Friday, July 17th 2020

Linux Performance of AMD Rome vs Intel Cascade Lake, 1 Year On
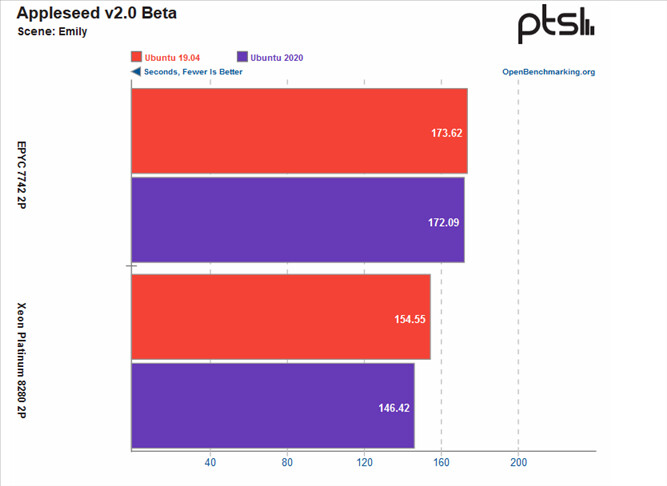
Michael Larabel over at Phoronix posted an extremely comprehensive analysis on the performance differential between AMD's Rome-based EPYC and Intel's Cascade Lake Xeons one-year after release. The battery of tests, comprising more than 116 benchmark results, pits a Xeon Platinum 8280 2P system against an EPYC 7742 2P one. The tests were conducted pitting performance of both systems while running benchmarks under the Ubuntu 19.04 release, which was chosen as the "one year ago" baseline, against the newer Linux software stack (Ubuntu 20.10 daily + GCC 10 + Linux 5.8).
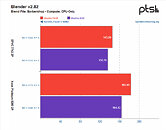
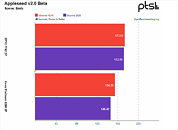
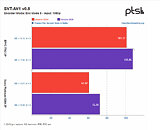
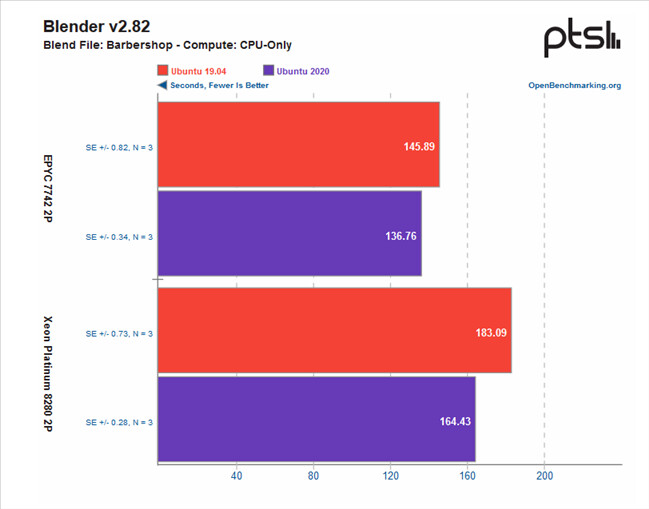
The benchmark conclusions are interesting. For one, Intel gained more ground than AMD over the course of the year, with the Xeon platform gaining 6% performance across releases, while AMD's EPYC gained just 4% over the same period of time. This means that AMD's system is still an average of 14% faster across all tests than the Intel platform, however, which speaks to AMD's silicon superiority. Check some benchmark results below, but follow the source link for the full rundown.
Source:
Phoronix
The benchmark conclusions are interesting. For one, Intel gained more ground than AMD over the course of the year, with the Xeon platform gaining 6% performance across releases, while AMD's EPYC gained just 4% over the same period of time. This means that AMD's system is still an average of 14% faster across all tests than the Intel platform, however, which speaks to AMD's silicon superiority. Check some benchmark results below, but follow the source link for the full rundown.


33 Comments on Linux Performance of AMD Rome vs Intel Cascade Lake, 1 Year On
AVX is like having a tiny "GPU" with practically zero overhead and mixed with other instructions across the execution ports, while an actual GPU is a separate processor that cost you thousands of clock cycles to talk with and have its own memory system. Skipping between the CPU and the GPU every other instruction is never going to be possible, even if the GPU was on-die, there will always be a threshold about work size before it's worth sending something to the GPU. This should be obvious for those who have developed with this technology.
AVX and GPUs are both SIMD, but SIMD at different scales solving different problems.