Sunday, July 12th 2020

AMD 64-core EPYC "Milan" Based on "Zen 3" Could Ship with 3.00 GHz Clocks
AMD's 3rd generation EPYC line of enterprise processors that leverage the "Zen 3" microarchitecture, could innovate in two directions - towards increasing performance by doing away with the CCX (compute complex) multi-core topology; and taking advantage of a newer/refined 7 nm-class node to increase clock-speeds. Igor's Lab decoded as many as three OPNs of the upcoming 3rd gen EPYC series, including a 64-core/128-thread part that ships with frequency of 3.00 GHz. The top 2nd gen EPYC 64-core part, the 7662, ships with 2.00 GHz base frequency and 3.30 GHz boost; and 225 W TDP. AMD is expected to unveil its "Zen 3" microarchitecture within 2020.
Source:
Igor's Lab
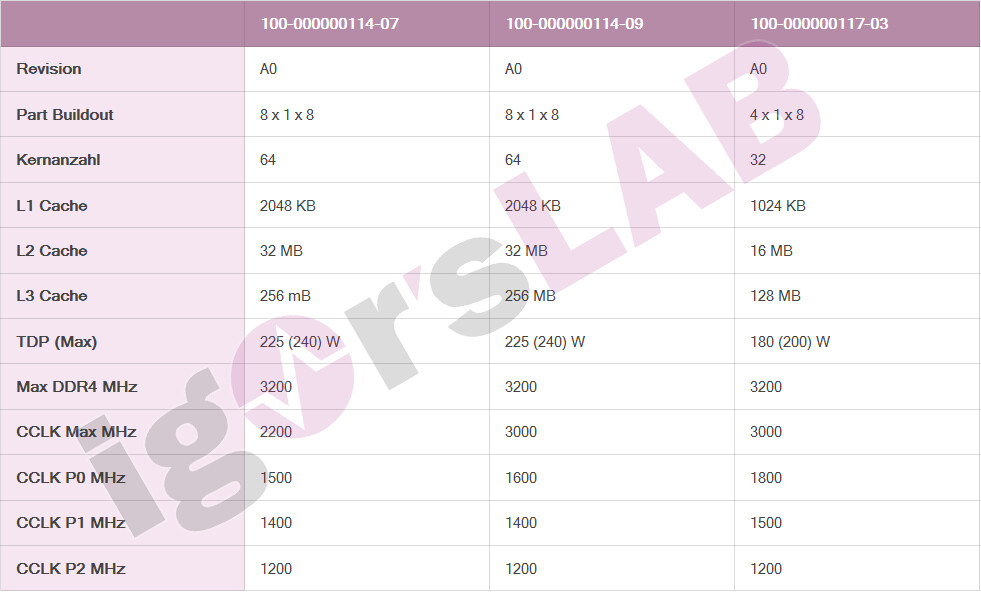
8 Comments on AMD 64-core EPYC "Milan" Based on "Zen 3" Could Ship with 3.00 GHz Clocks
Anyway, Zen 3 it's clearly on it's way to the EPYC line, meanwhile still no Xeon competitor in sight.
This lead to greatly increased latency. If we ignore thermal, frequency and other stuff, a CPU with 2x 4+0 CCD or chiplet will behave the same way as a 4+4 single CCD/chiplet.
A full die is considered a CCD. Since not only you remove the requirement to use the Infinity Fabric but also merge the L3 cache, you end up removing at all the concept of CCX to only keep a 8 core CCD. Altought there, it's more playing with the words. The whole concept of CCX is to split a CCD. if the CCD is no longer split, what is the CCX?
Don't really matter in the end but the good things we will get rid of the inter-core latency between CCX. That is the main thing.
A Shared L3 cache will probably help if the latency isn't too much affected. The problem with bigger cache is the larger it is, the longer it take to perform the cache lookup, hence reducing the latency.
The rumors are that AMD will use a new techology using hash for managing larger cache. We will see.
For workload like Blender render, Cinebench or other highly multithreadable application, the inter-core latency have probably low impact because there isn't much to do anyway. But for things like video game that use a lot of core, it's very probable that there will be significative gains from that change alone.