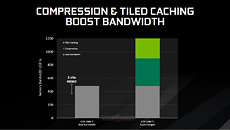
 Together with its lossless memory compression tech, NVIDIA expects Tiled Rendering, and its storage tech, Tiled Caching, to more than double, or even close to triple, the effective memory bandwidth of the GTX 1080 Ti, over its physical bandwidth of 484 GB/s.
Together with its lossless memory compression tech, NVIDIA expects Tiled Rendering, and its storage tech, Tiled Caching, to more than double, or even close to triple, the effective memory bandwidth of the GTX 1080 Ti, over its physical bandwidth of 484 GB/s.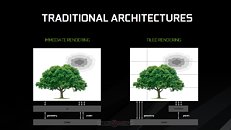

 NVIDIA is making sure it doesn't run into the thermal and electrical issues of previous-generation reference design high-end graphics cards, by deploying a new 7-phase dual-FET VRM that reduces loads (and thereby temperatures) per MOSFET. The underlying cooling solution is also improved, with a new vapor-chamber plate, and a denser aluminium channel matrix.
NVIDIA is making sure it doesn't run into the thermal and electrical issues of previous-generation reference design high-end graphics cards, by deploying a new 7-phase dual-FET VRM that reduces loads (and thereby temperatures) per MOSFET. The underlying cooling solution is also improved, with a new vapor-chamber plate, and a denser aluminium channel matrix.
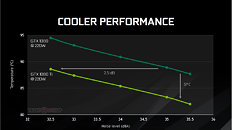
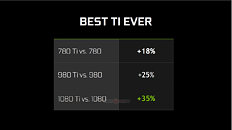
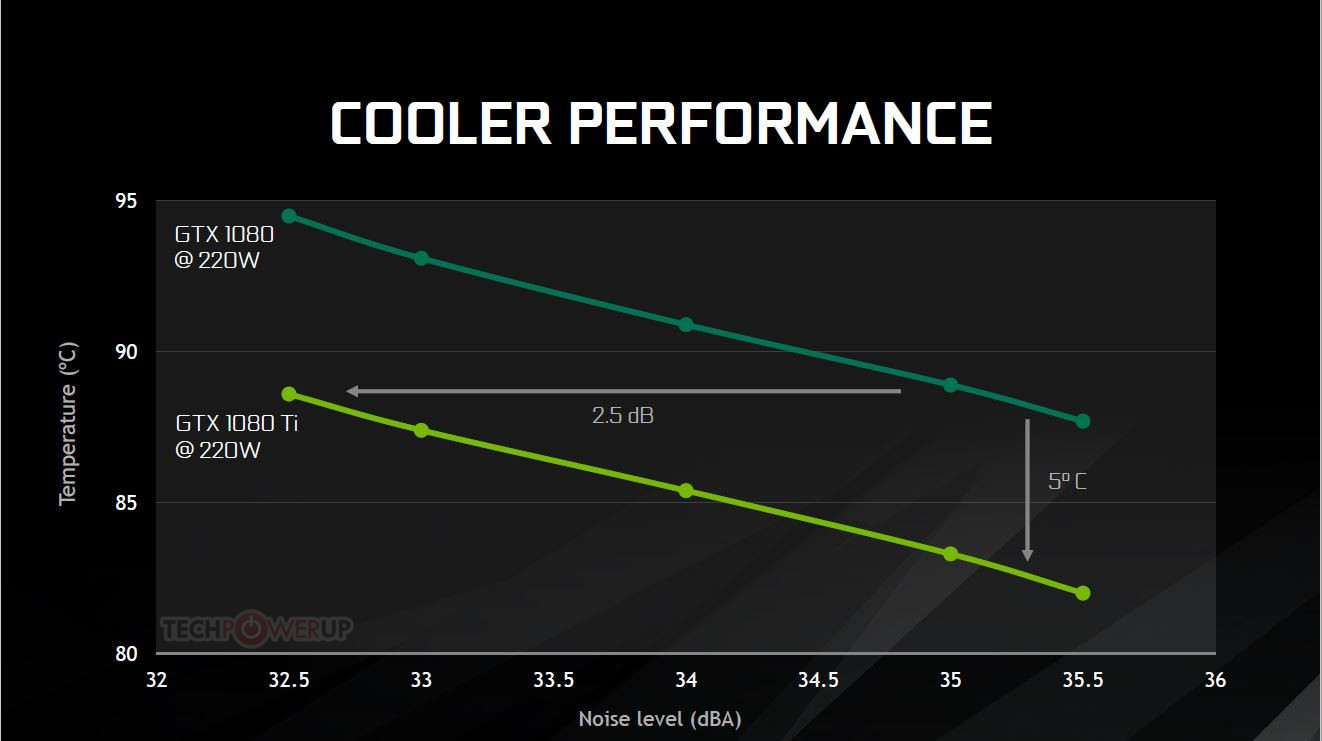
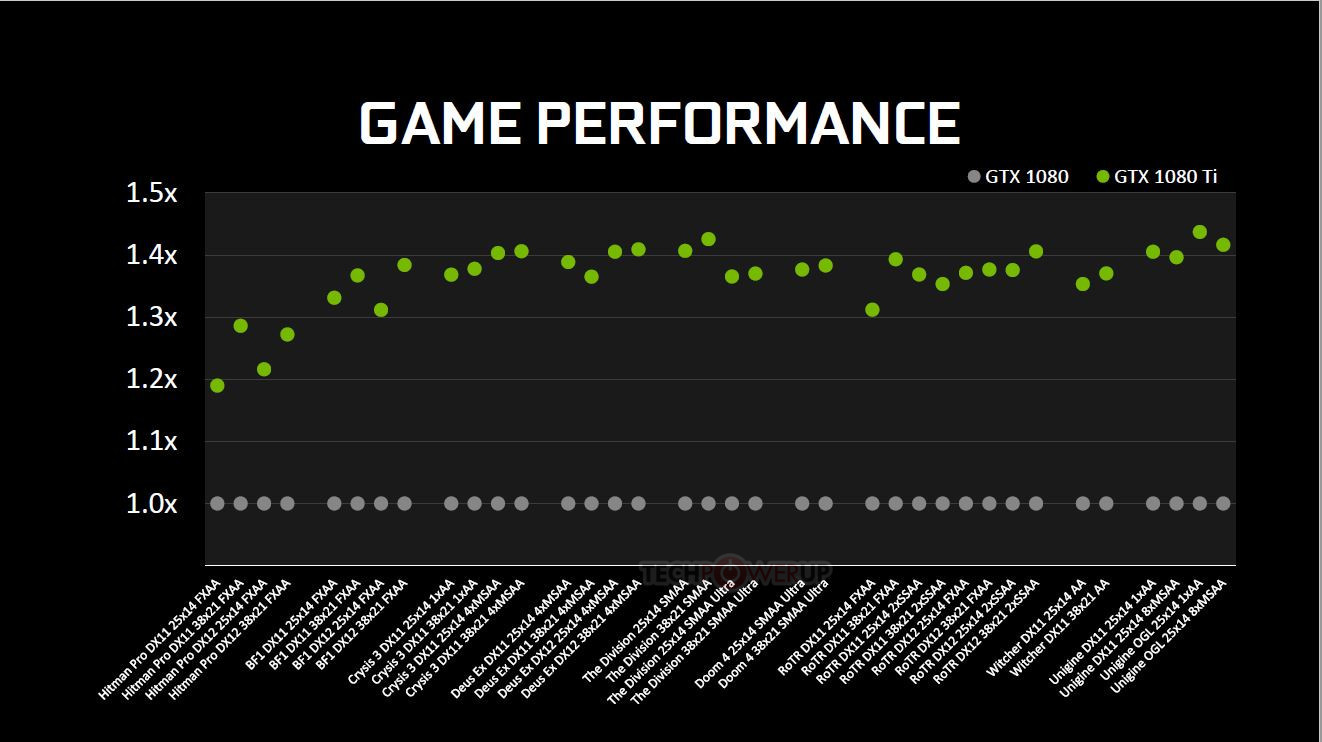
 Watt-to-Watt, the GTX 1080 Ti will hence be up to 2.5 dBA quieter than the GTX 1080, or up to 5°C cooler. The card draws power from a combination of 8-pin and 6-pin PCIe power connectors, with the GPU's TDP rated at 220W. The GeForce GTX 1080 Ti is designed to be anywhere between 20-45% faster than the GTX 1080 (35% on average).
Watt-to-Watt, the GTX 1080 Ti will hence be up to 2.5 dBA quieter than the GTX 1080, or up to 5°C cooler. The card draws power from a combination of 8-pin and 6-pin PCIe power connectors, with the GPU's TDP rated at 220W. The GeForce GTX 1080 Ti is designed to be anywhere between 20-45% faster than the GTX 1080 (35% on average).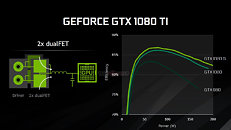
 The GeForce GTX 1080 Ti is widely expected to be faster than the TITAN X Pascal out of the box, despite is narrower memory bus and fewer ROPs. The higher boost clocks and 11 Gbps memory, make up for the performance deficit. What's more, the GTX 1080 Ti will be available in custom-design boards, and factory-overclocked speeds, so the GTX 1080 Ti will end up being the fastest consumer graphics option until there's competition.
The GeForce GTX 1080 Ti is widely expected to be faster than the TITAN X Pascal out of the box, despite is narrower memory bus and fewer ROPs. The higher boost clocks and 11 Gbps memory, make up for the performance deficit. What's more, the GTX 1080 Ti will be available in custom-design boards, and factory-overclocked speeds, so the GTX 1080 Ti will end up being the fastest consumer graphics option until there's competition.
Besides the narrower 352-bit memory bus, the ROP count is lowered to 88 (from 96 on the TITAN X Pascal), while the TMU count is unchanged from 224. The GPU core is clocked at a boost frequency of up to 1.60 GHz, with the ability to overclock beyond the 2.00 GHz mark. It gets better: the GTX 1080 Ti features certain memory advancements not found on other "Pascal" based graphics cards: a newer memory chip and optimized memory interface, that's running at 11 Gbps. NVIDIA's Tiled Rendering Technology has also been finally announced publicly; a feature NVIDIA has been hiding from its consumers since the GeForce "Maxwell" architecture, it is one of the secret sauces that enable NVIDIA's lead.
















160 Comments on NVIDIA Announces the GeForce GTX 1080 Ti Graphics Card at $699
Going to get 2 of these bad boys to replace my SLI 980Tis.
Got this from NVIDIA earlier today.
Not counting the card it released in August 2016, then it is whopping 5 month. Exciting."extra", eh?It's not hard to see the difference.
nVidia released rebranded Titan.
AMD is expected to release a brand new card.This is simply fanboi-ism, we don't know yet, but pricing that Huang has opted for, hints at something rather close.
It'll be interesting to see if that 11GB RAM has a similar issue as the GTX 970 with that slow memory due to the cut down GPU. I suspect it won't though as NVIDIA have learned their lesson from that particular scandal.
Honestly i can't think of any other way to portray the same amount of information in a simpler way. You cant just make a graph have an ascendant line, its not something you can chose. Noise x temperature graphs for coolers will always have a descendant line. Change it to fan speed x temperature and it will be similar.
Well i guess you could change it to fan noise x heat dissipation, at a fixed GPU temperature instead of power, which would result in ascendant lines. But really not the usual information people look for when choosing coolers.
Whats causing confusion is not the graph per se, but some lack of experience in interpreting graphs. If you take your time and observe the information it presents its pretty clear.
The "issue" with GTX 970 was that two 32-bit chips shared a single 32-bit bus, but with the first chip having priority resulting in "unreliable" memory performance. This is actually not new, GTX 660/660 Ti did a similar thing, but nobody complained then.
Again, it shouldnt have that 970 issue. The back end ROPs (read: the math) seems to all jive to me?
Why isn't GTX 1080 Ti interesting when it reduces the prices of the remaining lineup as well?
Anyone interested in buying a decent card soon should be cheering, it's in fact the biggest news of the year.Power of 2 matters for certain things when it comes to building integrated circuits. Allocations in system memory, allocations in GPU memory, sizes of sectors on SSDs/HDDs, etc. are all power of 2 because it decreases the complexity of the integrated circuits.
Let me crate a small example:
-----
So back to the question at hand, does it matter that GTX 1080 Ti have a total memory bandwidth of 352-bit? No, as I've said numerous times already, it has 11 separate 32-bit controllers, each accessing a power of 2 address space, adding up to a continuous address space without any kind of performance penalty. So it's not any kind of problem with 352-bits total, and if you know math you'll know that even 384-bit is not a power of 2!
An analogy; your harddrive consists of sectors, where every single one is a power of 2 in size, but the total count never is.
Edit:
Memory controllers for GPUs are in fact even more simple than CPU memory controllers. Not only is the size of allocations power of 2, but when allocating buffers for textures etc. each dimension has to be a power of 2. If you create a texture of 144×129, your API will pad it to 256×256.
To make for a really simple example, imagine that you have a memory chip with just 4 locations. These will take 2 bits to address, ie a 2-bit address bus. The value of the bottom (first) address will be zero (00 binary) and the last (top) address 3 (11 binary).
Now imagine a lopsided memory chip with just 3 locations. You will still need to build the infrastructure for 4 addresses into the chip, since the top bit is still being set, ie value 2 (10 binary) with the top address of 3 (11 binary) pointing nowhere and likely having to be masked off to avoid a crash. Hence the chip will still take the same number of transistors as if it had 4 locations, but not actually have that extra location in it and therefore the chip will not be an optimal design. Of course, what you get back is that the extra circuitry for the 4th location is missing, saving space, hence making for a compromise.
You have a similar situation regardless of what you're addressing, whether it's CUDA units and the number of bits they each handle in a GPU, or the number of CUDA units in the GPU, or whatever aspect of a digital circuit.
The problem in the real world of course, is that building a perfect power of 2 chip causes the number of transistors and physical size of that chip to double each time it's expanded, ie to grow exponentially which is unsustainable.
When you get to the large sizes of modern GPUs with their billions of transistors, it would tend to quickly outgrow the manufacturing capabilities of current technology. Or if not for a particular design, it would just be excessively large, such as being, for example, 40 millimeters on a side which is impractical for a commercial product that's supposed to make a profit.
No doubt it would also use a tremendous amount of power and emit a correspondingly tremendous amount of heat, making things difficult. Therefore, we see the lopsided GPUs of today to avoid this fate, or at least reduce its impact. Think of the GTX 480 and the tremendous amount of power and heat it used, despite being such a lopsided design. It's a shame and I really don't like this lopsidedness, but there's no choice for a real world GPU.
If you're curious, check out the designs of older entry level GPUs, where you'll see that quite often everything is a perfect power of 2, eg data bus, CUDA cores etc, since it's practical to do so at the smaller sizes.
The 970 memory issue came about, because NVIDIA nibbled a bit off the GPU, giving rise to a compartmentalized memory addressing design, where they chose to use slow RAM for that last 500MB, but didn't declare it, leading to this scandal.
When I saw that the 1080 Ti with its weird 11GB RAM and crippled GPU, it brought back to me that NVIDIA could potentially have the same design issue. However, it all really depends on the details of the design whether this happens or not and we'll soon know once the official reviews are out. I doubt they'd repeat the same mistake, especially on their flagship product.
@efikkan back there thinks I'm "completely wrong" about a power of 2 chip being optimal, but I'm not, as I've explained above. He just didn't quite understand what I was saying.
Oh and you asked for it - check my sig! :p
For starters, the memory controllers on GPUs have all power of 2 address space as I've said a number of times already, how hard is this to understand?
But for the hypothetical scenario where 3 out of 4 memory slots i occupied, the memory controller will never check if a memory address is inside the range on read/write, that would be too costly anyway. The whole "problem" is solved on allocation of memory (which is costly anyway, and done very rarely compared to read/write), and the only thing to check then is whether the memory address is above the maximum size, so the problem you describes doesn't exist.
Just to illustrate how wrong you are, I checked two of the machines I'm running here;
i7-3930K, 46-bit controller, 65536 GB (64 TB) theoretical physical address space, but the CPU is "limited" to 64 GB.
i5-4690K, 39-bit controller, 512 GB theoretical physical address space, but the CPU is "limited" to 32 GB.
(This is fetched directly from the CPU's cpuid instruction, so it's what the OS sees and is guaranteed to be correct)Number of bits of what? Data bus? Memory bus? Register width?
If you look at GPU architectures you'll see that most of then don't have a core count which adds up to a power of 2, like 256, 512, 1024, 2048, 4096, etc. Just scroll through here and here, that power of 2 is more the exception than the rule.The term "a perfect power of 2 chip" doesn't make any sense.The GTX 970 "issue" was that two memory chips shared one 32-bit controller, while the others didn't, creating an address space where some of it was slower without the allocator taking this into account. Power of 2 had absolutely nothing to do with it.
If GTX 1080 Ti were to do the same thing it would have to do 12 memory chips on 11 controllers, which we know it doesn't, so we know it can't happen. If you still think it's a problem, then you're having a problem understanding how processors and memory work.Your avatar is cool though.