Monday, April 30th 2018

AMD "Vega 20" with 32 GB HBM2 3DMark 11 Score Surfaces
With the latest Radeon Vega Instinct reveal, it's becoming increasingly clear that "Vega 20" is an optical shrink of the "Vega 10" GPU die to the new 7 nm silicon fabrication process, which could significantly lower power-draw, enabling AMD to increase clock-speeds. A prototype graphics card based on "Vega 20," armed with a whopping 32 GB of HBM2 memory, was put through 3DMark 11, on a machine powered by a Ryzen 7 1700 processor, and compared with a Radeon Vega Frontier Edition.
The prototype had lower GPU clock-speeds than the Vega Frontier Edition, at 1.00 GHz, vs. up to 1.60 GHz of the Vega Frontier Edition. Its memory, however, was clocked higher, at 1250 MHz (640 GB/s) vs. 945 MHz (483 GB/s). Despite significantly lower GPU clocks, the supposed "Vega 20" prototype appears to score higher performance clock-for-clock, but loses out on overall performance, in all tests. This could mean "Vega 20" is not just an optical-shrink of "Vega 10," but also benefits from newer architecture features, besides faster memory.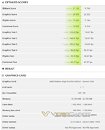
Source:
VideoCardz
The prototype had lower GPU clock-speeds than the Vega Frontier Edition, at 1.00 GHz, vs. up to 1.60 GHz of the Vega Frontier Edition. Its memory, however, was clocked higher, at 1250 MHz (640 GB/s) vs. 945 MHz (483 GB/s). Despite significantly lower GPU clocks, the supposed "Vega 20" prototype appears to score higher performance clock-for-clock, but loses out on overall performance, in all tests. This could mean "Vega 20" is not just an optical-shrink of "Vega 10," but also benefits from newer architecture features, besides faster memory.

77 Comments on AMD "Vega 20" with 32 GB HBM2 3DMark 11 Score Surfaces
That's hardly a reasonable argument.
What matters, however, is that if Vega was bandwidth starved, we could see it in actual tests. Which show it isn't.
"At 1600MHz core the gains from a 16% Memory OC are roughly 4%. Memory starved gains look different."
VEGA 64 has a memory bandwidth of 484GB/s
GTX 1080 Ti has a memory bandwidth of 484GB/s.
VEGA 64 is on a 2048bit bus, with a memory speed of 1890MHz effective.
1080Ti is on a 384bit bus, with an 11,008MHz effective memory speed.
Vega10 has HBCC which adds some latency that was intended to be compensated with massive memory bandwidth which Vega10 did not have. Vega20 finally delievers both.
If you have a GPU like GP104 with a 256-bit GDDR controller, it's really four separate 64-bit, supplying a total of 320 GB/s of theoretical bandwidth, but only when load is spread evenly across them. Each controller can only be used by one cluster at the time, meaning if four clusters are scheduled to read/write from the same memory controller, they have to wait in turn, leaving you with an effective 80 GB/s instead of 320 GB/s.
The reason why Nvidia scales better is they manage their resources much better, while AMD have a much simpler and more brute-force approach throwing much more resources at the problem, resulting in much larger and more power-hungry designs. Simply adding more resources (memory bandwidth, higher clocks, more cores, etc.) is not necessarily going to solve any problems if they are going to manage the extra resources just as poorly. More bandwidth is not going to solve any bottlenecks caused by data dependencies. If AMD threw more memory bandwidth into their design, they might risk decreasing the energy efficiency.
But now it will be with 1250MHz and 1600MHz chips on the way, and Vega 20 will have double the bus too! This more than doubling of bandwidth would easily add 50%+ performance alone (And 7nm should bring at least 20% higher core clocks too).
P.S. To all those who say hilarious things like "INSERT_CARD doesn't need more bandwidth," my Vega 64 gets a flat 12% performance boost simply by only overclocking the HBM to 1125MHz (19% uplift in bandwidth).
do the benchmark we need more vegas on the leaderboard
-faster HBM
-double the bandwidth
-7nm node
-and NO increase in ROP , TMU, or SP count?!
I mean Vega isn't that bandwidth starved to the point that it's ONLY worth increasing the bandwidth by a factor of 2.5! Glofo's 7nm node allows the relative die size of chips to be nearly cut in half! Why not add at least 20% more Compute Units and 50% more ROP's?!
If you are going to increase the bandwidth by 150%, at least make it an RX Vega 80!
There is absolutely no doubt that Vega 64/56 has less issues with its low ROP count than Polaris and Fiji had, but it clearly would at least aid in performance if there were relatively more ROP's. All I suggested was adding 50% more ROP's if they added 20% more CU's (and keep in mind 7nm will allow 20% higher core clocks too).
AMD Radeon RX Vega M
Graphics/Compute: GFX8
Display Core Engine: 11.2
Unified Video Decoder: 6.3
Video Compression Engine: 3.4
REAL Vega
Graphics/Compute: GFX9
Display Core Engine: 12.0
Unified Video Decoder: 7.0
Video Compression Engine: 4.0
Yey, excitement...You were responding to "is memory starved". "Competition isn't, so it isn't either" is by no means a solid argument.
Vega isn't mem starved because tests of Vega itself show so, not because of whatever some other companies out there somewhere do.
We have a test run that may appear slower due to this ES being potentially clocked lower for testing, nothing more, nothing less. ;)
If the clock reported is to be believed, it actually should be faster than the current product at the same clock speed said current product runs at - and it may clock even faster than that.
So yes, I think there is a reason for some excitement. :)
TFLOPS alone is useless without read/write units which is TMUs and ROPS.
Now if you utilize Async compute, FP16, and specifically program for Vega's rasterization engine - It can certainly compete with the Titan Xp very well, especially if you overclock the HBM. However that's really a best case scenario, and if you don't use those extra assets it just treads water above the 1080.
Compute Shader Path uses TMUs read/write functions.
Pixel Shader Path uses ROPs read/write functions.
Vega 64 has GP104 class classic GPU hardware. GP102 has more rasterization and ROPS hardware when compared to Vega 64. Vega GPUs gained ROPS being connected to L2 cache design as per Maxwell/Pascal designs.
Vega 64 has GP102 class FP32 compute hardware.
Both Vega 64 and GP104 has quad rasterization /quad GPC units and 64 ROPS.