Friday, July 17th 2020

Linux Performance of AMD Rome vs Intel Cascade Lake, 1 Year On
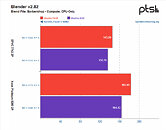
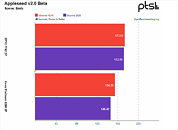
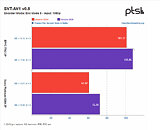
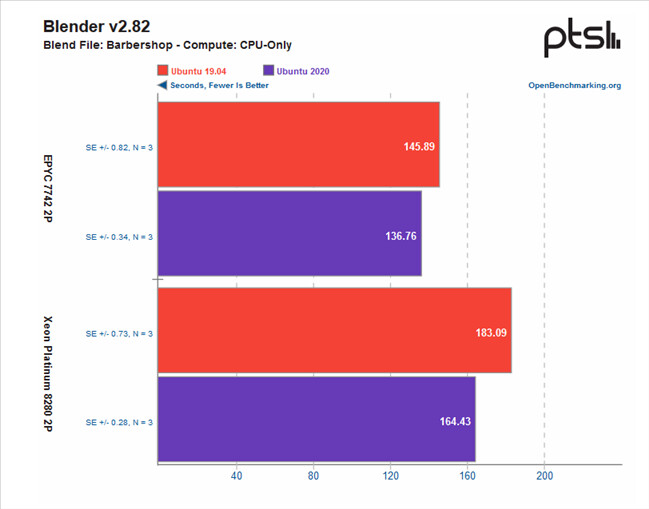
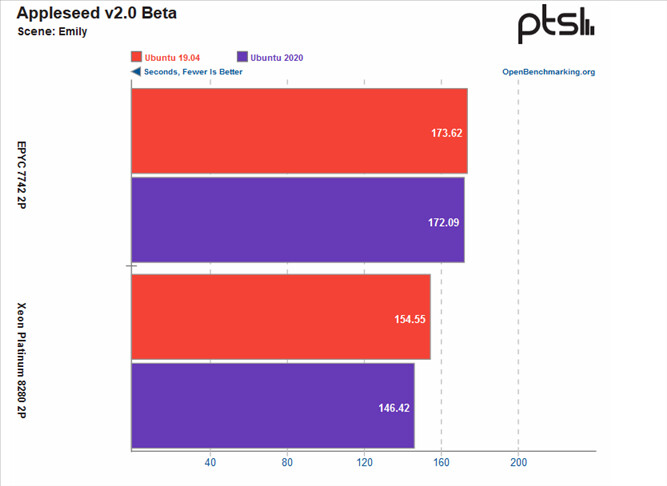
Michael Larabel over at Phoronix posted an extremely comprehensive analysis on the performance differential between AMD's Rome-based EPYC and Intel's Cascade Lake Xeons one-year after release. The battery of tests, comprising more than 116 benchmark results, pits a Xeon Platinum 8280 2P system against an EPYC 7742 2P one. The tests were conducted pitting performance of both systems while running benchmarks under the Ubuntu 19.04 release, which was chosen as the "one year ago" baseline, against the newer Linux software stack (Ubuntu 20.10 daily + GCC 10 + Linux 5.8).
The benchmark conclusions are interesting. For one, Intel gained more ground than AMD over the course of the year, with the Xeon platform gaining 6% performance across releases, while AMD's EPYC gained just 4% over the same period of time. This means that AMD's system is still an average of 14% faster across all tests than the Intel platform, however, which speaks to AMD's silicon superiority. Check some benchmark results below, but follow the source link for the full rundown.
Source:
Phoronix
The benchmark conclusions are interesting. For one, Intel gained more ground than AMD over the course of the year, with the Xeon platform gaining 6% performance across releases, while AMD's EPYC gained just 4% over the same period of time. This means that AMD's system is still an average of 14% faster across all tests than the Intel platform, however, which speaks to AMD's silicon superiority. Check some benchmark results below, but follow the source link for the full rundown.


33 Comments on Linux Performance of AMD Rome vs Intel Cascade Lake, 1 Year On
Intels marketing and intel-tame software/hardware companies try to fool people wich don´t have their glasses as clean as they should.
Phoronix Michael Larabel does a great job everytime going as real as possible with benchmarks.
Take a look at the horrendously fragmented list of products supporting scattered bits and pieces of AVX-512 and you'll see why it's not even remotely worth AMD's time right now.
And it takes 18 seconds to compile using 8 threads on 3700X (stock)
Now thats what i call a productive CPU
And it takes 25 minutes to compile using 2 threads on Allwiner A20 ARM cpu lol
LE: Now I see it. The tests are a mix of ST and lightly/hard MT scenarios. In any case, with very well MT software you'll see bigger difference, but I guess given these are the current workloads in the server space, Intel is not that far off.
Pretty much all software today is compiled with eiter GCC, LLVM or MSVC, neither are biased.
Of all the compiler optimization that GCC and LLVM offers, most of them are generic. There are a few exceptions, like if you target Zen 2 vs. Skylake, but those are minimal and the majority of optimizations are all the same.
We can't optimize for the underlying microarchitectures, as the CPUs share a common ISA. The CPUs from Intel and AMD also behave very similarly, so in order to optimize significantly for either one, we need some significant ISA differences. As of right now, Skylake and Zen 2 is very comparable in ISA features (while Skylake-X and Ice Lake have some new features like AVX-512 and a few other instructions). So when the ISA and general behavior is the same, the possibility of targeted optimizations to favor one of them is pretty much non-existent. So whenever you hear people claim games are "Skylake optimized" etc., that's 100% BS, they have no idea what they're talking about.You are clearly way off base here.
The core functionality of AVX-512 is known as AVX-512F, the others are optional extensions.
The various "AI" features are marketed as AVX-512 because they use the AVX-512 vector units, unlike other single instructions running through the integer units.
As an additional note;
I'm not a fan of application specific instructions. Those never get widespread use, and quickly become obsolete, and software relying on these are no longer forward-compatible.
You run virtualized, docker, yeah..
AMD had the HSA stuff, but it never got adopted with the APUs.
AVX, multithreading and GPU acceleration are all different types of parallelism, but they work on different scopes.
- AVX works mixed in with other instructions, and have a negligible overhead cost. AVX is primarily parallelization on data level, not logic level, which means repeated logic can be eliminated. One AVX operation costs the same as a single FP operation, so with AVX-512 you can do 16 32-bit floats at the same cost of a single float. And the only "cost" is the normal transfer between CPU registers. So this is parallelization on the finest level, typically a few lines of code or inside a loop.
- Multithreading is on a coarser level than AVX. When using multiple threads, there are much higher synchronization costs, ranging from sending simple signals to sending larger pieces of data. Also data hazards can very quickly lead to stalls and inefficiency, so for this reason the proper way to scale with threads is to divide the workload into independent work chunks given to each worker threads. Multiple threads also have to deal with the OS scheduler which can cause latencies of several ms. Work chunks for threads are generally ranging from ms to seconds, while AVX works in the nanosecond range.
- GPU acceleration have even larger synchronization costs than multithreading, but the GPU has also more computational power, so if the balance is right, GPU acceleration makes sense. The GPU is very good at computational density, while current GPUs still relies on the CPU to control the workflow on a higher level.
It's worth mentioning that many productive applications use two or all three types of parallelization, as they complement each other.But when it comes to "AI" for supercomputers, this will soon be accelerated by ASICs. I see no reason why general purpose CPUs should include such features.
www.extremetech.com/computing/312673-linus-torvalds-i-hope-avx512-dies-a-painful-death
- AVX-512 support is fragmented. Which it is and he sounds like he would be OK with this part if all (or at least all Intel) CPUs would have it.
- He dislikes FP in general. This may or may not be a reasonable stance.
And AVX can do integer too, which is why I often refer to them as vector units, since they can do both integers and floats. Integers in AVX is used heavily in things like file compression.