Friday, March 31st 2017

AMD's RX Vega to Feature 4 GB and 8 GB Memory
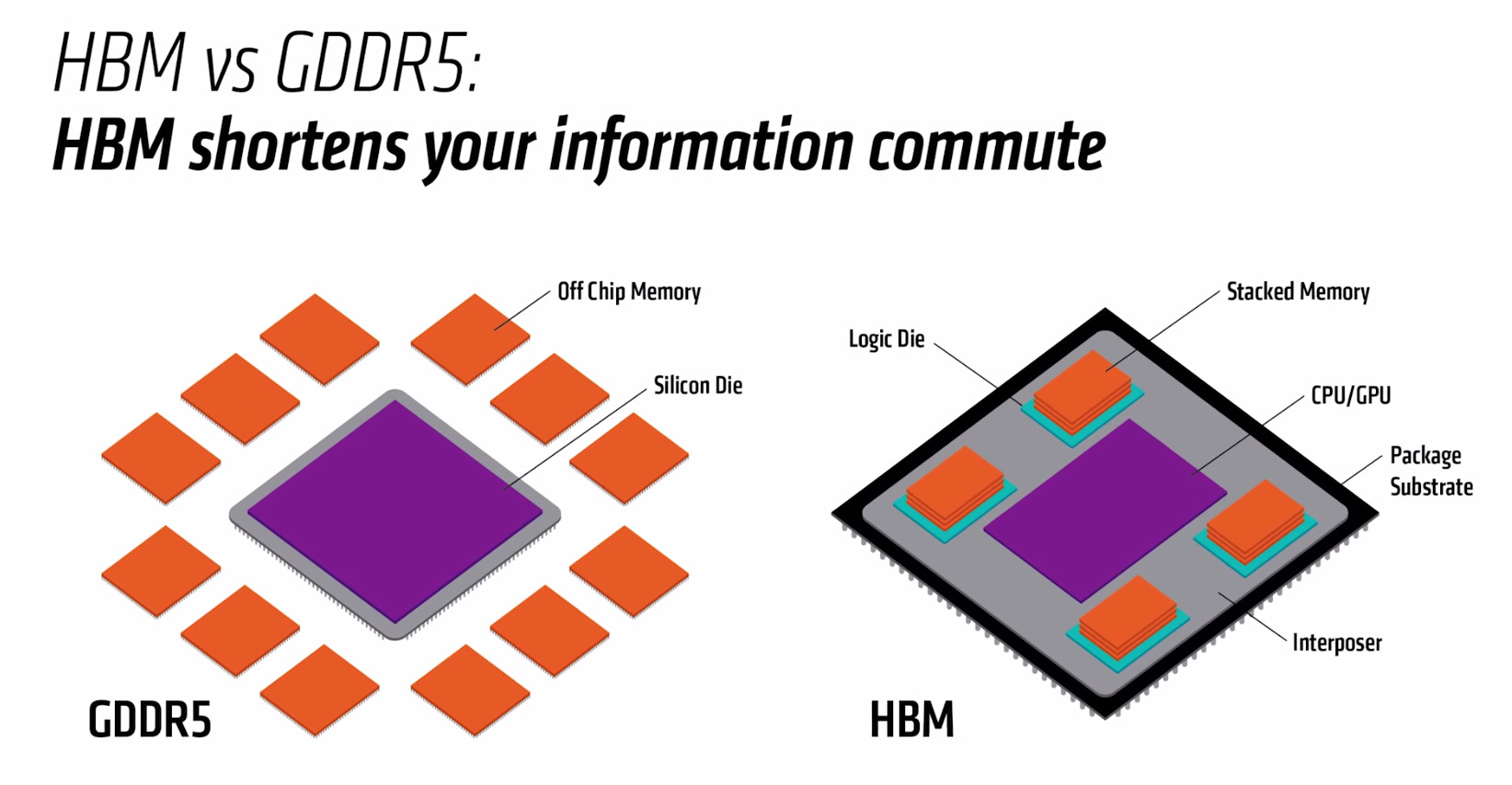
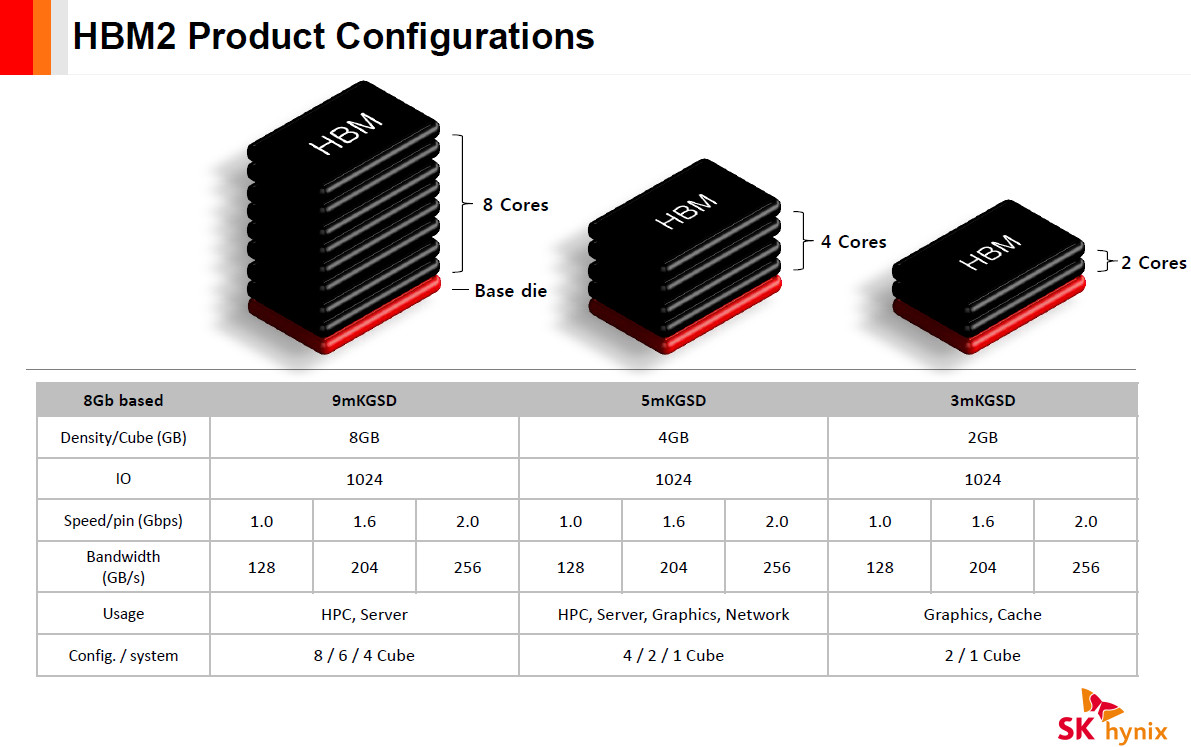
It looks like AMD is confident enough on its HBC (High-Bandwidth Cache) and HBCC (High-Bandwidth Cache Controller) technology, and other assorted improvements to overall Vega memory management, to consider 4 GB as enough memory for high-performance gaming and applications. On a Beijing tech summit, AMD announced that its RX Vega cards (the highest performers in their next generation product stack, which features rebrands of their RX 400 line series of cards to th new RX 500) will come in at 4 GB and 8 GB HBM 2 (512 GB/s) memory amounts. The HBCC looks to ensure that we don't see a repeat of AMD's Fury X video card, which featured first generation HBM (High-Bandwidth memory), at the time limited to 4 GB stacks. But lacking extensive memory management improvements meant that the Fury X sometimes struggled on memory-heavy workloads.
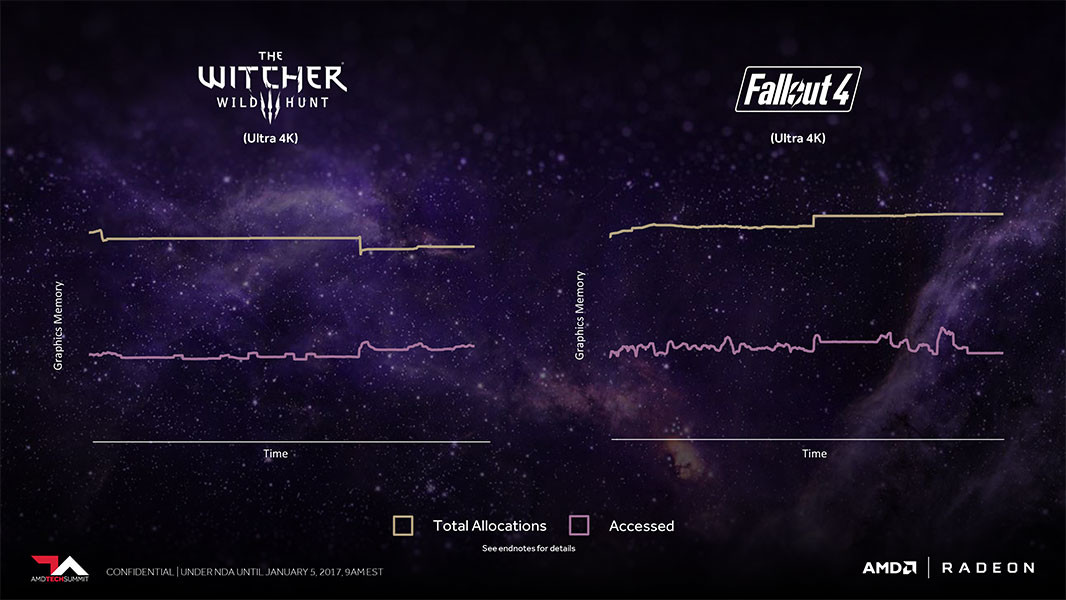
If the company's Vega architecture deep dive is anything to go by, they may be right: remember that AMD put out a graph showing how the memory allocation is almost twice as big as the actual amount of memory used - and its here, with smarter, improved memory management and allocation, that AMD is looking to make do with only 4 GB of video memory (which is still more than enough for most games, mind you). This could be a turn of the screw moment for all that "more is always better" philosophy.

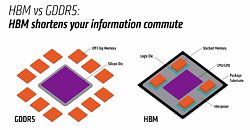

If the company's Vega architecture deep dive is anything to go by, they may be right: remember that AMD put out a graph showing how the memory allocation is almost twice as big as the actual amount of memory used - and its here, with smarter, improved memory management and allocation, that AMD is looking to make do with only 4 GB of video memory (which is still more than enough for most games, mind you). This could be a turn of the screw moment for all that "more is always better" philosophy.

52 Comments on AMD's RX Vega to Feature 4 GB and 8 GB Memory
The reason for huge pools of memory is because of massive textures and models which have sharply been increasing since PS4 and XB1 released. Selling a premium card with budget amounts of memory makes no sense.Developers will do whatever they want to. AMD is banking on them implementing their optimizations to reduce the memory footprint. Very few titles will.
Some games don't use >4 GiB of VRAM but some do and with every passing year, the latter group gets bigger.
Quad channel will still only get you 100 GB/s under the best circumstances which is a far cry from the minimum 512 GB/s of the HBM stacks.
www.tweaktown.com/tweakipedia/90/much-vram-need-1080p-1440p-4k-aa-enabled/index.html
-Streaming engines (Killing Floor is not) use more VRAM in general.
-Streaming engines tend to have more data cached because the player simply turning around in the world can result in wildly different scene that needs to be rendered.
-A small, detailed environment can be more demanding than a not-so-detailed large environment. It boils down to textures, shaders, triangles, and post rendering effects applied (e.g. anti-aliasing).
-Thanks to tessellation, even if you have a lot of models of the same kind of enemy in the game, you can render them repeatedly at little memory cost.
-Texture streaming is not the same as a streaming engine. Texture streaming doesn't precache textures which means there's a frame time spike whenever a new resource needs to be pulled from the memory to the GPU to render the scene. In games where there's literally 10s of gigabytes of textures, it's impossible to precache all of them. Streaming engines naturally have to stream textures as well.
-HBCC literally only reduces the effect of the frame time spike by a few milliseconds. Preemption is far better.
Wrapping back to the link: Witcher 3, Far Cry 4, GTAV, and Shadow of Mordor are streaming engines. Of those, GTAV and Shadow of Mordor both either are at or exceed 4 GiB VRAM at 1920x1080 and climb from there. The other two are surprisingly well optimized likely because they aren't as aggressive at caching.
- Streaming engines use LESS VRAM. That's the whole point of this tech. It loads textures into memory on the fly for the region of the game you're currently in, not whole level at start of the game. Killing Floor 2 most certainly DOES use texture streaming. I made a tweaker for it around this very feature for the game. Original Killing Floor is UE 2.5 game, of course it doesn't have texture streaming.
- See first point.
- Triangles or polygons have absolutely nothing to do with any of it.
- Tessellation has absolutely nothing to do with any of it.
- Texture streaming or streaming engine, same exact thing. Except first streams only textures, second can stream also world objects/entities. Texture streaming does in fact precache textures so they are ready for the engine before it actually needs them. If that was not the case, you'd see world without textures because you wouldn't have them when needed or they'd pop up into existence which is very unwanted behavior. Which is why you have to preemptively fetch them into memory (precache) and make them available to the engine a bit before they are actually needed. All this is happening in the background, all the time. Which is why such games experience stuttering with HDD's, because the game is constantly fetching data and loading it into VRAM, but HDD's do it very slowly. But the gain is, you need way less VRAM, because at any point, you don't have textures of whole level in VRAM, you only have for a small section of level where you're currently located. Textures fill majority of VRAM during rendering. Like 3/4 of VRAM are textures. The rest are model meshes, entities and framebuffer (+other game data).
Triangles are literally everything you see in 3D games. GPUs draw them to create a frame. That's data that lives in the VRAM.
Tessellation is literally about doing more with less, because math. Have a presentation:
www.seas.upenn.edu/~cis565/LECTURE2010/GPU Tessellation.pptxStreaming engines take a location in the world and then load everything it needs based on that. As you move about the world, it has to decide what can be disposed of and what needs to be loaded. That includes everything from collision objects to textures. When you fast travel in a streaming engine, there's always loading as it disposes of your current location and it loads the next location. If there was no loading, you'd literally see nothing and fall endlessly because there's literally nothing there until it has said "I have enough for the player now." Strictly streaming textures is minor compared to a streaming engine.
When streaming anything, there is a degree of precaching. The streaming code tries to preempt what can be seen in that context and attempts to get into the pipeline in case it is needed. If you move about the world faster than the textures can stream (e.g. very slow HDD), you'll either see texture pop in or you'll see loading screens (GTA3 did this way back, GTA4 did it on consoles).
The frame time spikes occur when preemption fails to catch a resource that's needed.
There's games that really don't use much of textures but can still saturate VRAM with polygons and post processing effects.
Prefetching in CPUs works by finding access patterns; e.g. access of block at address x, then x + k, then x + 2k, but it has three requirements:
- The data to be accessed needs to be specifically laid out the way it's going to be accessed.
- There has to be several accesses before there can be a pattern, which means several cache misses, which in turn means stutter or missing resources.
- The patterns have to occur over a relatively short time, and there is no way you can look for patterns in hundreds of thousands of memory accesses. A CPU for comparison looks through a instruction window of up to 224 instructions. For GPUs we have queues of up to several thousands of instructions, and it's not like the driver is going to analyze the queues for several frames to look for patterns and keep a giant table and resolve that immediately.
The only game data that would have benefits from this would be landscape data, but the data still needs to laid out in a specific pattern, which is something developers usually don't control. Also, this kind of caching would only work as long as the camera keeps moving in straight lines over time.
Resource streaming can be very successful when it's implemented properly in the rendering engine itself.FYI: Sharing of memory between CPU and GPU has been available in CUDA for years, so the idea is not new. It does however have very limited use cases.As someone who has implemented texture streaming with a three-level hierarchy, I can tell you the problem is prediction. With HBC each access to RAM is still going to be very slow, so the data has to be prefetched. HBC is not going to make the accesses "better".
At least in theory it sounds quite feasible: "dear developer, we know you don't need all that mem at once, just allocate whatever you need, we'll handle moving things into GPU mem ourselves, oh, and by the way, we don't call it VRAM, we call it high bandwidth cache now".
The basic idea here is that, especially in the professional space, data set size is vastly larger than local storage. So there needs to be a sensible system in place to move that data across various tiers of storage. This may sound like a simple concept, but in fact GPUs do a pretty bad job altogether of handling situations in which a memory request has to go off-package. AMD wants to do a better job here, both in deciding what data needs to actually be on-package, but also in breaking up those requests so that “data management” isn’t just moving around a few very large chunks of data. The latter makes for an especially interesting point, as it could potentially lead to a far more CPU-like process for managing memory, with a focus on pages instead of datasets.
www.anandtech.com/show/11002/the-amd-vega-gpu-architecture-teaser/3